

Привет постоянным и не очень читателям :)
Сегодня я буду говорить про подбор серверов, но хочу отойти от скучных, быстро устаревающих и зачастую неприменимых на практике рекомендаций — мол, памяти, дорогие админы, надо столько-то, а вот поколение процессора и количество ядер обязательно такие-то, иначе система деградирует после дождичка в четверг.
В этом же лонгриде я затрону ошибки мышления при подборе серверов на 5+ лет и сдвиги, которые произошли за последние годы (и особенно хочу поговорить про огромное влияние CXL). Я плотно работаю в этой индустрии больше 6 лет и прошел подобный цикл на практике, да и админы-старожилы рассказали много интересного о том, что было раньше.
Присаживаемся, ложимся или в какой там позе вы читаете — и начинаем.
Мощный сервер — выбор слабых админов

А сегодня сервер на завтрашний день не все могут подобрать. Вернее, подобрать могут не только лишь все… Ну вы поняли.
Современные серверы буквально напичканы новейшими программно-аппаратными фичами: в начале 2026 года лидеры рынка (Intel, AMD, HPE, Dell, Cisco и другие сбежавшие с нетонущего корабля ребята) поставляют сборки с процессорами на сотни ядер, терабайтами памяти DDR5 с огромной пропускной способностью. Большие и средние корпораты активно щупают технологию CXL 3.2 (Compute Express Link — про эту технологию у меня есть огромный лонгрид на 80 тыс. просмотров и 65 плюсов). Сильно шагнули вперёд и различные проприетарные iDRAC, iLO и другие IPMI/RESTful-подобные технологии для удалённого администрирования. Все хотят монструозные GPU от NVIDIA и AMD, чтобы обучать модели и параллельно отапливать хрущёвки рядом с ЦОДом. А в ближайших дорожных картах вендоров — PCIe 6.0, CXL 4.0 (не исключено, что скоро будем оперативку в облаке арендовать), новые форм-факторы памяти и NVMe. Ах да, не забываем про всякое ASIC-добро и редкие железяки с админских форумов.
Такое бурное развитие идёт не из-за того, что вендоры молодцы — отделы исследований и разработки прокачивают, — а потому что бизнес-задачи и рынки меняются быстрее, чем настроения Илона Маска в интернетах (но это не точно). Вчера про LLM никто ничего не слышал, а сегодня у OpenAI сумасшедшие контракты со всеми техгигантами; капитализация NVIDIA выше ВВП почти всех стран в мире (3-4 место) и т.д.
Даже во времена доткомов инвесторы не тратили ТАК быстро и ТАК много на авантюры, у которых нет устойчивой бизнес-модели. Но ИИ-пузырь я разбирать не буду (и так лонгрид). Но важно обозначить, что LLM-модели перекроили всю индустрию — и даже бедных геймеров задело рикошетом, которые вообще не при делах.
В общем, конкуренция на рынке серверов такая, что сбавишь обороты — и вот уже тебя на повороте обгоняет кто-то помоложе и пошустрее в принятии решений. А так как развивается всё стремительно, то странно собирать сверхмощный, но негибкий сервер в максимальной комплектации. Речь не о том, что производительный сервер — это плохо. Плохо, когда поставщики мощью подменяют понимание задачи. Часто выходит так, что сервер на 5 лет проектируют под нагрузку, которая либо никогда не появится, либо появится уже в другой форме.
И вывод из всего этого простой: в 2026 году, если вы — малый бизнес, нужно смотреть в сторону б/у, восстановленных серверов или облаков; если вы средний или крупный бизнес — нужно подбирать не отдельное устройство, а современную архитектуру из серверов, которую можно адаптировать по ходу дела, не обновляя железо целиком (либо облако, но тогда нужно учитывать нюансы с рентабельностью, конфиденциальностью и управляемостью).
Ну а поскольку моя статья про железо, а не облака, то пора переходить к делу :)
Центральный процессор — больше не центральный компонент

Я неоднократно видел инфраструктуры, где процессоры простаивали, память была забита кэшем страниц и почти всё упиралось в сеть или дисковую подсистему. CPU взяли с запасом, а гибкости нет.
Это происходит, потому что лет 5 назад серверная архитектура почти полностью вращалась вокруг процессоров: выбираешь двухсокетную (и более) платформу с высоким TDP, побольше ядер и кэша, высокую частоту да шину пошире — и всё, любая сборка автоматически становилась мощнее. Но в 2026 году этот подход больше не работает.
Не потому что процессоры остановились в развитии — они-то как раз неплохо прогрессируют: линейка Xeon 6 и актуальные AMD EPYC имеют под капотом теплораспределительной крышкой сотни ядер, 8–12 каналов DDR5 и десятки линий PCIe 5.0, отличную производительность на ватт. Даже ARM-платформы в серверном сегменте больше не экзотика, а конкурентные системы в инфраструктурах гиперскейлеров (вроде Amazon и Alibaba, которые своё железо производят).
Ключевое изменение в том, что процессоры потеряли статус узкого горлышка, вокруг которого строится вся система.
ИИ-обучение, инференс и иже с ними, аналитика, высоконагруженные базы данных, стриминг, SmartNIC (сетевые платы с мозгами), All-flash архитектуры на NVMe — всё это плохо масштабируется, если CPU стоит в центре и через него проходят все данные в системе.
Например, NVIDIA BlueField-4 — это DPU (Data Processing Unit, сопроцессоры для обработки данных) на 800 Гбит/с, который самостоятельно выполняет шифрование, маршрутизацию и прочие сервисные функции.

Сейчас различные DPU и SmartNIC берут на себя ввод-вывод, сетевые и криптографические задачи. А процессор скорее координирует потоки (обрабатывают метаданные и передачу данных) — это позволяет направить все его ресурсы на тяжелые вычисления, вроде виртуализации.
Если раньше лимитом была вычислительная мощность, то сейчас — скорость доставки данных от памяти, дисков, сетей и ускорителей (GPU, FPGA) к процессору и разным точкам инфраструктуры. Это видно даже по маркетингу — Intel и AMD всё меньше говорят про частоты, количество ядер и техпроцессы, и всё чаще — про AI-ускорение (специальные блоки для матричных операций), специализированные ядра (разделение у Intel на мощные «P-ядра» и энергоэффективные «E-ядра»), механизмы разгрузки (перепоручение рутины сетевым картам и контроллерам).
Так что современный сервер в 2026 году — это уже не связка CPU и всего остального, а набор относительно равноправных компонентов (каждый — со своей задачей), где общая производительность системы определяется балансом между процессором, памятью, ускорителями, сетью и вводом-выводом. И если этот баланс нарушен — никакой процессор не спасет.
Поэтому, проектируя сервер на 5+ лет для средней или крупной компании, имеет смысл заранее оставить свободные линии PCIe — под GPU, DPU или SmartNIC, даже если сейчас они не нужны. За последние годы ускорение всё чаще уезжает из CPU в сеть и специализированные устройства, а пропускная способность сети растёт быстрее, чем требования к самим серверам. Возможность перейти на 100–200 Гбит/с Ethernet или использовать InfiniBand и NVLink для GPU куда важнее, чем избыточная производительность на старте.
А теперь пора переходить к самому интересному — оперативной памяти.
Память — больше не самый скучный и дешевый компонент

«Причина, по которой оперативная память подорожала в четыре раза, заключается в том, что огромное количество ещё не произведённой оперативной памяти было куплено на несуществующие деньги для установки в GPU и серверы, которые тоже ещё не произведены, чтобы разместить их в ЦОДах, которые ещё не построены, питаемых инфраструктурой, которая, возможно, никогда не появится, чтобы удовлетворить спрос, которого вообще не существует, и получить прибыль, которая математически невозможна». Неизвестный автор (С).
Итак, локальная DDR5 память в серверах — это всё ещё базовое решение (и будет таковым до 2029–2030 годов, пока не выйдет DDR6). Стандарты и частоты памяти продолжают прогрессировать (например, форм-фактор MRDIMM Gen2 уже в 2026–2027 будет работать на частоте 12800 МГц).
Ремарка! MRDIMM (Multiplexed Rank DIMM) — в отличие от Registered DIMM использует два буфера данных, которые поочерёдно (мультиплексируют) передают данные от двух рангов памяти на контроллер, как по одной широкой магистрали. Это резко снижает нагрузку на контроллер и повышает эффективную частоту.
Но сдвиг индустрии на ИИ привёл к кратному подорожанию DDR5. Раньше память была недорогим расходником, который брали с большим запасом и ещё резервные планки на полочку в серверную закупали. Сегодня её считают строго под нагрузку (берут только минимальный резерв под рост и пиковые нагрузки в 20-30%, а иногда и этого не делают), ищут способы максимальной утилизации через виртуализацию и т.п.
На начало 2026 года закупать запасную память с избытком либо невозможно из-за пустых стоков, либо экономически невыгодно. Компании перезаключают контракты, фиксируют поставки заранее и идут на снижение текущей прибыли, чтобы распределить закупку дорогого нового железа на годы (они платят больше сейчас, но гарантируют себе поставки и стабильную цену в будущем). Причём выбирать поставщиков приходится из крупных OEM (Dell, Lenovo, HPE, Supermicro и др.), так как покупая не из списка совместимого железа, можно получить несовместимые компоненты. Сэкономить на производителях второго эшелона получится далеко не у всех.
И как тогда выкручиваться с памятью? Если честно — никак, переждать, пока всё успокоится. Но есть способ немного облегчить себе жизнь.

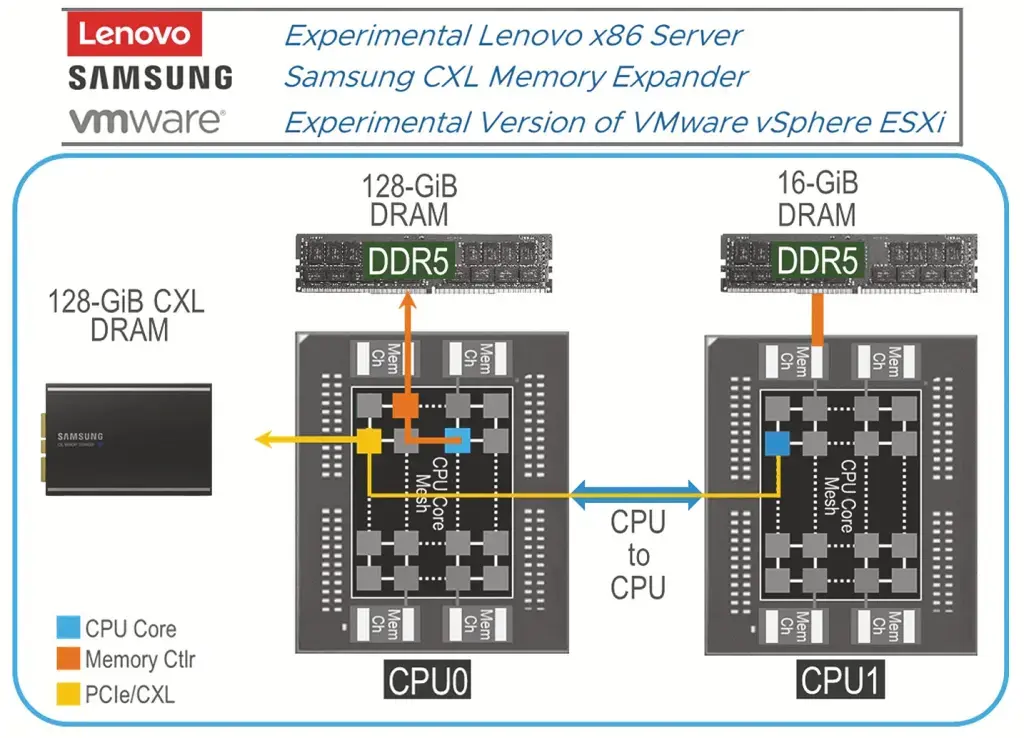
Выше я уже писал про CXL — это интерконнект для объединения памяти CPU и внешних устройств. Он использует физическую и электрическую основу PCIe, а сверху предлагает слой из своих протоколов. Эта технология позволяет расширять память в форм-факторах, отличных от DIMM, например DRAM или PMem в виде накопителей EDSFF E1.S или E3.S. Дополнительные платы можно вставлять в стандартные слоты PCIe, и они могут поддерживать стандартные модули DIMM (это значит, что CPU и GPU даже в разных серверах и в разных стойках могут работать с одними и теми же согласованными данными в общей памяти без копирования).
Если использовать CXL, то можно построить гибридную модель — локальная память в сервере + когерентная через CXL. И это почти так же быстро для прямого доступа, как локальная ОЗУ, но легче масштабируется. И если грамотно спроектировать, получите максимальную утилизации памяти (и экономию) — даже ниже, чем при виртуализации, так как нет дополнительных уровней абстракций.

Крупные поставщики уже во всю внедряют CXL в свои массовые продукты: например, Dell PowerEdge R7725 на базе AMD EPYC (5-е поколение) поддерживает CXL 2.0 Type 3 для подключения расширителей памяти. Это позволяет масштабировать объём ОЗУ сверх локальной — полезно для in-memory БД или AI/ML, где требуется огромный объём памяти.
На этом влияние CXL не заканчивается — но сначала пара слов про PCIe.
Переходите на PCIe 5.0, чтобы работать с DDR4

Звучит парадоксально, но сейчас объясню.
В технологиях интерконнектов всё спокойно — PCIe используют везде и раз в N лет выпускают новую спецификацию. Стандарт PCIe 6.0 в ЦОДах уже есть в некоторым продуктах, вроде GPU Nvidia Blackwell, но массовых платформ в проде нет (ускорители часто работают в режиме 5.0), а в потребительском сегменте распространение ожидается лишь к 2030-м годам. Однако PCIe 5.0 уже везде и предлагает отличную пропускную способность. Что тогда не так?
Во-первых, на практике бывают ситуации, когда сервер с PCIe 5.0 проигрывает старой системе на PCIe 4.0 — просто потому, что GPU и NVMe сидят за неудачным PCIe-свитчем или делят линии с сетевыми картами. Версия стандарта в таких случаях вторична — важнее, как именно разведены линии внутри шасси.
Во-вторых, многие компании с серверами на PCIe 4.0 и DDR4 (например, Dell PowerEdge R750 — прекрасный сервер конца 2021-начала 2022 гг., актуален сегодня) не спешат обновляться — ждут массового внедрения и удешевления PCIe 6.0, чтобы сразу перепрыгнуть туда. А ту же DDR4 поставить в материнскую плату Dell R760 или любого другого современного сервера нельзя.
Но что если я вам скажу, что с помощью CXL можно поставить DDR4 в новый сервер? Напомню, что это технология дезагрегации памяти (нет привязки к серверу), а значит вы можете не просто установить DDR4, но и комбинировать старую и новую версии (CXL-память не обязана совпадать по типу с локальной).
ВАЖНО! Речь, разумеется, не о DIMM в материнской плате, а о CXL-устройствах памяти (Type-3 — это чистые расширители памяти без вычислительных блоков), которые живут вне NUMA-домена процессора.

Marvell Structera A CXL
Крупные ЦОДы уже подключают в CXL-шасси ранее списанную DDR4-память через CXL-контроллеры (например, Marvell Structera). По сути можно не терять деньги из-за дискардинга существующих DIMM, а собирать из освободившихся планок пул, который будет перераспределяется между узлами динамически.
Ремарка! Дискардинг (от англ. discard — отбрасывать) — это выбрасывание ещё рабочей памяти ради освобождения слотов. Классический пример:
-
У вас есть сервер А с 512 ГБ памяти и сервер Б с 256 ГБ памяти.
-
На сервере А началась пиковая нагрузка, и ему срочно нужно ещё 128 ГБ.
-
На сервере Б нагрузка низкая, и 100 ГБ памяти там простаивают.
В классической архитектуре сервера — или даже кластера без memory pooling — вы не можете просто взять 100 ГБ у сервера Б и отдать серверу А на уровне аппаратной памяти. Единственный способ дать серверу А больше памяти — докупить и физически установить в него новые планки памяти. А старые, менее ёмкие модули, придётся выбросить/списать/продать (дискардить), чтобы освободить слоты.
CXL — хорошее решение, но несмотря на низкие задержки не заменяет локальную, так как они на десятки процентов выше, чем у DDR5 в материнской плате (в зависимости от реализации и глубины стека). Поэтому комбинации CXL с DDR4 используют как ёмкий общий пул памяти, а не как быстрый NUMA-ресурс. Чувствительные к задержкам задачи лучше оставлять для локальной ОЗУ.
Вывод такой: при проектировании инфраструктуры, если хотите работать с CXL, нужно смотреть на оборудование с PCIe 5.0 и новее (PCIe 4.0 — не поддерживает). И надо читать спецификации этих серверов, чтобы убедиться в поддержке CXL-устройств (Type-3).
Не самый очевидный эффект CXL — продление жизненного цикла инфраструктуры. С ним вы можете покупать серверы, CPU и память на сейчас (занимая все слоты), а объём памяти наращивать позже без дискардинга (хотите DDR4, хотите — DDR5). Пока это история чаще практикуется в крупных ЦОДах и HPC-площадках, но именно оттуда такие технологии и спускаются в массовый сегмент. Чего и вам желаю.
Хранение и NVMe — это не про скорость, а про архитектуру
Когда-то логика была простой: SATA — медленно, SAS — нормально, NVMe — быстро. С HDD и SSD аналогично.
Но сейчас NVMe — это не просто быстрый SSD. Теперь это способ организации ввода-вывода. И здесь срабатывает классическая ошибка мышления: кажется, что если набить сервер локальными NVMe, он дольше проживёт и будет шустрее работать. На практике выходит наоборот — локальные NVMe привязывают данные к конкретному серверу. Со временем это ломает горизонтальное масштабирование, усложняет апгрейд поколений и отбирает PCIe-ресурсы у более приоритетных задач — в итоге быстрые диски превращаются в дорогой балласт, которому сложно найти применение.
Сейчас все стараются агрегировать и выносить хранение данных: NVMe-oF, внешние полки, программно-определяемые хранилища. Надо потихоньку быстро привыкать к тому, что сервер — не хранилище (если мы не про СХД говорим), а вычислительный узел, который берёт данные на обработку извне. Такая архитектура проживет дольше.
Сервер не должен знать, кем он станет (и вы тоже)

Dell PowerEdge R7725xd
Самый надёжный способ сократить срок жизни сервера — жёстко определить его судьбу на этапе закупки. Никто не знает, что будет с оборудованием через четыре года: оно может стать узлом виртуализации или частью гиперконвергентной системы (HCI), сервером под базу данных, edge-узлом, а может — рабочей нодой под Kubernetes или просто универсальным офисным сервером. А может и страшно устареть — зависит от исходных параметров.
Малый и средний бизнес обычно возражает, мол, мы небольшие, нам хватит одного производительного сервера, ну максимум двух в кластере — зачем усложнять? Проблема в том, что именно такие (раз и навсегда) конфигурации обычно хуже переживают смену задач.
Универсальный сервер — это не швейцарский нож со всем и сразу, а система, способная менять роли без изменения архитектуры. Стандартные форм-факторы, предсказуемые платформы HPE, Dell, Lenovo, Supermicro, Huawei, характеристики компонентов без перекосов — вот что продлевает жизнь сервера, а не попытки админа угадать будущее.
А вот экзотика работает против вас: редкие бэкплейны под один конкретный тип NVMe, нестандартные PCIe-райзеры, привязка к специфическим сетевым картам или контроллерам, которые поддерживаются только в одном поколении серверов и/или у одного производителя. Пока задача совпадает с задумкой админа — всё отлично. Как только сценарий меняется (а админ меняет место работы), такой сервер либо сложно апгрейдить, либо приходится пересобирать его почти с нуля из б/у комплектующих с Авито.
Чем жёстче сервер специализирован на этапе закупки, тем быстрее он устареет. Но специализировать сервер под задачу тоже важно — поэтому нужен баланс.
Выводы
Собрать максимально мощный сервер на пять лет вперёд — так себе идея. Аппаратные требования и рынок в целом меняются быстрее планов, а прогнозы спецов по сценариям использования часто не совпадают с реальностью в горизонте 5 лет.
По-настоящему устойчивой инфраструктуру делает не пиковая производительность, а гибкость архитектуры. Возможность менять роль сервера, перераспределять ресурсы, масштабироваться без полной переделки и не привязываться к одному сценарию — всё это важнее любых попыток угадать будущее. Да, несколько гибких серверов — в кластере или без — не гарантируют, что всё будет работать много лет без проблем, но пережить ошибки планирования будет легче и дешевле.




Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение