

Привет!
Есть такое понятие — «Edge Computing». Сисадмины, IT-архитекторы, техдиры и все причастные обычно говорят «Эдж-вычисления» (и «Эдж-узлы», если речь о серверах). Прямых переводов два — граничные или периферийные вычисления. Тут уже на вкус и цвет :)
Итак, что это за зверь такой и зачем он нужен?
В мире есть небольшая проблемка — огромный рост данных (Big Data). Объём информации, которую мы с вами генерим ежедневно в интернетах, дошел до уровня в 328,77 миллиона терабайт (0,33 зеттабайта). Эту цифру сложно визуализировать в голове, но я постараюсь — это как полностью заполнять примерно 658 миллионов айфонов (4,5 населения России) с 512 ГБ памяти КАЖДЫЙ ДЕНЬ. В год выходят совсем уж неприличные цифры.
И если обычному пользователю эта проблема незаметна, то бизнесу нужно успевать за ростом объёма данных, чтобы обрабатывать и передавать их: камеры, датчики, кассы, контроллеры, терминалы — всё это генерирует огромные потоки информации, которым физически нужно проделать огромный путь до облаков, ЦОДов и серверных, а для этого нужна быстрая и стабильная сеть с широким каналом и минимальными задержками, что не всегда возможно (перегруженные и нестабильные каналы связи — не редкость).
Поэтому вычисления приходится переносить ближе к источнику данных — то есть на периферию инфраструктуры, отсюда и название сабжа.
Что ж, пора начинать самый подробный в Рунете обзор граничных aka периферийных вычислений.
Что такое Edge Computing и почему сейчас об этом много говорят
Для начала дам академическое определение — мне не очень нравится вариант с Википедии, поэтому объясню иначе.
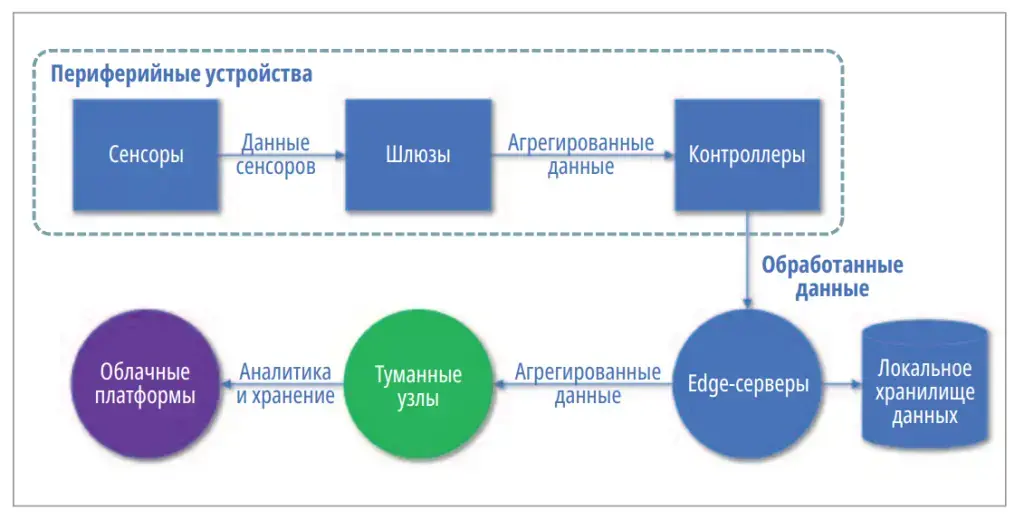
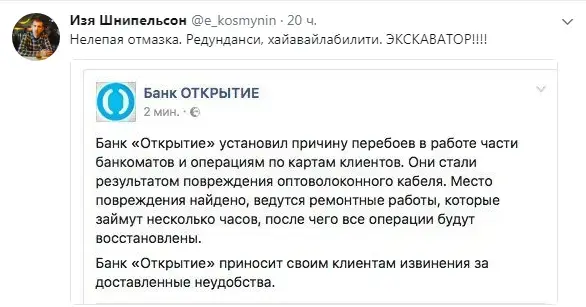
Граничные или Периферийные вычисления (Edge Computing) — это обработка данных на уровне, максимально близком к источнику их появления. Если в классической модели данные отправляют в ЦОД или облако целиком, то в эдж-вычислениях сначала идёт локальная обработка (частичная или полная, причем сервер все равно может быть относительно удалённым), фильтрация и принятие решений, а только в конце — передача информации в основную (центральную) инфраструктуру.
В 2026 году рост данных, распространение IoT/IIoT и развитие ИИ сделали эдж-архитектуру явлением повсеместным.
ПРИМЕР! Инференс искусственного интеллекта (от англ. inference — «вывод»). ИИ-система использует заранее обученную модель для принятия решений на основе новых данных на периферии. Компактные модели инференса кардинально снижают задержки и нагрузку на сеть.
Аналогичная логика работает и в средствах защиты информации — например, в системах класса SEIM (Security Information and Event Management), вроде Splunk Enterprise Security или IBM QRadar. Эти системы собирают сырые логи с серверов, сетевого оборудования, рабочих станций и по правилам корреляции выявляют аномалии, которые могут сигнализировать об атаке.
Если у компании десятки или сотни филиалов, передавать весь объём логов в центральный ЦОД нерационально: это нагрузка на каналы, рост требований к хранилищу и дополнительные задержки. Гораздо эффективнее обрабатывать события локально — на edge-узле. Он агрегирует и анализирует поток, отбрасывает шум и отправляет в центр только значимые инциденты или уже коррелированные события.
В итоге ЦОД получает не массив разрозненных записей, а структурированную картину инцидентов. Это снижает нагрузку на инфраструктуру и ускоряет реакцию службы безопасности.
Сегодня эдж-узлы работают в магазинах, на производствах, в телеком-сетях, филиалах и удалённых офисах. Локальные админы, которые работают с эдж-узлами, редко называют их эдж-узлами — с их точки зрения это просто серверы, которые обрабатывают данные на месте и передают на следующий уровень.
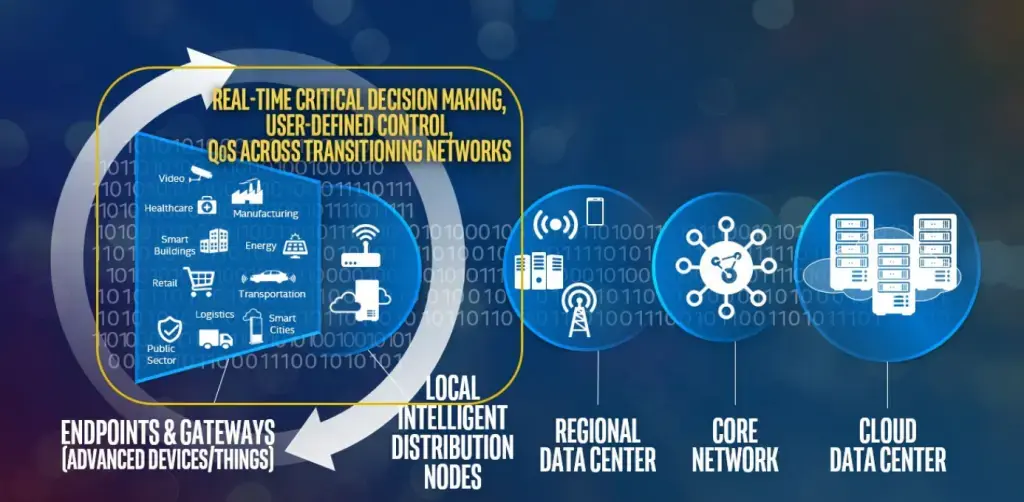
И вот тут неплохо бы очертить границу между ЦОДом, облаком и периферийными вычислениями — взбалтывать можно, но смешивать не стоит. Граница эта проходит не по форм-фактору и месту размещения оборудования, а по требованиям к задержкам, пропускной способности и автономности. ЦОДы и облака никуда не исчезают из цепочки — они становятся местом для хранения, сложной аналитики и работы с историческими данными. Инфраструктуру для периферийных вычислений строят, когда передача сырых данных становится нерентабельной (или очень дорогой), медленной (с долгим откликом) и/или небезопасной.
ВАЖНО! Граничные вычисления — не замена, а дополнение к классической централизованной инфраструктуре. Периферийные узлы (ноды) берут на себя обработку в реальном времени и предварительный анализ, а ЦОДы и облака занимаются агрегацией данных, обучением моделей и стратегической аналитикой. Это инфраструктурный подход, который позволяет сбалансировать производительность, надёжность и стоимость владения всем оборудованием.
Какие бизнес-задачи решают граничные вычисления
Главная ценность граничных вычислений для бизнеса — это решение прикладных, а не абстрактных задач. То есть перед нами не модная технология, вроде LMM (Large Multimodal Models, например, ChatGPT), а вполне себе проверенный подход для улучшения рутинных процессов в IT-инфраструктуре.
Я выделю 4 основных задачи, которые решают граничные вычисления, но это не исчерпывающее описание — можно и больше, однако для общего понимания этого достаточно.
Первая задача — снижение задержек и работа в реальном времени. Даже самое продвинутое облако не заменит локальные вычисления, когда важен миллисекундный отклик. Видеоаналитика в магазине (хотя тут ещё возможно облако, но не особо нужно), система предотвращения аварий на производстве или беспилотное управление автомобилем/самолётом/спутником не могут ждать ответа от удалённого ЦОДа и не могут потерять связь. Там всегда есть эдж-узел, который принимает решение локально, рядом с источником данных.
Вторая задача — экономия на сетевых каналах (отказ от передачи ненужных данных). Камера видеонаблюдения пишет поток 24/7, датчики отправляют телеметрию каждую секунду (и чаще), а промышленные системы генерируют огромные массивы логов. Передавать всё это в облако — дорого и часто бессмысленно. На периферии данные можно отфильтровать, агрегировать или проанализировать, а в ЦОД отправлять только события, метрики или сигналы об авариях и сбоях — ещё и в сжатом виде. В итоге бизнес тратит на связь и вычисления меньше, а инфраструктура работает стабильнее и быстрее.
Третья важная задача — повышение отказоустойчивости и автономности. Граничные вычисления либо снижают, либо полностью убирают зависимость от внешних каналов и ЦОДов. Если связь с ЦОДом пропадает, локальный узел продолжает работать и выполнять критичные функции. Для удалённых объектов, заводов, производств и розничных сетей — это не вопрос удобства, а вопрос работы в целом. Если речь о критических системах, дорогом простое и жизнях людей, то эдж-узлы соединяют в отказоустойчивые кластеры (2 средних узла лучше, чем 1 мощный), чтобы поломка одного не привела к отказу всей системы.
Наконец, эдж-вычисления помогают соблюдать требования к хранению и обработке данных. В некоторых отраслях данные нельзя свободно передавать за пределы ЦОДа или региона — из-за регуляторов, политики безопасности или коммерческих рисков. Периферийные вычисления позволяют обрабатывать чувствительную информацию локально, не нарушая внутренних регламентов и требований законодательства.
На самом деле граничные вычисления не усложняют архитектуру, а наоборот — убирают лишние звенья там, где они мешают скорости, надёжности и прибыли.
Где граничные вычисления используют на практике
Не все компании знают, что них уже есть инфраструктура периферийных вычислений. Часто компаниям не до названий, особенно если внутренних компетенций немного (у среднего и малого бизнеса — это повсеместно). Просто сделали сами по наитию или интегратор постарался. Ведь логично обрабатывать данные там, где это выгодно? Главное, что всё работает — и это хорошо.
В рознице, например, такие решения чаще всего работают с камерами и кассами. Видеоаналитика идёт прямо в магазине в реальном времени: система считает посетителей, замечает очереди, отслеживает перемещение товаров, улавливает подозрительные сценарии. Кассы самообслуживания тоже считают всё на месте. В результате меньше задержек, меньше зависимостей от сети и простоев работы — магазин продолжает работать, даже если сеть отказала (не всегда, но такое возможно как благодаря эдж-вычислениям).
Классический пример! Если магазин полностью завязан на центральную базу в облаке, каждая операция — от пробития чека до проверки остатков — проходит через внешний канал связи. Пока сеть стабильна, всё работает отлично. Но при сбое всё начинает зависеть от доступности облака: задержки растут, часть операций блокируется, а в худшем случае торговая точка просто встаёт.
Альтернатива — локальная база данных на уровне магазина с регулярной синхронизацией с центральной системой. Продажи, списания, движения товара, работа касс самообслуживания и видеоаналитика обрабатываются на месте. Магазин остаётся операционно автономным: он может продолжать работу даже при временной потере связи с ЦОДом. Когда канал восстанавливается, происходит обмен изменениями.
При этом критичные операции, где важна глобальная консистентность, логично оставлять централизованными. Например, погашение подарочных сертификатов или бонусных баллов. Если разрешить их списание на локальном уровне, появляется риск двойного использования: один и тот же сертификат могут погасить одновременно в разных магазинах. Поэтому проверка и подтверждение таких транзакций идут через общую облачную базу в режиме реального времени.
Такая гибридная модель обычно состоит из 3 компонентов:
- Операционные процессы — локально, с минимальной задержкой;
- Аналитика и агрегированные данные — направляются в ЦОД;
- Критичные к согласованности операции — подтверждаются через облачную систему.
То есть цель edge-вычислений — не заменить облако, а разгрузить его и убрать лишнюю зависимость от сети там, где это возможно без потери целостности данных.
На производстве локальная обработка данных — норма с прошлого тысячелетия. Датчики, контроллеры и системы мониторинга собирают телеметрию в реальном времени, а эдж-узлы обрабатывают и анализируют её сразу, не отправляя каждую метрику и запись в ЦОД. Так, например, организуют предиктивное обслуживание — техника заранее предупреждает о вероятном сбое и потенциальном отказе. Для производства архиважно быстро реагировать на это, так как простой даже не завода целиком, а всего одной линии, может стоить очень дорого и повлиять на другие линии.
В телекоме и транспорте граничные узлы — явление повсеместное. Базовые станции, узлы связи, транспортные хабы должны реагировать мгновенно. Здесь важна минимальная задержка и стабильная работа. Локальная обработка позволяет не гонять огромные массивы данных по магистральным сетям, что повышает качество и стабильность сервиса для конечных пользователей.
В корпоративных IT-инфраструктурах локальные узлы берут на себя кэширование, аутентификацию, обработку данных и работу критичных сервисов. За основным ЦОДом / серверной остаётся контроль и тяжелая аналитика. Для компаний с десятками и сотнями филиалов такой подход невероятно упрощает масштабирование и снижает требования к сети.
В гибридных офисах. Есть ещё один сценарий, который встречается относительно часто — это классический офис с гибридной архитектурой, где основная часть размещена в облаке, а часть сервисов работает на локальном сервере.
Сейчас модно полностью уходить в SaaS и IaaS — почта в Microsoft 365, CRM в облаке, ERP в облаке, файлы в облаке, бэкапы тоже. И для части компаний это даже неплохо работает, однако почти всегда лучше оставить один или несколько локальных серверов.
Зачем?
Во-первых, аутентификация и авторизация. Контроллер домена, кэширование учётных данных, локальный RADIUS, внутренняя LDAP-инфраструктура — всё это критично к задержкам и стабильности канала. Если офис на 80–150 человек полностью зависит от внешнего линка, то при падении все сотрудники внепланово пойдут пить кофе вместо работы.
Во-вторых, файловые ресурсы. Даже если основное хранилище — облачное, локальный файловый сервер с кэшированием и синхронизацией резко снижает нагрузку на канал и ускоряет доступ к часто используемым данным. Особенно чувствительно при работе с большими файлами и проектами — CAD, BIM, медиа, архивы.
В-третьих, 1С, прокси, шлюзы безопасности, системы видеонаблюдения, печать. Эти задачи не требуют гипермасштабируемого облака, а вот предсказуемость — очень даже. Полный уход в облако — это ставка на то, что внешний канал будет стабилен всегда. А он не будет. И два магистральных не будут — у одного провайдера что-то откажет, у второго ковшом кабель перебьют, а бизнес простаивать будет ваш.
По теории прошлись, теперь переходим к подбору.
Эдж-узел — это не просто маленький сервер

На этапе подбора может показаться, что классический эдж-узел — это какой-нибудь компактный сервер или ПК поближе к источнику данных: в подсобке магазина, на столе в «кабинете» АСУшника или в каком-то шкафу на ключике, где раз в несколько месяцев админ что-то делает, но никто не знает, что именно. На практике оно может быть и так, но упрощать и обобщать всё же не стоит — иначе придётся всё переделывать для нормальной работы.
Самое важное — это не железо, а условия эксплуатации. Если в ЦОДах или правильных серверных уже есть нормальные условия (СКУД, контроль влажности и температуры, фильтрация воздуха, заземление, бесперебойное питание, управляемые блоки розеток), то на периферии может не быть ничего. Но стабильно работать годами в неидеальной среде как-то надо. Как понимаете, в таких условиях важнее не высокую производительность организовать сначала, а разобраться с перегревом, пылью, вибрациями (ага), нестабильным электропитанием через обычную розетку и местным интернет-провайдером. Если устранить это невозможно технически, то надо смотреть на защищённые модели серверов (rugged), вроде серии Dell PowerEdge XR (NEBS Level 3, MIL-STD-810H, работа от -5°C до +55°C). Классический сервер, вроде HPE DL380 Gen11, который прекрасно работает в серверной, едва ли готов к полевым условиям.
Иногда лучше выбрать менее мощное, но холодное и простое решение, чем придумывать костыли для борьбы с перегревом и троттлингом после внедрения.
|
Охлаждение и среда |
|||
|
Параметр |
Стандарт |
Расширенный |
Rugged |
|
Температура |
10–35°C (хотя инженер скажет, что вообще-то и 40 можно для A2/A3 class) |
0–45°C |
-20–55°C |
|
Пылезащита |
Стойка |
Фильтрация |
Защищённый корпус |
|
Вибрации |
Нет |
Умеренные |
Сертификация MIL/NEBS |
|
Форм-фактор |
1U/2U |
Short-depth |
Rugged/Wall-mount |
Ещё один важный момент — физический доступ. Периферийная инфраструктура нередко подразумевает, что там нет постоянного сисадмина (сначала подключается удалённый, если проблема не решается — выездной), а значит любое физическое обслуживание — это выезд, время и деньги. Поэтому такие узлы проектируют максимально автономными и долговечными: удаленный доступ и управление питанием без физического присутствия админа (iDRAC, iLO…), мониторинг, автоматические обновления и сценарии замены целиком, а не сложного ремонта на месте.
А производительность определяют следом — под задачу, после того, как условия эксплуатации сделали пригодными. Об этом и поговорим.
Какой Edge-сервер выбрать вам: подбираем оборудование под задачу
Периферийная инфраструктура неуниверсальна — да и нет такой цели. Попытка закрыть все сценарии одним устройством или типом оборудования заканчивается так себе — либо переплатите, либо будут проблемы в эксплуатации. Эдж-узлы нужно подбирать под конкретные задачи и чётко определять их роль в общей архитектуре. Расскажу о четырёх основных сценариях.
Начальный Edge-узел — для сбора и фильтрации данных

Самый простой и массовый сегмент — это простой узел для сбора и фильтрации данных. Такие узлы принимают телеметрию от датчиков, камер или терминалов, выполняют первичную обработку и передают результат дальше. Здесь не нужны десятки ядер или большие объёмы памяти (что особенно хорошо). Гораздо важнее стабильная работа, низкое энергопотребление и базовая отказоустойчивость. Часто это компактные x86-системы с минимальным количеством накопителей и простой сетевой платой.
Тут ещё и сэкономить можно, так как для фильтрации и телеметрии подходят серверы предыдущих поколений — при правильной конфигурации они справляются не хуже новых платформ, но позволяют сократить бюджет проекта процентов этак на 70%.
Примеры серверов:-
Dell PowerEdge R250 / R260 — простые 1U серверы начального уровня (x86, 1 сокет);
-
HPE ProLiant DL20 Gen10 / Gen11 — компактный 1U, хорош для небольших площадок;
-
HPE ProLiant MicroServer Gen10 Plus / Gen11 — для совсем небольших точек.
-
Lenovo ThinkEdge SE350 Edge — компактный пограничный сервер специального назначения. Предназначен для работы в суровых условиях, поддерживает разнообразные рабочие нагрузки пограничных серверов и IoT.
Edge-узел для гибридных инфраструктур
Та самая связка облака и локального сервера, что я упоминал в начале статьи. Частый вариант в рознице или филиалах — вся логика крутится в центральной базе в облачной ERP, но есть задачи, которые не должны зависеть от канала. Поэтому в гибридной схеме на площадке поднимают локальную базу с регулярной синхронизацией с ЦОДом. Продажи, списания, движение товара, работа касс и видеонаблюдение обрабатываются на месте. Связь пропала — магазин продолжает работать. Канал вернулся — изменения синхронизировались.
Напомню, что некоторые операции (подарочные сертификаты, бонусы, централизованные акции) идут всё равно через ЦОД в реальном времени, чтобы никто не смог, например, списать бонусы или погасить 1 сертификат в 2 магазинах одновременно.
Под такую модель нужен уже полноценный сервер, так как на нём работает локальная БД, 2–6 виртуальных машин (AD, файловый сервер, сервисы интеграции, 1С/ERP-агент, шлюзы), кэширование и резервные роли инфраструктуры.
Но топовая производительность и GPU здесь обычно не нужны, важнее предсказуемость и отказоустойчивость. Минимальная разумная конфигурация — один процессор среднего уровня, 64–128 ГБ ECC-памяти и нормальная дисковая подсистема на SSD с зеркалом под систему и RAID10 под данные. Экономить на дисках в таком сценарии точно не стоит.

Я бы под гибридную инфраструктуру советовал проверенные серверы 1U/2U — их проще обслуживать, масштабировать и администрировать:
-
Dell PowerEdge R740 / R740xd / R750 — универсальные серверы на любой случай.
-
HPE ProLiant DL360 / DL380 (Gen10 и старше) — классика для локальной виртуализации.
-
Lenovo ThinkSystem SR650 (любые версии, включая V2 и V3) — сбалансированные платформы под 2 сокета.
Если филиал крупный, лучше ставить как минимум два узла и поднимать небольшой кластер, чтобы выход из строя одного сервера не приводил к простою точки.
Edge-узел для аналитики и ИИ-инференса

Следующий класс — для аналитики и ИИ-инференса. Если данные нужно не просто собрать, а проанализировать в реальном времени, то нужен сервер помощнее. Видеоаналитика, распознавание образов, предиктивные модели — всё это требует вычислительной мощности. В такие узлы уже и GPU устанавливают и специализированные ускорители (ASIC), и быстрые NVMe-накопители для быстрой работы с данными. При этом надо искать баланс между производительностью и тепловыделением, так как мощный узел будет греться, а значит надо продумывать отвод тепла (выше я писал про условия эксплуатации).
Примеры серверов:
-
Dell PowerEdge R760xa / R770 — если нужен полноценный GPU-сервер.
-
Dell PowerEdge XE9680 (скорее уже для мини ЦОДа и тяжелого ИИ).
-
HPE ProLiant DL385a Gen11 — GPU-оптимизированный сервер.
HPE ProLiant DL360 Gen10 Plus / Gen11 + GPU — компактная конфигурация для инференса. -
Lenovo ThinkSystem SR650 V3 с GPU — универсальный сервер, подойдёт для ИИ и аналитики.
Lenovo ThinkSystem SR675 V3 — под серьёзные GPU-нагрузки.
Индустриальный Edge-узел

Под индустриальные граничные узлы отлично подходят защищённые серверы (rugged server), которые я упоминал выше. По сути это отдельная категория устройств — специальное оборудование для работы вне ЦОДа в условиях экстремальных температур с перепадами, вибрациями, запыленностью и агрессивной средой. Они сертифицированы по военным/телеком-стандартам и гарантируют бесперебойную работу там, где обычное IT-оборудование быстро выходит из строя.
Для индустриального узла апгрейды и масштабирование отходят на второй план — стабильность и предсказуемость важнее, чем возможность добавить ещё один ускоритель через год или обновить процессор.
Примеры серверов:
-
Dell PowerEdge XR11 / XR12 — сертификация для телеком и промышленности.
-
Dell PowerEdge XR4000 — компактный многоузловой сервер для граничных вычислений.
-
HPE Edgeline EL4000 / EL8000 — конвергентная высокопроизводительная периферийная платформа в компактном корпусе. Предназначена для сложных сетевых задач, мультиплексирования или для работы на специфичных удалённых участках. Серьёзное оборудование, которое обычно привозят под заказ.
-
Lenovo ThinkEdge SE450 — компактный пограничный сервер для искусственного интеллекта (ИИ).
На что обращать внимание при выборе железа для граничных вычислений
Предположим, что вы разобрались с условиями эксплуатации, удалённым управлением и физическим доступом, определились с задачей. Как подбирать комплектующие?
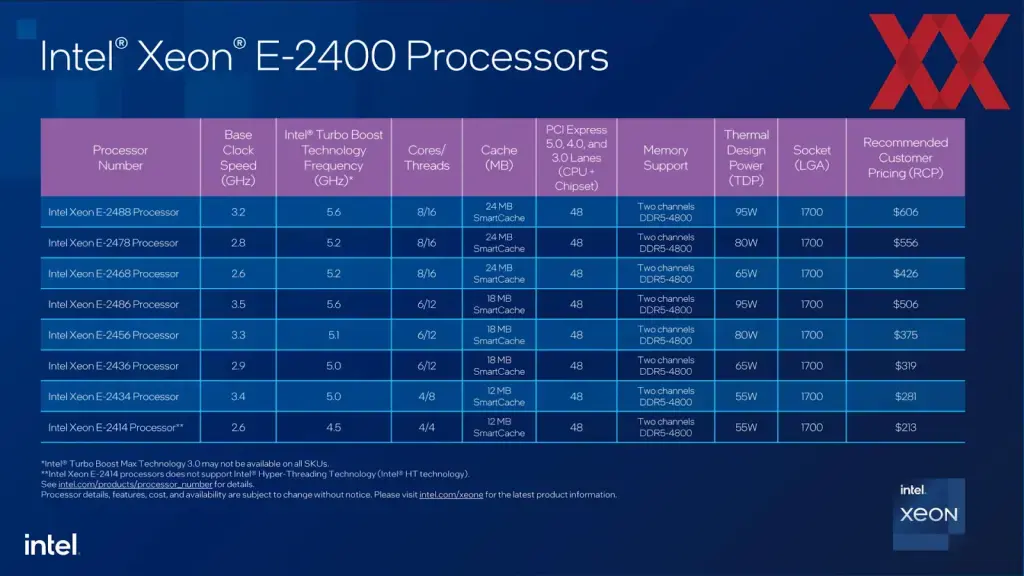
Процессор в граничных вычислениях должен быть стабильным и энергоэффективным (максимум производительности при минимальном потреблении). Большинство периферийных задач не требуют производительности флагманов, зато высокий TDP влияет плохо. Бывает, что ставят R760 + 2 GPU туда, где достаточно E-2400 — не надо так.
Примеры: Intel Xeon E-2400 (для компактных узлов, филиалов, микросервисов), что-то из линеек Intel Xeon Silver (из-за низкого TDP), линейки AMD EPYC 4004 и AMD EPYC 8004 (энергоэффективность, много ядер, умеренный TDP).
|
Процессор |
|||
|
Параметр |
Минимально |
Рекомендовано для Edge |
Комментарий |
|
Количество ядер |
4 |
8–16 |
Для телеметрии 4–8 достаточно |
|
TDP |
≤95 Вт |
35–75 Вт |
Критично при плохом охлаждении |
|
Поддержка ECC |
Обязательно |
Обязательно |
Стандарт отрасли в целом |
|
Версии PCIe |
4.0 |
4.0 / 5.0 |
Важно для GPU и NVMe |
Память должна быть только с поддержкой ECC (коррекцией ошибок). На периферии ошибки памяти найти сложнее, а последствия могут быть незаметны, пока система не накопит их. Для узлов, работающих автономно и без постоянного контроля это крайне важно. Зачастую важнее, чем разница между DDR5 и DDR4.
|
Память |
||||
|
Параметр |
Минимум |
Оптимально |
Для ИИ |
Комментарий |
|
Тип памяти |
ECC UDIMM/RDIMM |
ECC RDIMM |
ECC RDIMM |
Только ECC — это стандарт отрасли в целом, нужен мониторинг ECC-ошибок (через IPMI/Redfish) + настроить реакцию системы на ошибки памяти |
|
Объём |
16 ГБ |
32–64 ГБ |
64–128 ГБ |
Закладывать +30% запаса |
|
Кол-во каналов |
2 канала |
4 канала |
4+ |
Влияет на пропускную способность, но если процессор физически двухканальный (Xeon E, EPYC 4004) — 4 канала невозможны, а вот у EPYC 8004 — 6 каналов, и это отличное преимущество |
|
Частота |
DDR4-3200 |
DDR5-4800+ |
DDR5 |
С DDR5 сейчас приходится выбирать очень тщательно |
Накопители в edge-инфраструктуре живут в режиме постоянной записи. Логи, телеметрия, временные данные — всё это изнашивает диски быстрее, чем классические серверные нагрузки. Поэтому ресурс записи и надёжность важнее пиковых скоростей. Быстрые NVMe нужны там, где идёт активная аналитика, но даже в этом случае бенчмарки не перевешивают реальные задачи.
Для edge-узлов с нестабильным питанием важна технология Power Loss Protection (PLP), желательно — аппаратная. По сути это технология для снижения потерь данных с помощью сохранения питания SSD, благодаря встроенным конденсаторам питания (Power Caps). Также неплохо бы разделить дисковую подсистему — под ОС, под данные и под кэш/буфер.
|
Накопители |
||||
|
Параметр |
Логи/телеметрия |
Видео |
AI/аналитика |
Комментарий |
|
Тип |
SATA SSD (Enterprise) |
NVMe |
NVMe Gen4 и новее |
Не использовать потребительские SSD |
|
DWPD |
≥1 |
1–3 |
3+ |
Drive Writes Per Day — это показатель долговечности твердотельных накопителей, если у SSD DWPD = 1, это значит, что накопитель можно полностью перезаписывать раз в день на протяжении всего гарантийного срока службы (например, 5 лет) |
|
RAID |
RAID1 |
RAID1/10 |
RAID1/10 |
Минимум зеркало под систему, RAID5 в edge-сценариях (как и в других) почти всегда неоправдан из-за длительного восстановления и повышенной нагрузки на накопители. В распределённых узлах надёжнее использовать RAID1 или RAID10 |
|
Объём |
480–960 ГБ |
1–4 ТБ |
2–8 ТБ |
Важна способность сохранять данные без потери или искажения в течение длительного времени, но без точного понимания задачи объём определить сложно |
|
TBW |
Высокий |
Высокий |
Очень высокий |
TBW (Total Bytes Written) — это суммарный ресурс записи данных за весь срок службы накопителя |
Сеть часто недооценивают, а зря — она связывает граничную инфраструктуру со всей остальной, а потому это самый важный пункт.

Два физических интерфейса — это минимум. Один канал работает в продакшене, второй — в резерве или в агрегации (LACP). Чаще всего узел вообще виртуализирован — в 2026 году это почти стандарт, edge-инфраструктура всё чаще строится на контейнерной модели (k3s, micro-k8s), что упрощает обновления и масштабирование распределённых узлов.
В идеале сетевая карта должна поддерживать SR-IOV — это позволяет отдавать виртуальным машинам или контейнерам околофизический сетевой интерфейс с минимальными накладными расходами. Для граничного узла с дефицитом ресурсов такая оптимизация очень полезна.
SR-IOV (сокращение от англ. Single Root Input/Output Virtualization, «виртуализация ввода-вывода с единым корнем») — технология виртуализации устройств, позволяющая предоставить виртуальным машинам прямой доступ к части аппаратных возможностей устройства.
SR-IOV повышает производительность, но усложняет миграцию виртуальных машин (не все гипервизоры корректно его используют, в Kubernetes-сценариях чаще применяют CNI + DPDK), поэтому его стоит применять осознанно — в узлах с фиксированной ролью.
Если площадки распределённые — магазины, филиалы, промышленные объекты, — важна корректная работа с VLAN и более сложными схемами сегментации. В крупных инсталляциях имеет смысл учитывать поддержку EVPN, особенно если используется распределённая фабрика или единая L2-среда поверх L3, хотя для малого и среднего бизнеса обычно хватает классической VLAN-сегментации.
Пропускная способность выбирается строго по задаче. Для телеметрии и базовой аналитики хватает 2 × 1 Гбит/c. Для видеоаналитики и потоковых данных уже можно смотреть в сторону 10 Гбит/c. В ИИ-сценариях и в небольших граничных ЦОДах — 25 Гбит/c, особенно если узел участвует в распределённой обработке данных.

Отдельный архиважный вопрос — резервный доступ. Выделенный LTE/5G-канал часто воспринимают как штуку на всякий случай, но на удалённых площадках — это чуть ли не единственный способ вернуть узел к жизни за адекватное время. Это как запасной игрок в команде — он, может, и не олимпийский чемпион, но довести игру до конца поможет. Или другая аналогия: LTE/5G-канал — это секретный лаз в замок, через который можно пройти во время осады или когда основные ворота закрыты/сломаны, но нужно следить, чтобы лазутчики не пробрались :)
Итак, реализовать LTE/5G-канал можно двумя способами: через внешний промышленный роутер с SIM-картой или через встроенный модем (если платформа поддерживает). Важно не просто наличие канала, а корректный failover (автоматическое переключение при потере основного линка с сохранением доступа к out-of-band aka OOB-управлению).
И наконец последнее (но чуть ли не первое по важности) — удалённое администрирование. IPMI, iDRAC, iLO — необходимость, желательно в максимальной лицензии (как сказал знакомый админ: сэкономил на iDRAC Enterprise — жди 200 выездов). Причём доступ к OOB-интерфейсу лучше выводить в отдельный управляемый сегмент сети и, при возможности, дублировать через резервный канал. На периферии поехать и перезагрузить вручную — это часы простоя (а иногда и дни — при плохой погоде) + дополнительные расходы.
|
Сеть |
||||
|
Параметр |
Минимально |
Для видео |
Для ИИ/Edge ЦОД |
Комментарий |
|
Кол-во портов |
2 × 1 Гбит/c |
2 × 10 Гбит/c |
2 × 10/25 Гбит/c |
Обязательно резервирование |
|
Агрегация |
LACP |
LACP |
LACP |
Повышает отказоустойчивость |
|
OOB-управление |
IPMI/iDRAC/iLO |
Да |
Да |
Критично для удалённых площадок |
|
Доп. канал |
LTE/5G (опц.) |
Желательно |
Желательно |
Резервный доступ |
После того, что я перечислил, думаю ни у кого не возникнет вопросов, что в граничных вычислениях последние поколения серверов, топовые характеристики и комплектующие не так важны, как надёжность, автономность, управляемость и выполнение задач в любых условиях.
Нетипичные ошибки при внедрении граничных вычислений
Все типичные уже понятны из предыдущих разделов статьи. Поэтому я сделаю акцент на неочевидном.
Первая проблема — отсутствие стратегии жизненного цикла. Эдж-вычисления внедряют как пробное или разовое решение, не закладывая горизонт планирования в три–пять лет. Нет унифицированной платформы, нет стандарта по конфигурации, нет сценария плановой замены. Через несколько лет инфраструктура превращается в набор разных поколений узлов с разными прошивками и конфигурациями. Любая замена становится отдельным проектом с согласованиями и доработками вместо штатной процедуры. Старый админ уходит, а новый долго разбирается, как с этим вообще работать.
Вторая ошибка — отношение к граничной инфраструктуре как к прикольному эксперименту (бюджет выделили, повеселимся), а не решению для продакшена. Узлы ставят без нормальной автоматизации, централизованного мониторинга и продуманного управления. Пока их немного — всё нормально. Но при масштабировании все операции ручками начинают занимать кучу человекочасов у IT-команды, при этом сложность будет расти быстрее самой инфраструктуры. Если у вас человеческий ресурс ограничен (а он ограничен), не допускайте эту ошибку. Очень часто эдж-узлы стоят годами, BIOS и какой-нибудь iDRAC не обновляются, а без централизованного управления прошивками через Redfish всё устаревает и становится точкой для кибератак. Или взять резервные копии — так как у эдж-узлов чаще всего нет нормального окна бэкапирования, канала и оператора, нужна отдельная стратегия резервного копирования, часто с локальными снапшотами и асинхронной репликацией в ЦОД.
Ну и важные мелочи, про которые почему-то любят забывать на удалённых площадках. Например, важно физически ограничить доступ к розеткам и оборудованию — значительная часть аварий связана не с железом, а с человеческим фактором (в магазине уборщица случайно выдернула сервер из розетки — сценарий нечастый, но вероятный).
Граничные вычисления работают стабильно только тогда, когда их проектируют как полноценную часть архитектуры, а не как локальный костыль где-то на отшибе. Иначе готовьтесь к сложной поддержке и постоянным доработкам/переделкам.
Заключение
Граничные вычисления — это полноценное архитектурное решение, которое нормально работает и окупается, если его продумывают не менее тщательно, чем основной ЦОД/серверную.
И даже если сейчас собрать правильный сервер, учесть температуру, пыль, влажность, каналы связи, предусмотреть удалённое управление и аварийные сценарии — через годы всё равно можно столкнуться с огромными проблемами. Поэтому важно разработать стратегию масштабирования и жизненного цикла.
Но вот если вы всё стандартизировали, автоматизировали и встроили в общую модель управления инфраструктурой, даже среднее оборудование проработают годами, ведь граничные вычисления — не про максимальную производительность. Они про надёжные решения на месте, которые не зависят облаков, магистральных сетей и ЦОДа.
Спасибо, что прочитали этот лонгрид!
В Сервер Молл вы можете выбрать серверное оборудование для граничных вычислений (и другое) под любую задачу и бюджет. И даже если чего-то нет в каталоге, мы привозим решения под заказ.
У нас бесплатная доставка по всей России, гарантия до 5 лет с выездом инженера, неограниченные консультации с персональным менеджером и КП за час. Пишите в чат на сайте или звоните!
А в комментариях ниже оставляйте отзывы или вопросы по статье — я всё читаю и на всё отвечаю :)





Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение