
Привет!
Каждый год в последнюю пятницу июля мы (да-да, именно мы — админы) вспоминаем, кто держит на плечах серверы, свитчи, телефонию, принтеры и Wi-Fi в кабинете гендира. А главное — кто первым слышит великое и ужасное «у нас ничего не работает». В этот день (в 2025 году он выпал на 25 июля) мы отметили праздник — День системного администратора. С чем команда Сервер Молла и поздравляет всех причастных :)
Ну а поскольку вы в нашем блоге, то под такой повод мы подготовили полезный лонгрид о важнейших метриках IT-инфраструктуры, за которыми админы приглядывают.
Статья рассчитана на опытных админов (даже если не узнаете нового, освежить память всегда полезно). В конце будет чек-лист, который можно распечатать и повесить в серверной :)
Заваривайте дошираки, наливайте чего-нибудь с кофеином — и начнём.
Как живётся сисадминам в 2025 году
А отлично им живётся. IT-инфраструктура — всё ещё сердце бизнеса. Облака, виртуализация, контейнеры, Kubernetes, CI/CD и т.п. работают на серверах. Сисадмин превратился из «парня, который чинит принтер» в стратега, от которого зависит uptime и безопасность компании. В 2025 году много нового (и не всегда хорошего): ИИ всё активнее помогает в мониторинге и реагировании на сбои — появляется даже модная аббревиатура AIOps (когда рутину вроде алертов, логов и инцидентов разбирают нейросети), edge computing (вычисления на периферии) расползается по IoT-устройствам, а киберугрозы становятся всё изощрённее. UPD: недавно новость прогремела, что хакеры сломали взломали внутреннюю IT‑инфраструктуру «Аэрофлота». А гендир там, вроде как, пароль с 2003 не менял, и на Windows XP работал.
Но как бы там технологии не менялись, основа работы сисадмина остаётся прежней: постоянно следить за здоровьем инфраструктуры, искать слабые места и предугадывать проблемы, а также тушить пожары (хорошо, если в переносном смысле, но бывает и в прямом) до того, как они обрушат кровлю IT-инфраструктуры.
Итак, пройдёмся по ключевым показателям, которые нужно проверять/учитывать/знать, чтобы ваши сервера работали без сбоев, а пользователи не писали гневные тикеты. Я перечислю 5 (и с небольшим погружением в подпунктах), но при желании можно выделить намного больше.
1. Доступность и отклик: жив ли пациент?
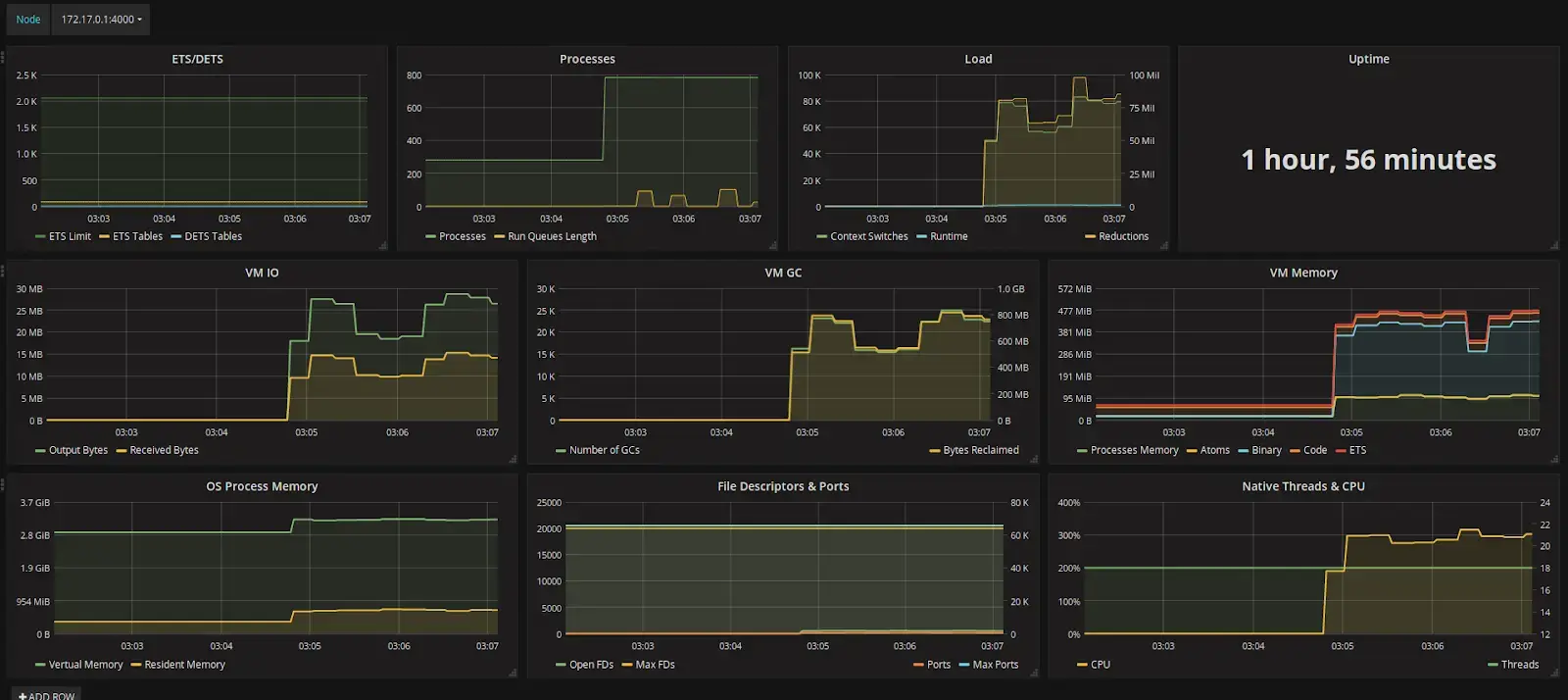
Итак, начнём с самого очевидного. Любая система, какой бы быстрой, производительной и современной она ни была, не имеет смысла, если не отвечает на запросы.
Uptime (время безотказной работы) — вот какая метрика нас интересует. Причём важно помнить: нас интересует аптайм сервиса, а не физического сервера. Высокая доступность — это не «сервер не перезагружался год», а то, что почта работает, сайт открывается, ERP отвечает.
Если отдельный физический сервер работает 500 дней подряд — это скорее тревожный звоночек. Значит, его не трогали: ни обновлений, ни патчей, ни профилактики. В нормальной практике запланированные перезагрузки — признак здорового администрирования. У нас на Хабре есть про это классный материал «Регламент обслуживания любых серверов»
Что вам надо знать про Uptime. Чем больше сервер/сервис работает без выключений (плановых или внеплановых), тем выше его аптайм. Для критичных сервисов, от которых зависит бизнес, будь то корпоративная почта или внутренний ERP — целевой уровень доступности должен быть от 99,9% и выше. На практике это значит максимум 44 минуты простоя в месяц. Всё, что ниже 99,9% — уже на страх и риск. Малого бизнеса показатель uptime почти не касается, так как главное в этом деле — стоимость часа простоя (а там он может и не стоить ничего). Зато крупный бизнес сейчас требуют 99.999% (пять девяток) и выше, что меньше 5 минут простоя в год.
Итак, как проверить доступность сервера/сервиса в данный момент? Для начала узнайте, пингуется ли он. Для этого подходят любые инструменты — от ping через консоль до Zabbix с HTTP-чекерами. Главное — не просто узнать, жив ли сервис, а настроить уведомления, если он умирает (а ещё хуже — если умирает не один, а цепочка из пяти). И учитывайте, что пользователи будут ворчать (а клиенты уходить с сайта), когда страницы или API грузятся слишком долго. Мониторьте время отклика (latency) через APM-инструменты (New Relic, Datadog) и проверяйте, не превышает ли оно SLA (например, 200 мс для веб-приложений).
Совет: настройте алерты на основе SLA. Например, если latency API превышает 500 мс или uptime падает ниже 99.99%, получайте уведомление в Slack Max или Telegram. И не забудьте проверить журналы на предмет ошибок 5xx — они часто указывают на проблемы с сервером или базой данных.
Если вы вдруг заблудились не из мира системного администрирования (или только решили погрузиться), то расскажу, как можно пинговать прямо с вашего ноутбука или ПК на Windows. Откройте командную строку (нажмите Win + R, введите cmd и нажмите Enter). Введите команду (например, для проверки servermall.ru): ping servermall.ru или ping 46.235.191.223 и нажмите Enter.
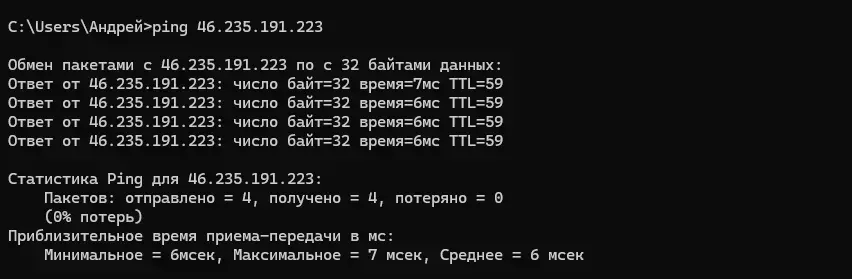
Так вы можете проверить, отвечает ли сервер по протоколу ICMP. Это самый простой тест, но он не всегда надёжен — некоторые серверы блокируют ICMP из соображений безопасности. Если это так, то используйте инструменты вроде tcping или hping3 для проверки соединения на определённых портах. Это поможет избежать ложных выводов из-за правил брандмауэра.
Да, опытный админ скажет, что я говорю об очевидных вещах, но мы только разгоняемся: поднимите руку, кто в последний раз проверял, что резервный канал связи действительно переключается автоматически? Вот и я о том же :)
На практике, когда мы говорим о серьёзном администрировании, важно не просто знать, что сервис доступен, а быть уверенным, что в любой момент он действительно жив, откликается и работает с нужной скоростью. А ещё важнее — быстро понять, что он начал отваливаться, и действовать не по инерции, а по сигналу, приходящему ещё до тикетов и недовольных звонков от пользователей.
Да, сервер может пинговаться, но что если ICMP заблокирован? Что если веб-сервер отвечает заглушкой Nginx'а, вы мониторите код ответа 200 OK, а бэкенд несколько часов как отправился к праотцам? Что если LDAP работает, но не принимает логины?

Идея для подарка админу на НГ
Проверка должна быть не формальной, а контекстной — с учётом роли сервиса. Для сайта важен ответ от HTTP и содержание страницы, для базы — подключение и выполнение простого запроса, для почтового сервиса — отклик от SMTP и приём/отправка писем, для прокси — корректная авторизация и проброс трафика.
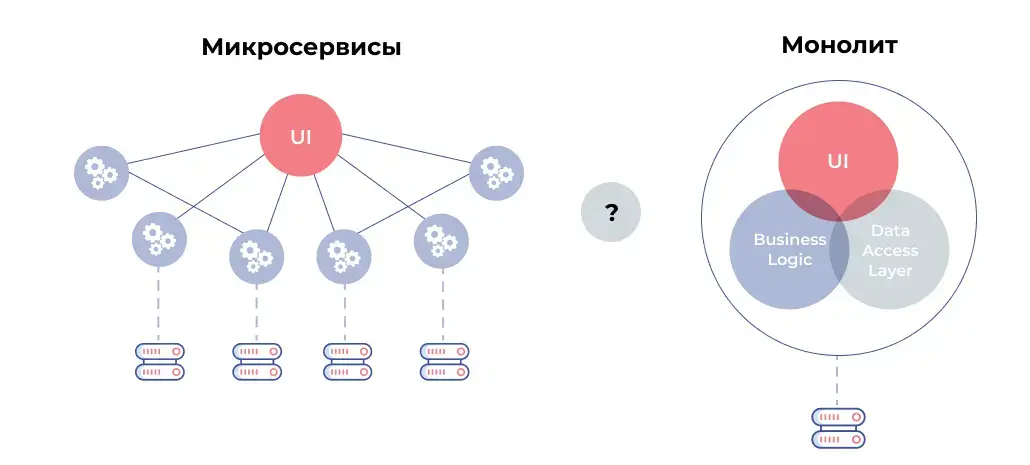
Не менее важен контроль цепочек. Современные сервисы — это не монолиты, а взаимосвязанные узлы. Например, отказ DNS приводит к недоступности внешнего API, которое в свою очередь валит всю CRM. Поверхностный мониторинг скажет: веб-сервер работает. А вот цепочка: DNS → API → backend → UI покажет, что в одном месте прорвало трубу с кипятком. Именно поэтому ад зависимостей надо учитывать и в мониторинге, и в алертах. Если валится одно — можно предсказать и предупредить другие.
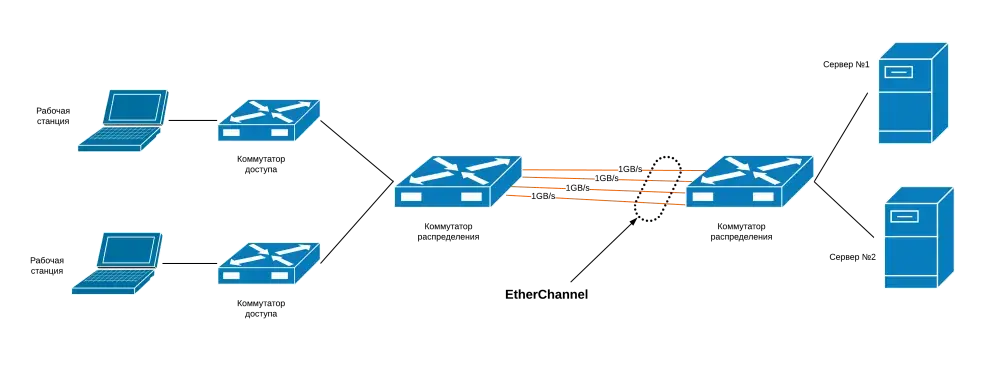
Теперь вернёмся к резервным каналам. Их наличие — палочка-выручалочка, но сколько раз они реально проверялись? Есть ли уверенность, что после сбоя маршрут переключится корректно, IP-таблица обновится, а NAT не перекроет критичный порт? Часто бывает так, что резерв есть на бумаге, но конфиг неактуален, OSPF не срабатывает или failover не доведён до конца. Резервный канал без тестов — это как запасной парашют, который ни разу не раскрывали (а вдруг мыши погрызли). И лучше не проверять его впервые на настоящем падении.
Важно и то, как приходят уведомления. Почта, SMS, мессенджеры, push — сисадмин должен узнать о сбое раньше директора всех. И не просто узнать, а получить сообщение, понятное с первого взгляда. Не «ALARM: HTTP check failed», а что-то в таком духе:
«[CRITICAL] HTTP check failed: ERP-backend (http://erp.example.com) → 502 Bad Gateway
Last successful response: 2024-03-20 09:29:00
Downtime: 2 minutes».
Это уже не просто сигнал — это руководство к действию.
И ещё: доступность — это не столько про реакцию, сколько про профилактику. Это про валидацию SSL-сертификатов заранее, до их истечения. Это про тестирование механизма failover вручную раз в квартал (а лучше — чаще). Это про проверку отклика во всех геолокациях, если у вас распределённая IT-инфраструктура. Это про то, чтобы до релиза протестировать на стейджинг-окружении все критические моменты — а не узнать в пятницу вечером, что обновлённый микросервис требует порт 8443, которого нет в правилах фаервола.
Так что, если вам кажется, что у вас высокая доступность, всё работает, как часы — спросите себя: а вы уверены? А если уверены — спросите, откуда эта уверенность. Из логов? Из реального pinger’а (приложение для диагностики сетевой доступности и проверки соединения с удалёнными хостами)? Или просто из молчания пользователей?
Да, друзья, системное администрирование — это сложное ремесло и превентивная регулярная работа, которую нужно делать не только в день, когда что-то сломалось.
2. Ресурсы сервера (CPU, RAM) — анатомия

Если с доступностью всё более-менее понятно — «работает или нет», то дальше начинается область тьмы нюансов: как работает? Не перегружено ли? Не на грани ли ваш сервер, выдавая наружу бодрый 200 OK? Это как у человека с нормальным пульсом, но с давлением 180 на 120 — вроде ещё живой, но врачи готовят капельницу и реанимацию.
Перегруз ресурсов — это тот самый момент, когда на вид всё спокойно, но где-то в логах уже растёт снежный ком.
И начнём мы, конечно, с CPU

CPU — это сердце системы, которое не должно работать всегда на пределе. Пульс 200 ударов в минуту сутками приведёт к инфаркту. Средняя загрузка CPU в пределах 60–70% — это лучший вариант, он позволяет системе отлично работать, обрабатывать всплески активности и не умирать от деплоев. Когда процессорные ядра постоянно загружены работой на пределе, особенно на системах без балансировки нагрузки и шеринга задач — это плохо. Не потому что будет медленно и «у нас всё лагает», а потому что новые задачи встанут в очередь, начнётся конкуренция за ресурсы, увеличатся задержки. В мире бэкендов и API-сервисов — это путь к тайм-аутам, ошибкам 504 и, как следствие, телефонному звонку от начальника: «а что у нас опять?».
Совет! Если процессоры загружены на 80% и выше в течение долгого времени, это сигнал, что система работает на грани. Используйте top, htop или Grafana для мониторинга.
Ещё хуже, когда нагрузка скачет. В пике — 10%, а потом — внезапный всплеск до 100% на 15 минут. Такие моменты особенно опасны: кажется, что всё ок, но в это пятнадцатиминутное окно как раз попадает и демон cron с отчётами, и скрипт инвентаризации, и CI/CD пайплайн, и служебный бот, который должен обработать вебхуки (webhook) от внешнего сервиса. В итоге всё виснет, а вы потом ищете что первым начало перегружать CPU.
Теперь про память — RAM

RAM — это кратковременная память мозга. Там мы держим информацию по типу: что мы только что прочитали; куда собираемся кликнуть; что и как надо сделать сейчас. В RAM помещаются активные процессы, данные для вычислений, кэш, очереди и всё то, с чем система работает прямо сейчас. Она будет площадкой для всех операций — и её должно быть в достатке. Не с избытком или просто «хватает», а именно в достатке и с небольшим запасом — минимум 10–20% свободной памяти (я бы 30% брал) на любых боевых системах, даже при полной загрузке.
Увы, многие админы смотрят на графики, видят, что память почти вся занята и говорят: «ну это же кэш» и машут рукой. Да, когда в Linux память почти вся занята — это нормально, потому что система старается занять почти всю доступную RAM под что-то полезное: кэш диска — ускорение чтения/записи; буферы — временные данные для сетевых операций и файловых систем. А когда память нужна процессам, система быстро освобождает кэш.

Но если на графике swap (подкачка страниц) тихо растёт, если vmstat показывает активную подкачку, если page faults измеряются тысячами в секунду — это не кэш, это уже трэш. В такой момент система начнёт работать с данными в хранилище, чтобы освободить RAM — и производительность резко падает. Даже на дорогущих NVMe дисках это ощутимо (хоть там дело намного лучше), потому что доступ к RAM — в десятки раз быстрее, чем к любому SSD.
Получим ситуацию, когда процессор стоит без дела, а сервер лагает. Система задыхается от нехватки памяти, а самый простой способ решить проблему (не симптомы убрать) — добавить достаточно памяти с тем самым запасом в 20%.
Но бывает, что на самом деле памяти достаточно. Чтобы вы не покупали сервер для 1С с 8 ТБ DDR5, я расскажу про утечки памяти — ещё одна бомба замедленного действия. Их редко видно сразу. Процесс потихоньку кушает RAM, сервер работает неделю-две, потом внезапно падает от OOM (Out of Memory) — и только перезагрузка временно спасает. После перезапуска сервера/процесса память освобождается, но через несколько дней снова растёт. В top/htop один и тот же процесс постепенно увеличивает RES (потребляемую RAM). В логах иногда мелькают предупреждения OOM-killer, но не всегда.
Графики и мониторинг — лучший способ поймать утечку. Настройте дашборд (Zabbix/Grafana) с историей использования памяти по процессам. Но иногда помогает только обновление софта или фикс кода.
3. Базы данных, хранилище, ввод-вывод
Переполненное хранилище — это как перегруженная рабочая память мозга. Когда слишком много задач и мыслей целый день или неделю, человек теряется, не может сосредоточиться, забывает простые вещи. То же и с сервером: логи не пишутся, базы не могут создать временные файлы, сервисы валятся с ошибкой «no space left on device». Всё это происходит внезапно, но на самом деле — предсказуемо. Когда на сервере заканчивается место, страдает всё. Но, как правило, больше всех — база данных. Это часто самое узкое место в инфраструктуре. Медленные запросы или отсутствие бэкапов могут привести к потере данных или простоям, а это уже прямой удар по бизнесу.
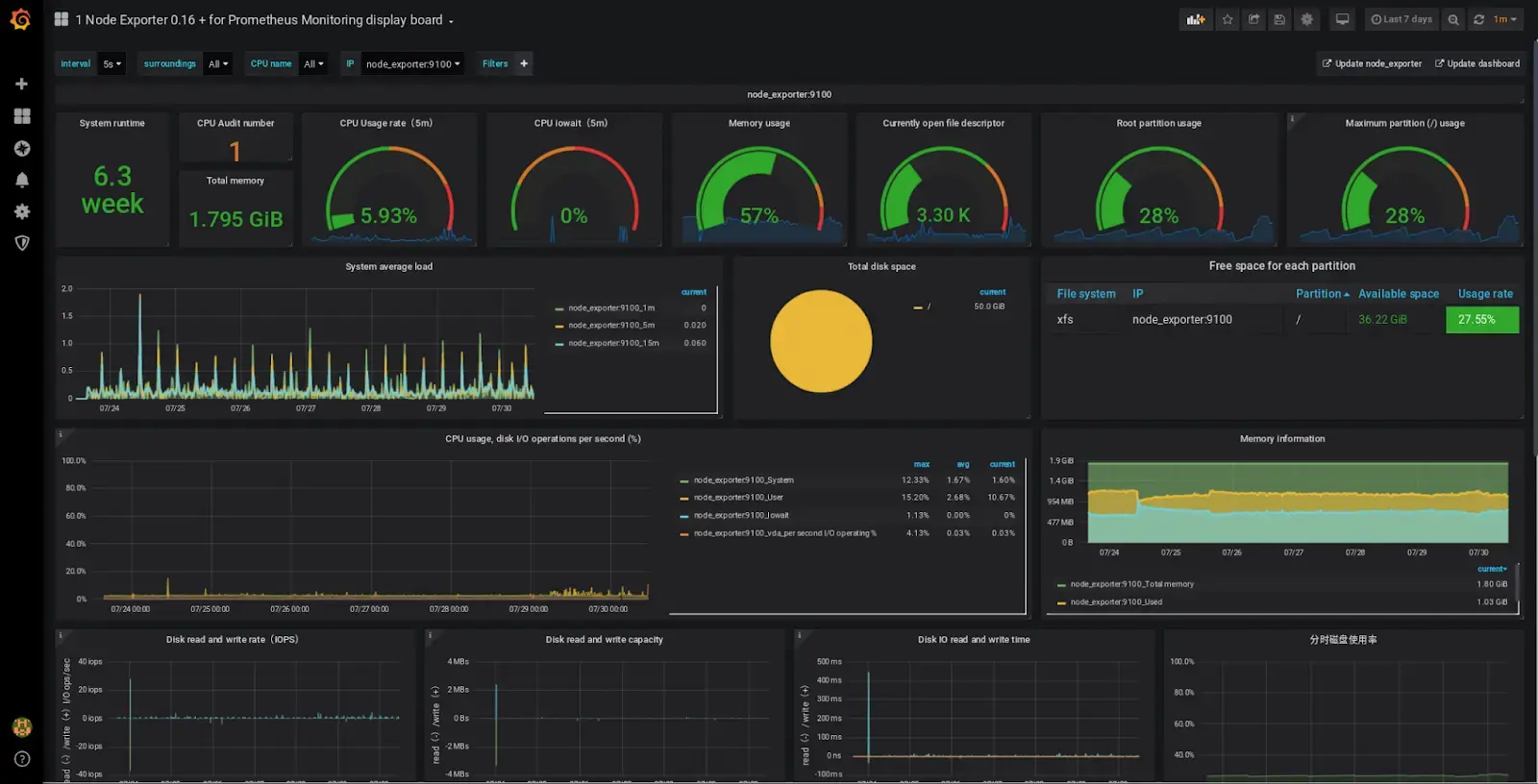
Хорошая идея — настроить мониторинг производительности БД через Prometheus или Grafana. Установите алерты на медленные запросы (например, >1с) и проверьте, хватает ли ресурсов для БД (CPU, RAM, IOPS). А ещё регулярно тестируйте восстановление из бэкапов — не верьте, что они работают, пока не попробуете.
Что проверять?
-
Скорость запросов к БД. Для PostgreSQL — pg_stat_statements, для MySQL — SHOW PROFILE. Если запросы стабильно дольше 1–2 секунд — разбирайтесь: это может быть как проблема в индексе, так и «плохой» план выполнения.
-
Индексы и фрагментация. Проверьте, есть ли нужные индексы, и не деградировали ли они. Используйте VACUUM (PostgreSQL) или OPTIMIZE TABLE (MySQL) — особенно после массовых удалений или изменений данных.
-
Резервное копирование. Убедитесь, что бэкапы создаются регулярно и хранятся в надёжном месте (например, S3 или другое объектное хранилище). В идеале следовать правилу 3-2-1. Проверьте, сколько времени занимает восстановление из бэкапа — это критично для Disaster Recovery.
Мониторинг свободного объёма хранилища бесполезен без анализа, что именно заняло место. df -h показывает 10% свободно? Отлично, но что скрывают эти 90%? Это могут быть логи без ротации. Временные файлы — скрипт упал, а 20 ГБ «временных» данных так и лежат. Огромные кэши веб-серверов. Архивы, которые забыли удалить после передачи. Сервисы мониторинга вроде Zabbix, Prometheus, ELK — сами могут скушать всю хранилку, если не следить за retention policy (политика удержания данных). А встречал и такое, что на тестовом сервере выключили мониторинг диска, потому что там ведь ничего важного… через месяц продакшен лёг из-за общего NFS.
Что делать?
-
Автоматизируйте очистку. Настройте logrotate для всех сервисов. СУБД — cron-скрипты для удаления старых дампов;
-
Мониторьте не только занятое место, но и темп роста;
-
Алерты на ранних стадиях. Не «диск заполнен на 95%», а: «Логи NGINX растут быстрее 1 ГБ/час» или «Prometheus съедает более 10 ГБ/неделю»;
-
Правило для админов: «Если временно отключил алерт — поставь напоминалку в календарь!»
Ну и ввод-вывод. Даже если места хватает, а средняя скорость чтения/записи вроде бы в пределах нормы, один тяжёлый процесс — например, массовый импорт базы или ночной rsync — может парализовать всю СХД. Очередь I/O растёт, latency взлетает до сотен миллисекунд, и всё, что раньше работало быстро, начинает ждать — просто не может пробиться к накопителям. Это особенно болезненно на общих хранилищах, где куча сервисов (виртуалки, базы, бэкапы) делят один пул. Даже SAS SSD или NVMe не спасают, если нет нормального планирования: QoS, разделения нагрузок и мониторинга. Виртуализация только усугубляет — один шумный сосед может положить половину кластера.
Что нужно контролировать:
-
IOPS и latency — не средние, а пиковые. Особенно в ночные окна: бэкапы, задачи ETL, rsync.
-
Очередь на диск — если она растёт, хранилище не справляется.
-
Разделение потоков — базы, бэкапы и лог-файлы не должны жить на одном LUN.
-
QoS / Throttling — настройте ограничения для фоновых задач. Один rsync не должен тормозить базу.
4. Сеть
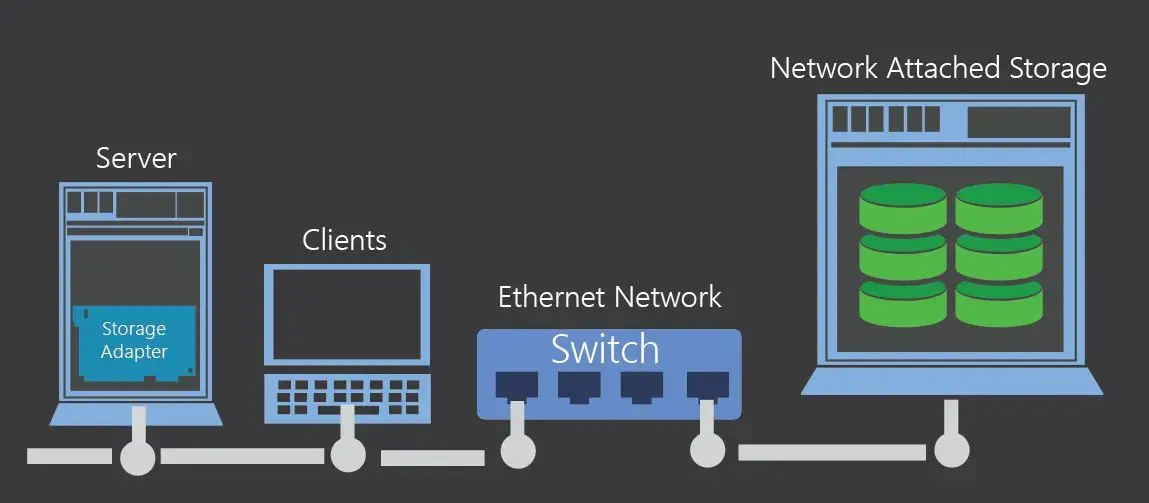
Сеть — это кровеносная система вашей инфраструктуры. Как и в организме здесь опасны не только обрывы, но и воспаления (коллизии, broadcast-штормы, неправильные настройки дуплекса), аритмия (нестабильная задержка, джиттер) и даже тромбы в виде ARP-флуда и переполнения MAC-таблиц коммутаторов.
На бумаге у вас может быть всё красиво: 10 Гбит/с, full duplex, VLAN, балансировка, LACP, QoS и даже SNMP-ловушки. Но реальность — штука весёлая и непредсказуемая. Стоит в час пик включиться плановому бэкапу (а он всегда плановый в самый неподходящий момент), пользователям — массово скачать квартальные отчёты в XLSX на 400 мегабайт каждый, мониторингу — слить 20 тысяч метрик по HTTPS, и вот уже ваш широкий канал становится узким горлышком.
Особенно коварен uplink — соединение между локальной сетью и внешним миром. Проблемы здесь чувствует каждый: веб-сайты не открываются, API зависает, облачные CRM жалуются на нестабильное соединение. А вы, как сисадмин, первым делом смотрите на пинги. И видите — не просто рост задержек, а нестабильность и резкие всплески до сотен миллисекунд. Иногда даже без потерь, но с таким джиттером, что уже при >50 мс VoIP-звонки превращаются в гул морского прибоя, а Zoom-созвоны идут с пятисекундной задержкой, как в телемосте из 90-х.
Совет! Сетевые задержки? Используйте traceroute или MTR, чтобы выявить узкие места в сетевой инфраструктуре. Если пакеты теряются или задержка растёт, это сигнал, что где-то в цепочке (роутеры, провайдеры) есть проблемы.
И да, сеть — это не только между серверами и пользователями. Это ещё и между компонентами системы. Если у вас микросервисы, контейнеры, кластеры, очередь сообщений — внутренняя сеть становится чуть ли не важнее внешней. Потери пакетов между бэкендом и БД, между брокером и воркером — дают эффект не хуже DDoS.
А теперь к классике — маскировке сетевых проблем под всё что угодно. «Тормозит база», говорят пользователи. «API стал отвечать медленно». «Фронт открывается, но долго». И начинается: профилирование SQL-запросов, проверка индексов, анализ GC в Java-приложении. А на деле — пакет теряется где-то между офисом и ЦОДом. Или MTU не совпадает, и каждый второй пакет фрагментируется.
Без мониторинга сети всё это не видно. Нужно отслеживать загрузку интерфейсов, потери на уровне IP, статистику по jitter и latency, желательно в динамике. В идеале — видеть трассировку до ключевых сервисов и смотреть, где начинаются сбои.
Какие инструменты мониторинга должны стать частью вашей работы:
-
SmokePing: Эталон для отслеживания latency/jitter (используется даже провайдерами).
-
MTR (My Traceroute): Показывает где именно теряются пакеты (например, на 4-м хопе у ISP).
-
Prometheus + Grafana: Экспортёр snmp_exporter собирает статистику с коммутаторов (CRC-ошибки, переполнение буферов).
5. Безопасность серверов: что там с иммунитетом

Самая безопасная система — выключенная система.
Серверы сегодня крайне надёжны — от железа до прошивок. Но много проблем приходит изнутри: человек обновил систему без бэкапа, скрипт переехал не в ту папку, кто-то дал временный root-доступ — и всё. Поэтому модель Zero Trust актуальна как никогда: никакого доверия по умолчанию, всё должно быть под контролем. Сюда входит строгий аудит ресурсов, ролевое управление (RBAC), многофакторная аутентификация (MFA), сегментация сети, IAM/PAM и временные права доступа (Just-in-Time). Даже админы не должны иметь постоянный root, а ключи — лежать месяцами в ssh. Внедрять это можно постепенно. Стабильность — не повод отказываться от улучшений.
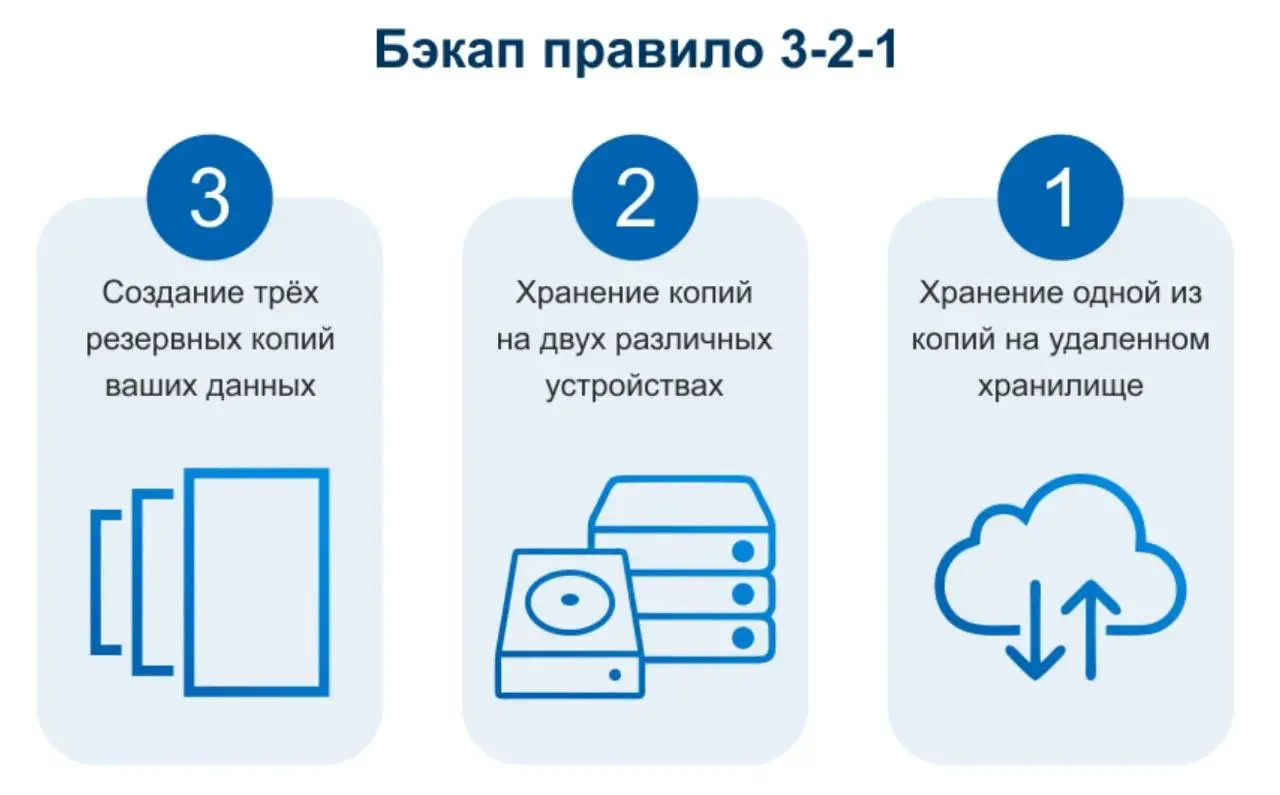
Защита начинается с самого очевидного — надёжное резервное копирование. Без него сегодня никуда. И желательно хранить бэкапы так, чтоб их не пошифровали, иначе толку 0. Причём с регулярными учениями по восстановлению и таймингами (если восстановление занимает день, а иногда и час — это уже риск). Хороший бэкап — это оффлайн-хранилище + облако + ещё одно место (3-2-1), автоматическая проверка целостности, а ещё — изоляция от основного окружения (например, через объектное хранилище с WORM-политикой).
Но и это не всё. В кибербез можно погружаться глубоко, про это у нас есть отдельный материал на Хабре: логирование действий пользователей, ловушки (honey files), мониторинг подозрительной активности через SIEM, SOAR и UBA, контроль командной строки, автоматическая ротация ключей, ограничение доступа по времени и цели — всё это снижает шанс атаки изнутри или скомпрометированного аккаунта.
Но важно помнить, если безопасность сильно мешает людям работать, то они начнут уходить из компании. Защита не должна превращать сервер в крепость с пятью паролями и сессиями по 5 минут. Баланс между удобством и контролем — вот что действительно важно. Прозрачный доступ, понятная авторизация, обучение сотрудников, имитация фишинговых атак, внутренняя культура безопасности — всё это даёт реальный эффект. Важно отличать здоровую паранойю от нездоровой, оценивать риски и стоимость (включая косвенные расходы) их митигации.
Что точно нужно:
-
ОС и ПО обновлены, включая библиотеки и web-серверы. Обновления — отдельная боль. Но лучше их поставить, чем потом объяснять, почему старый OpenSSL с Heartbleed внезапно стал причиной инцидента. Обновления должны быть не стихийным событием, а частью регулярного цикла, с тестовой средой, откатом и логикой приоритизации: где просто важно — а где срочно.
-
Логи входа проверяются регулярно, особенно под root или через sudo. Проверяйте их под утренний кофе — без этого день не начинается. Если что-то пошло не так, вы это заметите не через неделю, а сразу.
-
Подозрительные процессы отслеживаются (ps aux, netstat, ss, auditd, fail2ban). Это не просто команды, а отражение жизни системы. Подозрительный PID, лишний слушающий порт или попытка брутфорса — всё это можно поймать, если смотреть.
-
Бэкапы в центре безопасности. Они восстанавливаются, тестируются, сравниваются по времени и хранятся не там, где прод.
Чек-лист сисадмина: ключевые показатели здоровья инфраструктуры
|
Зона контроля |
Что проверять регулярно |
|
1. Доступность |
Uptime ≥ 99.9% (для критичных систем — ≥ 99.999%) SLA по latency (например, API — ≤ 200–500 мс) Ответы сервисов не просто 200 OK, а с корректным содержимым Проверка резервного канала: failover работает, маршруты переключаются Алерты: приходят в Telegram с контекстом, а не просто «ALARM» Мониторинг цепочек зависимостей (DNS → API → backend → UI) Валидность SSL-сертификатов и их срок действия |
|
2. Ресурсы |
CPU: средняя загрузка ≤ 70%; нет пиков > 90% без нагрузки RAM: запас свободной памяти ≥ 20–30%; отсутствие постоянного swappiness/page faults, отслеживание утечек памяти по графикам (растущий RES у процесса) IOPS/Latency: нет очередей на диск, нормальный отклик даже ночью, нагрузочные пики прогнозируемы (cron, CI/CD, отчёты и пр.) |
|
3. Хранилище и базы данных |
Свободное место на дисках ≥ 10–15% Мониторинг роста логов / кэшей / временных файлов Скорость SQL-запросов (идеально < 1с); индексы актуальны VACUUM / OPTIMIZE / фрагментация учтены Бэкапы: автоматизированы, регулярно тестируются, не лежат рядом с продом Следование правилу 3-2-1; тайминг восстановления известен |
|
4. Сеть |
Ping, jitter ≤ 30 мс, packet loss < 1% Внутренние трассировки (MTR/Traceroute): потерь нет Uplink в порядке: нет спайков задержки, MTU согласованы Мониторинг интерфейсов (CRC, buffer drops, broadcast-штормы) Контроль внутренних связей: микросервисы ↔ базы ↔ брокеры QoS: фоновая нагрузка (бэкапы, rsync) не мешает бизнес-процессам |
|
5. Безопасность |
Обновления ОС, библиотек, web-серверов — по плану, не хаотично MFA для критичных доступов, временные root-права (Just-in-Time) Логи входа и sudo активностей проверяются ежедневно Мониторинг подозрительных процессов и портов (auditd, fail2ban) Бэкапы хранятся оффлайн и в облаке, доступны только через IAM/PAM Внутренняя культура и цифровая гигиена: обучение, симуляции фишинга, прозрачные политики доступа |
Вместо выводов
День системного администратора — отличный повод вспомнить, кто держит IT-мир на своих плечах, но это также и возможность переосмыслить подход к работе.
Ключ к здоровой инфраструктуре — это не только исправление проблем, но и их профилактика через постоянный мониторинг доступности, ресурсов, сети и безопасности. Регулярный анализ метрик, тестирование резервных систем и поиск слабых мест до того, как они станут проблемами — вот что отличает хорошего сисадмина.
А ещё тишина :) Когда всё работает, никто не жалуется и даже не догадывается, сколько труда стоит за этим. Чтобы так и оставалось, не забывайте учиться и адаптироваться: технологии меняются, угрозы усложняются.
С праздником, коллеги! И желаю вам поменьше тикетов в пятницу вечером :)






Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение