
Привет!
Про платформы виртуализации и гипервизоры у нас много статей, но вот про программно-определяемые хранилища (Software-Defined Storage, SDS) материалов немного.
Итак, пора исправлять это дело, сегодня расскажу про два разных продукта и подхода — дорогой корпоративный VMware vSAN (закрытое решение, встроенное в vSphere, нынче развивается под крылом Broadcom) и открытый Ceph на лицензии LGPLv2.1 (ядро открыто и бесплатно, но у разработчиков можно купить поддержку).
Обе платформы хранения при грамотном развёртывании на правильном железе, подобранном под задачу, показывают отличную производительность, отказоустойчивость и масштабируемость. Но они сильно различаются в архитектуре, особенностях эксплуатации и экономике. А значит неплохо бы столкнуть их виртуальными лбами.
Так как информации очень много, я разбил этот лонгрид на 2 части:
-
Обзор Ceph и VMware vSAN, лицензирование и актуальные на 2026 год версии.
-
Архитектуры, подбор железа, развёртывание, администрирование, TCO т.д.
Это самые подробные статьи-сравнения про Ceph и vSAN в Рунете! Так что чайничек листового лишним не будет — и в закладки добавляйте (Ctrl + D).
Ремарка! Материал технически непростой — он рассчитан на людей с опытом в IT: сисадминов, технических директоров, IT-архитекторов и т.д. По возможности я буду оставлять ссылки на терминологию, которая у неподготовленного читателя будет вызывать вопросы, но давать определение каждому термину в рамках статьи я не стану, чтобы не раздувать объём и без того немаленького лонгрида. Поэтому, если вы новичок, запаситесь терпением и готовьтесь самостоятельно изучать теорию по ходу чтения.
vSAN — обзор корпоративной годзиллы и как изменились лицензии
vSAN (Virtual SAN, Virtual Storage Area Network) — программно-определяемое хранилище (SDS), встроенное в стек виртуализации VMware vSphere (при этом vSAN — необязательная часть vSphere). Это не отдельная аппаратная СХД и не внешнее хранилище, а механизм, который активируется на уровне кластера ESXi и превращает локальные накопители серверов в единое распределённое хранилище данных. По сути, вычисления и хранение объединяются в гиперконвергентную инфраструктуру (единую программно-определяемую систему): добавляете узел — одновременно растёт и объём ресурсов CPU/RAM, и дисковая ёмкость.
То есть главная идея и преимущество — не надо покупать отдельные СХД, достаточно накопителей в ваших серверах.
Ремарка про SDS! На различных форумах админов и площадках, вроде Хабра, вы можете встретить термин RAIN (Redundant Array of Independent Nodes) вместо SDS. Не знаю цели авторов (возможно, показать широкий кругозор), но это технически неточно. SDS — это концепция организации хранилища, а RAIN — архитектурный принцип построения отказоустойчивых систем.
Проведу аналогию. SDS — это легковой автомобиль, а RAIN — это один из его элементов, например, четыре колеса. И vSAN, и Ceph — это разные модели таких автомобилей, которые, безусловно, ездят на четырех колесах (построены по принципу RAIN), но правильнее называть их именно автомобилями (SDS).
Минимальная конфигурация собирается из двух нод/узлов — что обычное дело для небольших офисов и филиалов с отдельным узлом-свидетелем aka witness-узлом. Однако для полноценной отказоустойчивости разворачивают кластер из трёх и более нод (для гибридного массива рекомендую минимум 4 сервера, каждый из которых будет свидетелем для других).

Не баян, а классика (для ньюфагов: свидетель — в трениках).
В кластере данные виртуальных машин (ВМ) распределяются между серверами согласно политике хранения: можно задать количество реплик, включить erasure coding (стирающий код — помехоустойчивый код, который может восстанавливать целые пакеты данных в случае их потери), определить требования к производительности. За счёт этого достигается высокая доступность (High Availability, HA) — при отказе одного узла (или нескольких — зависит от кластера) виртуальные машины продолжают работать.
Однако vSAN требует аккуратного проектирования и развёртывания, подбора комплектующих из HCL (список совместимого железа), плюс нужно учитывать последние изменения с лицензированием (изменений много, а хороших новостей для вас у меня мало).
Историческая справка! В декабре 2023 года Broadcom закрыла одну из крупнейших в истории IT сделку по покупке VMware за 69 млрд долларов. Все продукты VMware стали частью экосистемы Broadcom, компания ушла с биржи, но не из дата-центров.
Ключевое изменение — каталог из 168 продуктов перевели на 4 пакета и отказались от бессрочных лицензий (perpetual license). Теперь всё на наших любимых подписках — доступ к продуктам оформляют на 1, 3 и 5 лет. Раньше можно было один раз купить лицензию и использовать её сколько техдиру угодно, оплачивая поддержку отдельно.
Для многих это сделало и без того недешевые продукты VMware недоступными.
Раньше цена на вечную лицензию vSAN зависела от количества CPU в них (или входила в бандлы HCI Kit, которые объединяли vSAN и vSphere одном SKU). Надо было выбрать редакцию под свою задачу (Standard, Advanced, Enterprise, Enterprise Plus Pro Max), купить её один раз и забыть — это было просто и понятно. Особенно, если платная поддержка не нужна была.
Перечислю, какие редакции VMware vSAN были в версии 8:
-
vSAN Standard — базовая редакция для гибридных и all-flash конфигураций. Даёт программно-определяемое хранилище с управлением через политики на уровне виртуальных машин (Storage Policy Based Management). Подходит для типовой виртуализации, где важны предсказуемость и централизованное управление без избыточных функций.
-
vSAN Advanced — включает всё из Standard и добавляет механизмы экономии ёмкости для all-flash конфигураций: дедупликацию, сжатие и Erasure Coding. Эти технологии позволяют сильно снизить требования к физическому объёму дисков без потери производительности. Оптимальный вариант для сред с высокой плотностью ВМ и большими массивами однотипных данных.
-
vSAN Enterprise — расширяет возможности Advanced за счёт программного шифрования данных на хранении (data-at-rest encryption) и поддержки распределённых кластеров (stretched cluster). Это уже уровень инфраструктуры с повышенными требованиями к отказоустойчивости и безопасности — например, при размещении узлов на двух площадках.
-
vSAN Enterprise Plus — максимальная редакция. Помимо всего вышеперечисленного, добавляет расширенные инструменты управления и оптимизации производительности, более гибкую работу с ресурсами и дополнительные функции для крупных, распределённых сред. Выбор для сложных корпоративных инфраструктур и провайдерских сценариев.
Отдельно существовали специализированные варианты лицензирования:
-
vSAN for ROBO (Remote Office / Branch Office) — предназначен для филиалов и удалённых площадок. Лицензируется пакетами на 25 виртуальных машин. Доступны редакции Standard, Advanced и Enterprise. Удобен, когда нужно централизованно управлять десятками небольших площадок.
-
vSAN for Desktop — ориентирован на VDI-сценарии. Лицензируется пакетами по 10 или 100 виртуальных десктопов. Также доступны редакции Standard, Advanced и Enterprise. Подходит для инфраструктуры виртуальных рабочих мест с предсказуемой моделью масштабирования.
Таблица с различиями по функционалу:
|
Компоненты продукта |
Standard |
Advanced |
Enterprise |
Enterprise Plus |
|
Storage Policy Based Mgmt |
V |
V |
V |
V |
|
Virtual Distributed Switch |
V |
V |
V |
V |
|
Rack Awareness |
V |
V |
V |
V |
|
Software Checksum |
V |
V |
V |
V |
|
All-Flash Hardware |
V |
V |
V |
V |
|
iSCSI Target Service |
V |
V |
V |
V |
|
QoS - IOPS Limit |
V |
V |
V |
V |
|
Cloud Native Storage (CNS) Control Plane |
V |
V |
V |
V |
|
vSphere Container Storage Interface (CSI) Driver |
V |
V |
V |
V |
|
Shared Witness |
V |
V |
V |
V |
|
Deduplication & Compression |
|
V |
V |
V |
|
RAID-5/6 Erasure Coding |
|
V |
V |
V |
|
vSAN Insights by vROps |
|
V |
V |
V |
|
Data-at-Rest and Data-In-Transit |
|
|
V |
V |
|
Stretched Cluster with Local Failure |
|
|
V |
V |
|
File Services |
|
|
V |
V |
|
HCI Mesh |
|
|
V |
V |
|
Data Persistence Platform for Modern Stateful Services |
|
|
V |
V |
|
vRealize Operations 8 Advanced |
|
|
|
V |
Лицензирование vSphere и vSAN в 2026 году
Но теперь, после того как Broadcom поглотила VMware, vSphere стал распространяться по подписной модели с лицензированием по ядрам CPU (минимум 16 ядер на процессор).
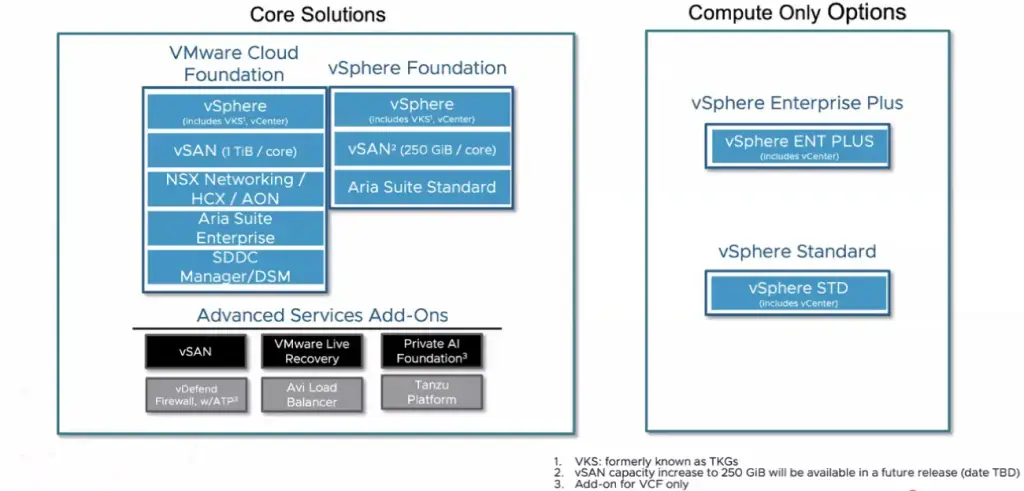
На выбор 4 пакета + допы (аддоны):
-
VMware Cloud Foundation (VCF) — для среднего бизнеса;
-
vSphere Foundation (VVF) — для крупняков и ЦОДов;
-
vSphere Standard (VVS) — для виртуализации серверов;
-
vSphere Enterprise Plus (VSEP) — платформа с расширениями (DRS, HA, Fault Tolerance, Storage vMotion), она заменила vSphere Essentials Plus (VVEP) из-за низкого спроса;
-
Дополнительные расширения: vSAN, VMware Live Recovery, Private AI Foundation, межсетевой экран vDefend с ATP, балансировщик нагрузки Avi, платформа Tanzu.
А vSAN теперь лицензируется на основе гибибайтовой (ГиБ/GiB) или тебибайтовой тарификации (ТиБ/TiB) через дополнительную подписку, а не по процессору.
Ремарка! ТиБ aka Тебибайт (1024 в степени 4 байт) — больше терабайта (1000 в 4 степени байт) на 99 511 627 776 байт (более чем на 99 гигабайт или 92 гибибайт), и, соответственно, на 9,95%.
Если, к примеру, у вас vSphere Foundation с включёнными 250 ГиБ на ядро и вам нужно больше, придётся купить подписку vSAN Add-on на дополнительную ёмкость, но лицензирование начинается с нуля, а не с добавляемой разницы. То есть нельзя просто оплатить разницу. Для расширения нужно оформить подписку vSAN, покрывающую весь объём в ТиБ. Для VCF, например, включено 1 ТиБ на ядро; всё, что сверх этого, также лицензируется через vSAN Add-on и считается с 0.
И если вы ещё не расстроились, то уточню, что все эти платные расширения по подписке относятся только к хранилищу vSAN. Для всех других задач нужны отдельные расширения с подпиской — например, для резервного копирования (VMware Live Recovery) или для безопасности (vDefend firewall).
ВАЖНО! VMware рекомендует тем, кто перешел с vSphere Enterprise Plus и vSAN Advanced, перейти на vSphere Foundation, поскольку в него уже встроена некоторая емкость vSAN (0,25 ТиБ/ядро). Если этой ёмкости (которая масштабируется в зависимости от количества ядер) недостаточно для вашего кластера, можно добавить аддон vSAN. Отмечу, что объём в пакете привязан к этой лицензии — например, 250 ГиБ на ядро, включенные в VVF, привязаны к этим ядрам и не могут быть распределены между отдельными средами. Так что если у вас несколько кластеров, то лицензии vSphere Foundation для каждого кластера включают собственный объём vSAN.
В общем, порог входа вырос титанически, а стоимость кластера может кратно меняться от количества ядер, объёма информации и нужного функционала. И ещё — технические требования к оборудованию всё ещё очень строгие (списки совместимого железа HCL никуда не делись), а сервисы vSAN потребляют часть ресурсов хоста, поскольку работают на уровне гипервизора и добавляют уровень абстракции.
Но здесь важное уточнение (и заодно ключевое отличие от Ceph): строгий HCL, проверки совместимости и ограничения по функционалу — это не столько контроль Большого Брата за вами, сколько защита от необдуманных архитектурных решений. Например, vSAN просто не позволит включить дедупликацию или шифрование без all-flash-конфигурации. Не получится наколхозить гибридный массив, активировать продвинутые функции и надеяться, что оно как-то заработает. Платформа сама ограничивает потенциально опасные сценарии. По сути, vSAN во многом страхует администратора от выстрела себе в ногу.
Подытожу: vSAN не дешёвая замена СХД — и никогда ей не был. Это инструмент построения корпоративной HCI-инфраструктуры. Надёжный, производительный, с хорошей поддержкой. Он отлично подходит для сред с большим количеством виртуальных машин, VDI, филиалов и частных облаков. Но при огромных объёмах хранения и/или специфических нагрузках классическая внешняя СХД и по производительности будет лучше и по финансам, вероятно, тоже.
Ceph — краткий обзор кальмаров и рифов

Ceph — распределённая программно-определяемая система хранения с открытым исходным кодом. Проект запустил Сейдж Уайл в 2006 году, позже он стал частью экосистемы Red Hat.
В основе Ceph лежит RADOS — объектный слой, который автоматически распределяет данные по кластеру с помощью алгоритма CRUSH, без централизованной таблицы размещения блоков. Это позволяет системе масштабироваться горизонтально и практически линейно — от нескольких серверов до сотен и тысяч узлов.
Поверх RADOS доступны блочное хранилище RBD (RADOS Block Device), внутренняя файловая система CephFS и объектный доступ через S3-совместимый шлюз. Благодаря этому Ceph можно использовать одновременно под виртуальные машины, контейнеры и архивные данные. Он широко применяется в облачных средах на базе OpenStack, в виртуализации, например с Proxmox VE, а также в Kubernetes-кластерах через CSI-драйверы.
Да, в отличие от vSAN, Ceph не привязан к конкретному гипервизору — платформа спокойно работает с OpenStack, Proxmox VE, Kubernetes и любыми средами, где нужен блочный, файловый или объектный доступ.
Сильные стороны Ceph — гибкость, независимость от вендора и условная бесплатность. Но с оговоркой — сам софт бесплатный, лицензий по ядрам или ТиБ нет, но инфраструктура под него требует грамотного сайзинга (подбора оптимальной конфигурации аппаратного обеспечения), быстрой и стабильной сети (обычно 10–25 Гбит/c и выше) и продуманной топологии размещения узлов. Вам же не нужны постоянные задержки, ребалансировки, и восстановление по ночам?
Производительность и стабильность Ceph сильно зависят от правильного подбора накопителей (NVMe под DB/WAL даёт кратный прирост) и баланса CPU/RAM, а также понимания того, что в кластере считается точкой отказа.
Минимальный кластер (нормальный) — это три монитора (кворум — 2 монитора из 3, если один монитор выйдет из строя, два продолжат работу, управляемость кластера не нарушится) и несколько OSD.
Ремарка!
OSD — это процесс (демон), который обычно привязан к одному физическому диску (HDD, SSD или NVMe) на сервере. Его задача — хранить данные, обслуживать запросы на чтение/запись от клиентов и участвовать в репликации и восстановлении данных вместе с другими OSD. Ceph исходит из того, что диск/OSD может умереть в любой момент, поэтому всё строится вокруг автоматического перераспределения данных. OSD участвует в CRUSH-алгоритме размещения данных, при этом данные не лежат где попало, а распределяются детерминировано.
Монитор (Monitor, ceph-mon) — это что-то вроде диспетчерской кластера Ceph. В отличие от OSD, которые хранят данные, мониторы хранят карту кластера (cluster map — OSD map, MON map, MDS map и др.), состояние кластера и информацию о членстве и аутентификации (CephX). Мониторы не участвуют в операциях чтения/записи данных.
Кворум — это большинство (N/2 + 1) и принцип, при котором мониторы используют протокол консенсуса Паксоса. При трёх мониторах кворум — это два. Если один узел с монитором выходит из строя, два оставшихся продолжают поддерживать согласованное состояние. Если кворума нет (потеря большинства мониторов) — кластер не сможет менять состояние (например, добавлять OSD), но уже существующие I/O операции продолжат работать, если OSD доступны.
Да, можно собрать кластер и меньше, но продакшен начинается с трёх–пяти узлов. Отказоустойчивость достигается либо репликацией (обычно три копии), либо erasure coding. Первый вариант проще и надёжнее, второй — экономит хранилище, но требует больше ресурсов CPU и аккуратной настройки.
Какую версию Ceph выбрать в 2026 году для прода

В продакшене массово используют ветку Reef (18.x) — это стабильная база с доработанным BlueStore (бэкенд объектного хранилища для Ceph) и более предсказуемым механизмом восстановления реплик данных после сбоя OSD или целого узла (recovery). Reef наконец-то довёл поведение BlueStore до предсказуемого состояния под высокой нагрузкой.
В ранних версиях (Luminous, Octopus) BlueStore выдавал сюрпризы, например, метаданные самого Ceph начинали неконтролируемо расти и съедать дисковое пространство. Разработчики починили алгоритмы сжатия и управления логами во внутренней файловой системе (BlueFS): теперь база RocksDB сама следит за размером своего журнала и вовремя его урезает, не доводя до критического состояния.
Была и проблема фрагментации из-за алгоритма распределения свободного пространства. Старый гибридный аллокатор пытался размещать новые данные рядом с предыдущими, что со временем превращало свободное место в кучу маленьких кластеров (проблема лоскутного одеяла). В новых версиях Reef по умолчанию использует hybrid_btree2, который лучше контролирует фрагментацию, однако полностью проблему не устраняет — при долгой работе фрагментация всё равно накапливается.

В 2024 году вышел первый стабильный репозиторий Ceph Squid (v19.2.0), а летом 2025 года — v19.2.3 с исправлениями ошибок.
В Squid серьёзно улучшили fast-diff, object-map, оптимизацию под NVMe, tail latency, занялись работой RBD с deep-flatten и задержками RBD (ответы на запросы БД и VDI, где каждая миллисекунда важна), подтянули multi-site для объектного доступа (репликация между независимыми зонами) и довели до ума cephadm (современный инструмент управления кластером, который заменил устаревший ceph-deploy — работает он через контейнеры и оркестрацию).
Многие уже тестируют Squid, а провайдеры даже в продакшене на новых кластерах, но осторожные админы и архитекторы пока держатся Reef — миграции в спешке для крупных действующих кластеров ни к чему хорошему не приводят, поэтому лучше подождать полгода-год, пока детские болезни не исправят.
Как я написал выше — классический ceph-deploy фактически ушёл в историю. Сейчас стандарт — cephadm и контейнеризация демонов. Развёртывание стало проще, а обновления — аккуратнее, но это не значит, что с Ceph вы получите готовое облако по клику: топология сети, CRUSH-правила и расчёт доменов отказа — непростые задачки даже для опытных IT-архитекторов. И контейнеризация не отменяет необходимости правильно проектировать сеть (25/40/100 Гбист/c для серьёзных нагрузок).
Если vSAN — это готовая собранная машина, то Ceph — это конструктор у вас в гараже (с хорошими инструментами и запчастями). Вы сами собираете архитектуру, сами решаете, где будут домены отказа (fault domain), как разделить диски, как рассчитать ёмкость под репликацию или erasure coding. Гибкость максимальная, но и ответственность — тоже.
ВАЖНО! Ceph почти ничего вам не запрещает — это ключевое отличие от vSAN. Платформа даёт практически полную свободу. Можно комбинировать разные типы накопителей, настраивать собственные CRUSH-правила, выбирать параметры репликации или erasure coding без жёстких ограничений со стороны системы.
Ceph не ограничивает администратора архитектурными рамками — и именно поэтому требует глубокого понимания того, как устроены домены отказа, балансировка нагрузки, размещение журналов DB/WAL и сетевые потоки.
Ошибки здесь не блокируются автоматически, а проявляются в эксплуатации: рост задержек, нестабильные механизмы восстановления, неравномерное распределение данных. Поэтому команда специалистов и качество проектирования Ceph критически важны — не только на этапе запуска, но и на всём жизненном цикле кластера.
Зато после изменений в лицензировании у VMware многие компании смотрят в сторону открытых платформ. И вот тут бесплатный Ceph выигрывает — никаких тебе лицензий по ядрам и подписок за каждый ТиБ. Разве что коммерческая поддержка от Red Hat, SUSE и других.
Подытожу. Ceph — мощный инструмент для средних и крупных инфраструктур, где важны гипермасштабируемость и универсальность (можно масштабироваться от десятков до тысяч ODS). Он отлично чувствует себя в частных облаках, у провайдеров, в средах с большим количеством виртуальных машин и контейнеров, в S3-репозиториях для бэкапов.
Ceph подходит, когда нужно строить инфраструктуру без жёсткой привязки к конкретному вендору и стеку виртуализации, с ним можно объединять блочное (RBD), файловое (CephFS) и объектное (RGW) хранилище в одной платформе.
Для небольших инсталляций Ceph, пожалуй, сложноват (так как эксплуатация Ceph требует серьёзных компетенций — это целый инженерный проект), но в инфраструктурах покрупнее раскрывается отлично.
Переходите во вторую часть лонгрида — про архитектуру, подбор железа, развёртывание, администрирование, TCO и многое другое
Ceph и vSAN — крайне функциональные и зрелые SDS-решения, но они созданы для разных бизнесов.
Ceph – это платформа с открытым исходным кодом и платной поддержкой (если требуется), она отлично подходит для сложных масштабных проектов и инфраструктур без привязки к конкретным стекам виртуализации, гипервизорам и железу. Для работы с Ceph нужны компетенции и время.
vSAN — гиперконвергентное решение под ключ, платное — от и до (особенно после поглощения Broadcom), дорогое, привязанное к экосистеме VMware, зато проще в развёртывании и пользовании.
Чтобы выбрать между ними, нужно учесть… — про это я подробно расскажу во второй части статьи :)
А в Сервер Молл вы можете выбрать серверное оборудование для vSAN, Ceph и любой другой SDS — под задачу и бюджет.
У нас бесплатная доставка по всей России, гарантия до 5 лет с выездом инженера, неограниченные консультации с персональным менеджером и КП за час. Пишите в чат на сайте или звоните!
А в комментариях ниже оставляйте отзывы или вопросы по статье — я всё читаю и на всё отвечаю :)





Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение