

Админ высоконагруженной системы
Привет!
В первой части статьи мы рассмотрели аппаратные аспекты построения высоконагруженных систем (ВНС). Если вы попали сюда из поиска, пропустив первую часть, то, конечно, стоит изучить и её — так будет легче вникнуть в тему.
Какие-то понятия я буду вскользь повторять, по возможности ссылаясь на себя, но в целом я рассчитываю на то, что читатель уже проделал домашнюю работу и прочёл первую часть (благо там не так много).
Итак, пора углубиться в программные решения (софт от англ. software), которые позволяют хайлоад системам справляться с огромными объёмами данных, работать с высокими показателями отказоустойчивости, доступности и производительности.
Современные ВНС требуют от программной архитектуры гибкости, масштабируемости и надёжности. Есть разные подходы и инструменты для достижения этих целей — давайте разбираться.
Горячительные напитки приветствуются — информации будет ОЧЕНЬ много. И сразу скажу, в статье упор на практики, а не на теорию ВНС — по ней я пройдусь вкратце :)
Ремарка! Статья рассчитана на IT-специалистов, которые знают, что такое серверы, кластеры, сети и как они устроены. Если вы не сисадмин со стажем, то кое в чём придётся разобраться. Но мы всё же не изопериметрические неравенства в математической физике разбираем — статью осилит любой с википедией (и первой частью) под рукой.
Основные принципы проектирования ПО для высоконагруженных систем
 Ну что, народ, погнали…
Ну что, народ, погнали…
Перед практическими принципами и советами по проектированию ВНС важно затронуть теорию. По теме есть отличная книга Вадима Подольного “Архитектура высоконагруженных систем” — сотни страниц отборной полезнейшей информации. Я, конечно же, снимаю шляпу перед коллегой, но сделаю “чуть” покороче, а потому на исчерпываемость материала не претендую, но для общего понимания и для формата статьи этого достаточно :)
Итак, самое важное — данные, метаданные (не те, что запрещены в России) и события.
Любая высоконагруженная система становится такой, потому что стабильно и предсказуемо обрабатывает огромные потоки данных, метаданных и событий; потоки эти поступают как извне, так и изнутри самой системы.
Что такое данные, вы знаете и без меня: файлы, текст, изображения и т.д. То есть это информация (двоичный код в нашем случае) представленная в таком виде, чтобы система (пользователь тут не обязателен) могла взаимодействовать с ней: передавать, обрабатывать, просматривать, хранить.
Метаданные — это информация о данных, например, фотография — это данные; а информация о фотографии, такие как дата создания, место, автор, размер и тип — это описательные метаданные.
События — это действия или изменения состояний системы, которые происходят в конкретный момент времени. Они фиксируются как факты и отражают активность системы, пользователя или внешних процессов. Пример события: “Пользователь авторизовался” или “Сервер недоступен”. События отличаются от данных и метаданных тем, что они не только фиксируются, но и могут запускать определённые действия (триггеры). Например, при событии “Сервер недоступен” запускается действие “Уведомление системного администратора”.
События можно поделить на 3 основных типа:
-
Асинхронные события — невозможно предсказать заранее. Могут происходить в любой момент и не имеют чёткой временной привязки. Примеры: сигналы о неисправностях оборудования, входящие запросы от пользователей в системе, оповещения безопасности.
-
Синхронные события — происходят регулярно, их можно ожидать заранее. Примеры: обновление информации о пользователях в системе, синхронизация баз данных каждую ночь в 3 часа утра и т.п.
-
Изохронные события — это подвид синхронных событий со строгим соблюдением временных интервалов. Такие события происходят в чётко заданные промежутки времени. Примеры: диагностические тесты каждые 10 секунд для проверки состояния серверов, отображение времени на экране каждую секунду и т.п.
Все эти данные и события можно обрабатывать либо с минимальными дедлайнами в реальном времени (РВ) — занимаются этим системы реального времени (СРВ), — либо в варианте нормального времени (где нет требований к режимам РВ). Дедлайн состоит из двух показателей: первый — максимальное время, в течение которого должна быть завершена операция; второе — латентность в виде задержки при получении отклика.
Если дедлайны строгие, то систему с точки зрения РВ можно назвать критичной или “системой жёсткого РВ”, ниже в иерархии идут среднекритичные, они же просто “системы РВ” или “системы псевдо-РВ”, там дедлайны могут иметь задержки.
ВАЖНО! Системы реального времени, критичные или среднекритичные, требуют разделения режимов обработки данных. Обрабатывать все данные, метаданные и события в режиме жёсткого РВ нерационально — такой подход гарантирует перерасход ресурсов. Многим основным данным, а также событиям нужна временная привязка и дедлайны для оптимизации системы. И в обратную сторону это тоже работает — некоторые вспомогательные высокочастотные метаданные неплохо бы обрабатывать в РВ.
Например: в системах бэкапирования данных задержка допустима, если данные копируются на сервер в фоновом режиме. Это не влияет критически на работу системы, но для завершения операции требуется время.
Ну а системы обычного / нормального времени без строгих ограничений на временные рамки обработки задач могут быть частью ВНС, если они настроены и оптимизированы для выполнения задач под высокой нагрузкой. Но здесь важно, что именно частью, а не её ядром, так как при экстремальных перегрузках поведение таких систем невозможно предсказать: деградация происходит нелинейно — иногда мгновенно. Но в целом они способны выдавать огромную производительность в любых задачах при грамотном проектировании, а потому отлично выступают в роли узлов ВНС.
Подытожу. Чтобы проектировать стабильные, производительные и предсказуемые ВНС (даже под экстремальными нагрузками) нужно учитывать тип и источник данных, а также оптимизировать их обработку, хранение и передачу. Данные должны быть доступны в нужное время, но обработка может быть приоритизирована.
Метаданные помогают эффективно структурировать данные, определять их приоритеты и маршруты обработки. Например, при загрузке файлов система может сначала извлекать и обрабатывать только ключевые метаданные, что снижает нагрузку на основные сервисы.
События — это "нервная система" ВНС. Они позволяют системе реагировать на изменения как внутри неё самой, так и извне. Корректное проектирование событийного взаимодействия (с учётом их типов — асинхронные, синхронные, изохронные) позволяет достигать высокой производительности и устойчивости.
Использование систем реального времени (СРВ) с учётом их критичности позволяет оптимизировать ресурсы. Например, события с высоким приоритетом (вроде сигналов об отказе) обрабатываются в режиме жёсткого РВ, тогда как менее критичные задачи могут выполняться асинхронно. Разделение задач на критичные и некритичные позволяет системе избегать перерасхода и снижать затраты на ресурсы.
На этом я буду закругляться с базовой теорией, ибо погружаться можно долго — и дно у этой марианской впадины едва ли найдено :)
Переходим к практическим методам и инструментам.
Мониторинг, протоколирование и наблюдаемость в ВНС

Два столпа, без которых стабильная работа, быстрое обнаружение и устранение проблем в ВНС невозможны — мониторинг и протоколирование. Разберу процессы по отдельности.
Мониторинг ВНС

Мониторинг — это сбор, анализ и визуализация данных о состоянии всех её компонентов. Основные метрики, которые нужно отслеживать:
-
Производительность: время отклика, пропускная способность, количество запросов в секунду.
-
Использование ресурсов: загрузка процессора, потребление памяти, использование сетевых интерфейсов.
-
Состояние баз данных: количество активных соединений, время выполнения запросов, размер индексов.
Мониторинг позволяет не только выявлять узкие места, но и прогнозировать возможные проблемы, реагировать на них превентивно: увеличение количества серверов, аппаратный апгрейд или оптимизация алгоритмов. Также есть решения для мониторинга производительности приложений (Application Performance Monitoring, APM).
Для мониторинга используют следующие инструменты:
|
Zabbix — система мониторинга с широкой функциональностью для сбора метрик, уведомлений и визуализации. |
|
Prometheus — система для сбора метрик и их хранения в виде временных рядов. |
|
Grafana — платформа для визуализации метрик и создания дашбордов. |
|
Datadog или New Relic — комплексные решения для мониторинга приложений и инфраструктуры. |
|
MONQ от Monq Digital Lab – платформа корпоративного ИТ-мониторинга нового поколения, которая предназначена для отслеживания здоровья и предотвращения сбоев инфраструктуры и бизнес-сервисов. Входит в Единый реестр российских программ для ЭВМ Минцифры России и подходит для импортозамещения. |
Протоколирование ВНС
Протоколирование (логирование) — это запись событий, происходящих в системе. В основном это:
-
Ошибки и сбои. Например, сообщения об исключениях в коде или сбоях в базах данных.
-
Действия пользователей. Логи могут фиксировать входы, запросы, изменения данных.
-
Технические события. Запись состояния систем, запросов между микросервисами, выполненных задач.
Настройка мониторинга и логирования — это не разовая задача, а непрерывный процесс. Здесь важно понимать: цель — не просто настроить систему, а выстроить такой процесс, который будет развиваться вместе с инфраструктурой.
Прежде всего определите ключевые метрики, связанные с бизнес-целями. Например, уровень конверсии или среднее время отклика системы дают ценную информацию о том, насколько эффективно работает инфраструктура. Однако это только начало.
Работа с алертами — сложный процесс; их задача — уведомлять команду о критических событиях. Но если перегрузить он-колл команду лишними алертами, можно потерять важные сигналы в шуме. Важно соблюдать баланс: система должна быть чувствительной, чтобы выявлять проблемы, но не должна перегружать разработчиков бесполезными уведомлениями.
Логи — ключевой инструмент. Стандартизация их формата (например, в JSON) облегчает последующую обработку и анализ. Однако и здесь важно стремиться к минимализму: собирать только то, что действительно необходимо, избегая лишнего «информационного мусора».
Этот процесс похож на «дао» в ИТ: это не про цель, а про путь. Совершенствуйте систему мониторинга постоянно. После каждого инцидента, особенно пропущенного, находите способы улучшить сбор данных, настройки триггеров и интерпретацию логов. И именно этот путь сделает вашу инфраструктуру надёжной, а команду — спокойной.
И ещё про спокойствие: не забывайте о бэкапах логов и событий. Хранение архивов за определённый период может стать спасением при расследовании инцидентов (а ещё может быть требованием регуляторов). Архивы помогают восстановить хронологию событий, анализировать поведение системы и учиться на ошибках.
Для логирования в ВНС использует следующие технологии:
|
ELK-стек (Elasticsearch, Logstash, Kibana): позволяет собирать, хранить и анализировать логи, а также создавать удобные визуализации. |
|
Fluentd: инструмент для агрегации логов из различных источников. |
|
Loki: специализированное решение для работы с логами от создателей Grafana. |
|
СОВА (Система Обнаружения и Визуализации Аномалий) — инструмент для анализа логов и поиска отклонений в работе систем. Входит в Единый реестр российских программ для ЭВМ Минцифры России и подходит для импортозамещения. |
Важность наблюдаемости (Observability Engineering) в ВНС — мониторинг 2.0

Современные подходы к мониторингу выходят за рамки простого отслеживания метрик. Сегодня в тренде наблюдаемость (observability).
Наблюдаемость — это подход к проектированию и управлению системами, позволяющий лучше понимать, как система работает, и быстро находить причины любых сбоев или проблем. По факту это комплексный сбор данных из метрик, логов и трассировок запросов; наблюдаемость позволяет детально изучать поведение системы и быстро находить причины сложных проблем.
Ремарка! Трассировка (от англ. tracing) — это процесс отслеживания пути запроса или операции через компоненты системы. Простыми словами, это как "лог путешествия" данных от начала до конца: кто и где обрабатывал запрос, сколько времени это заняло, и где могли возникнуть задержки или сбои. Когда запрос поступает в систему, ему присваивается уникальный идентификатор (trace ID). На каждом этапе обработки этот идентификатор передаётся между компонентами, которые записывают данные о времени, действиях и результатах. Всё это собирается в единую цепочку событий — трассу.
Пример: запрос через API занял 120 мс на сервере и 400 мс в базе данных.
Трассировка поможет найти узкие места в системе и компоненты, которые замедляют остальные (что критично в ВНС), поможет найти точное место сбоя. С ней намного легче точечно оптимизировать крупные и даже распределённые системы.
Наблюдаемость в целом отвечает на вопрос: "Почему что-то произошло в системе?", в то время как мониторинг отвечает на вопрос: "Что произошло?". Представьте, что ваш сервер показывает рост времени отклика. Мониторинг с помощью Grafana укажет: "Среднее время отклика увеличилось до 500 мс". С помощью трассировок в Jaeger или анализа логов через Elasticsearch вы выясняете: "Время отклика увеличилось из-за ошибки в базе данных, вызванной запросом с большим количеством соединений"
|
Отличие наблюдаемости от мониторинга: | ||
|
Критерий |
Мониторинг |
Наблюдаемость |
|
Цель |
Слежение за метриками и состоянием системы. |
Понимание внутреннего состояния системы через внешние сигналы. |
|
Основные вопросы |
"Что случилось?" |
"Почему это случилось?" |
|
Подход |
Настраиваются конкретные метрики и алерты. |
Система проектируется так, чтобы можно было анализировать её работу. |
|
Инструменты |
Prometheus, Grafana, Nagios. |
ELK-стек, OpenTelemetry, Jaeger, Honeycomb. |
|
Тип данных |
Метрики (CPU, память, задержки, число запросов). |
Логи, трассировки запросов, метрики (комплексный анализ). |
|
Фокус |
Статус системы (здорово/сломано). |
Диагностика и выявление причин проблем. |
Чтобы выжать максимум из системы наблюдаемости, начните с выбора инструментов, которые "дружат" между собой. Например, платформа вроде OpenTelemetry отлично справляется с объединением трассировки, метрик и логов в единую экосистему. Дальше важно позаботиться о том, чтобы все собираемые показатели работали в связке: метрики, трассировки и логи должны "говорить на одном языке", чтобы вы могли быстро понять, почему и где произошёл сбой. Ну и не забывайте о визуализации — никто не любит копаться в сухих цифрах. Настройте дашборды и диаграммы, которые наглядно покажут, как ваша система дышит, и позволят оперативно заметить проблемы.
Таблица технологий для мониторинга, логирования, трассировки и наблюдаемости ВНС в целом:
|
Функция |
Примеры софта |
|
Мониторинг метрик |
Prometheus, Datadog, Zabbix, VictoriaMetrics (популярная альтернатива Prometheus, разработанная российскими инженерами), Monq |
|
Визуализация метрик |
Grafana |
|
Трассировка |
Jaeger, Zipkin, Moira (система оповещений на базе Graphite, поддерживает интеграцию с Zabbix и Grafana) |
|
Централизация логов |
ELK-стек (Elasticsearch, Logstash, Kibana), Fluentd, Loki, ClickHouse (СУБД, которую используют для хранения и анализа больших объёмов логов, часто с интеграцией в экосистему ELK) + Vector + Grafana, СОВА |
|
Аналитика событий |
Splunk, Sumo Logic |
|
Объединённые платформы наблюдаемости |
OpenTelemetry, New Relic, Dynatrace, GMonit (в реестре отечественного ПО Минцифры), Sage (платформа наблюдаемости с AI от Т-Банка). |
Масштабируемость высоконагруженных систем

Масштабируемость — это адаптация к увеличению нагрузки через добавление новых ресурсов в систему. В случае высоконагруженных систем справляться с растущей нагрузкой нужно правильно: без простоев (то есть без остановки работы), деградации производительности и перерасхода ресурсов.
Итак, есть три подхода — горизонтальное, вертикальное и комбинированное масштабирование. А допом ещё и динамическое, но об этом ниже.
Горизонтальная масштабируемость — увеличение производительности системы за счёт добавление новых узлов (нод) — серверов, СХД, коммутаторов, баз данных, операционных систем — к уже существующим. Этот подход эффективен в облачных средах, где можно динамически запускать дополнительные ресурсы.
Вертикальная масштабируемость — увеличение производительности системы за счёт добавления ресурсов в существующие узлы. Это как апгрейд ПК: вы просто добавляете больше памяти, процессоров (или более мощные процессоры) и ускоряете хранилище (или наращиваете его объём). Простое решение, но с потолком: каждый сервер имеет лимит, бесконечно его масштабировать невозможно.
Гибридное масштабирование — ключевые узлы системы масштабируют вертикально, а второстепенные — горизонтально. Например, база данных может работать на мощных серверах, а веб-сервисы масштабируются через добавление новых инстансов. В общем, определяют, что лучше для конкретной архитектуры, и масштабируют выборочно разными подходами.
В идеале масштабирование должно быть автоматическим (происходит по заданным заранее параметрам и триггерным событием), а ещё лучше — динамическим.

Динамическое масштабирование — широкое понятие, охватывающее и автоматическое, и ручное изменение инфраструктуры (зависит от требований), при этом включает в себя планирование и стратегию.
|
Критерий |
Автомасштабирование |
Динамическое масштабирование |
|
Автоматизация |
Полностью автоматизировано |
Может быть как автоматизированным, так и ручным |
|
Реакция на нагрузку |
Реакция в реальном времени |
Может включать стратегическое планирование |
|
Сценарии применения |
Увеличение/уменьшение подов*, инстансов |
Расширение кластеров, изменение архитектуры |
*Под aka Pod — это основная единица диспетчеризации, которая может включать в себя один или несколько контейнеров. Все они гарантированно находятся на одном хосте и могут совместно использовать его ресурсы.
Например, Kubernetes умеет добавлять или убирать ресурсы с учётом текущей нагрузки. Это особенно важно для ВНС, где пиковые нагрузки могут меняться за секунды. Правда и пул ресурсов, из которых ПО будет выделять их подсистемам, должен быть значительным.
Пример масштабирования в высоконагруженной системе
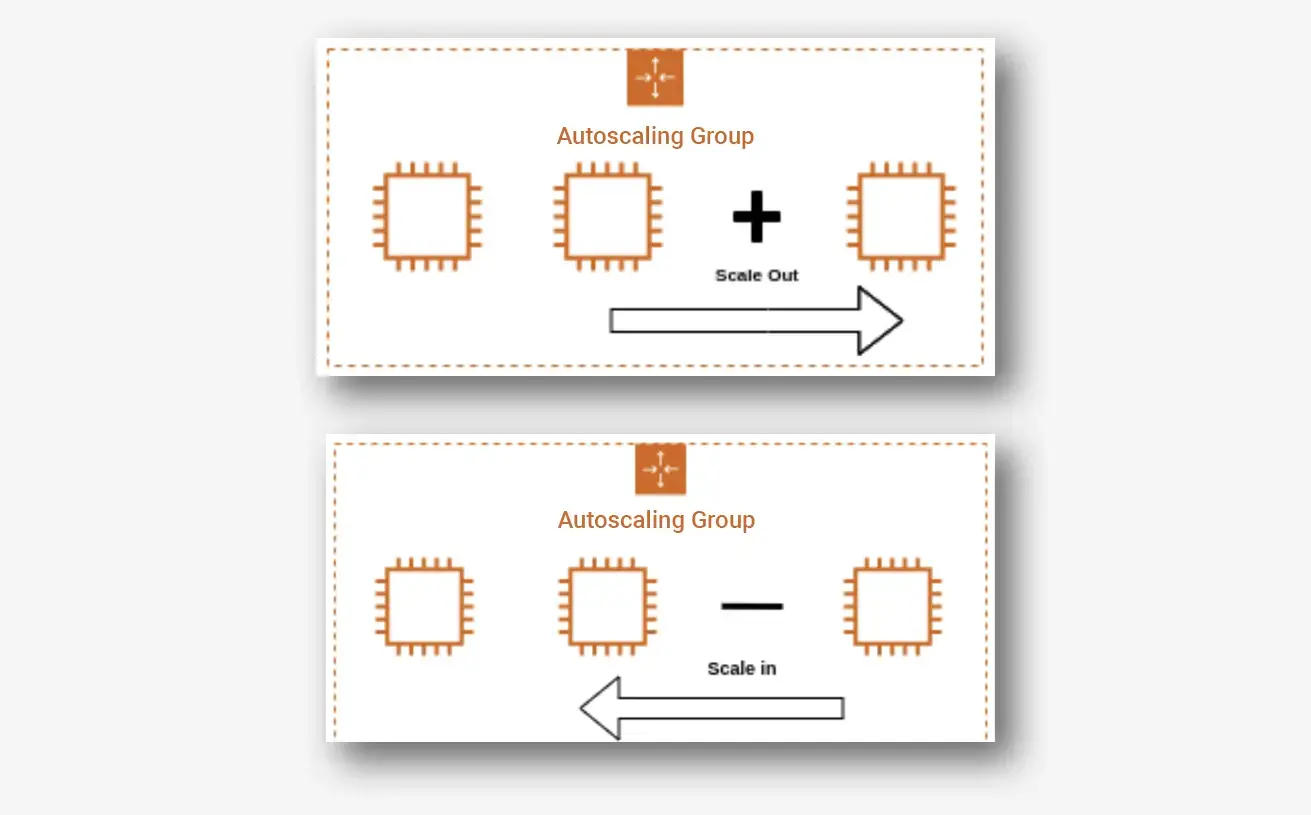
Представьте себе крупную социальную сеть, которая сталкивается с переменными нагрузками в течение дня, недели и месяца. Система, на которой эта соцсеть работает, построена по следующему принципу
-
Фронтенд-сервисы: отвечают за взаимодействие с пользователями, рендеринг страниц, обработку пользовательских запросов.
-
Бэкенд-сервисы: обеспечивают логику обработки данных, взаимодействия с базой данных, кэшированием и другими операциями.
-
Хранилище данных: база данных, использующая реляционные СУБД и NoSQL решения для хранения информации.
-
Система аналитики: собирает метрики и статистику для анализа поведения пользователей и оптимизации платформы.
Вертикальное масштабирование можно проводить на уровне бэкенда и хранилища данных: увеличение количества ядер процессора, добавление оперативной памяти, улучшение дисковой подсистемы (например, переход на SSD). Но рано или поздно мы упрёмся в потолок возможностей серверов.

Горизонтальное масштабирование можно применить к фронтенду и некоторым бэкенд-сервисам. Можно добавить как новые физические серверы, так и контейнеры: сервис аутентификации можно развернуть на нескольких серверах/контейнерах, чтобы обрабатывать больше одновременных входов.
Если использовать оба подхода выборочно, то получим гибридное масштабирование — правильный подход, к которому и нужно стремиться. А если перевести часть процессов в автоматику, разработать стратегию, то получим ещё и динамическое масштабирование:
-
Мониторинг нагрузки или наблюдаемость: постоянный сбор метрик о состоянии системы (загрузка CPU, память, число активных соединений и т.д.).
-
Автоматическое масштабирование: на основании собранных данных система принимает решение о добавлении или удалении ресурсов. Например, если нагрузка на фронтенд-сервисы превышает определенный порог, автоматически создаются новые экземпляры этих сервисов через Docker или Kubernetes. Или же нагрузка на базу данных слишком высока, тогда можно увеличить количество узлов в кластере.
-
Автоскейлинг: после снижения нагрузки система автоматически уменьшает количество используемых ресурсов, освобождая ненужные серверы или контейнеры. Позволяет гибко настраивать объём вычислительных мощностей в серверной инфраструктуре. Этот процесс происходит автоматически и зависит от текущей нагрузки на систему.
Инструменты для масштабирования в высоконагруженных системах
|
Категория |
Инструмент / Технология |
Описание |
|
Оркестрация контейнеров |
Kubernetes |
Система оркестрации контейнеров с автоматическим развёртыванием, масштабированием и управлением. |
|
|
Docker Swarm |
Инструмент оркестрации контейнеров от Docker, упрощённый в использовании, подходит для небольших кластеров. Доступен из коробки, если у вас есть Docker. |
|
|
OpenShift |
Платформа для контейнерных приложений на основе Kubernetes с улучшенными возможностями управления и CI/CD. |
|
Автомасштабирование |
AWS Auto Scaling |
Сервис от Amazon Web Services для автоматического масштабирования ресурсов на основе нагрузок и метрик. |
|
|
Google Kubernetes Engine (GKE) |
Встроенное автомасштабирование Kubernetes-кластеров на облачной платформе Google Cloud. |
|
|
Horizontal Pod Autoscaler (HPA) |
Инструмент Kubernetes для автоматического увеличения числа подов на основе нагрузки и ресурсов. |
|
Распределённые базы данных |
Apache Cassandra |
Высокодоступная распределённая база данных NoSQL, подходящая для больших объёмов данных и горизонтального масштабирования. |
|
|
MongoDB |
Популярная NoSQL база данных с поддержкой репликации и шардирования для масштабирования. |
|
|
CockroachDB |
Современная распределённая SQL-база данных с автоматическим масштабированием и отказоустойчивостью. |
|
|
Amazon DynamoDB |
Amazon DynamoDB — это управляемый сервис баз данных NoSQL, предоставляемый Amazon Web Services (AWS). |
|
Динамическое масштабирование |
Terraform |
Инструмент для автоматического создания и управления инфраструктурой с динамическим масштабированием. |
|
|
Ansible |
Средство управления конфигурацией с возможностью динамического управления ресурсами. |
Для создания масштабируемой архитектуры необходимо провести предварительное тестирование нагрузки, подобрать подходящие инструменты и постоянно анализировать и корректировать архитектурные решения
Отказоустойчивость высоконагруженных систем
 Пылающий дата-центр OVH SBG2 в Страсбурге
Пылающий дата-центр OVH SBG2 в Страсбурге
Отказоустойчивость — это способность системы сохранять работоспособность и минимизировать влияние сбоев на пользователей. Для высоконагруженных систем это критический фактор: любое нарушение может привести к простою, потерям данных и финансовым убыткам. Поэтому архитектура таких систем должна быть спроектирована так, чтобы обеспечивать:
-
Высокую доступность (High Availability, HA);
-
Минимизацию времени восстановления (Recovery Time Objective, RTO);
-
Минимальные потери данных (Recovery Point Objective, RPO).
Итак, в отказоустойчивости можно выделить три ключевых подхода: репликация, кластеризация и план восстановления. А также важны вышеупомянутые мониторинг, наблюдаемость и прогнозирование.
Репликация в ВНС

Репликация — это способ дублировать данные или процессы, чтобы они были доступны в нескольких местах одновременно. Это нужно, чтобы система продолжала работать, даже если что-то пойдёт не так с одной из копий. Её применяют для баз данных, файлов и приложений; и нередко используют, если система плохо горизонтально масштабируется (классические СУБД). Например, может быть одна или несколько реплик readonly — для отчётов, поиска и т.п
Типы репликации:
-
Синхронная репликация — данные записываются на все реплики одновременно. Гарантирует консистентность данных, но увеличивает задержки.
-
Асинхронная репликация — данные записываются на главную реплику, а затем на резервные. Быстрее, но может привести к временной неконсистентности.
Примеры:
-
Репликация в MySQL (Master-Slave, Master-Master);
-
Реализация в распределённых системах, таких как MongoDB или Apache Cassandra;
-
Использование облачных решений, например, Amazon RDS или Azure SQL, где репликация встроена изначально.
Кластеризация в ВНС

Кластеризация — это объединение нескольких серверов в одну группу. Если один из них выходит из строя, его работу автоматически берут на себя другие, чтобы система продолжала работать без перебоев.
Типы кластеров:
-
Активный/пассивный кластер — один узел обрабатывает запросы, остальные находятся в режиме ожидания.
-
Активный/активный кластер — все узлы работают одновременно, обрабатывая запросы. Это обеспечивает высокую производительность и отказоустойчивость.
Примеры:
-
Использование Kubernetes для автоматического перераспределения подов;
-
Кластеры баз данных, например, PostgreSQL с Patroni;
-
Балансировка нагрузки через HAProxy или AWS Elastic Load Balancer.
План восстановления после сбоев и катастроф (Disaster Recovery Plan, DRP)

Сбои случаются даже в идеально (хотя таких нет) спроектированных системах, поэтому без плана восстановления не обойтись. Про это в нашем блоге есть отдельная подробная статья “Disaster Recovery — быстро поднятое упавшим не считается”. К прочтению обязательно, можно считать частью этой статьи, поэтому подробно расписывать не буду.
Цитата:
“Disaster Recovery (DR) — катастрофоустойчивость или аварийное восстановление, инструмент реагирования на критические сбои в IT-инфраструктуре компании, направленный на быстрое восстановление работы всех систем. То есть отказ серверной или даже всего ЦОДа не должен надолго (в отдельных случаях речь о секундах) прерывать бизнес-процессы.
Реализация DR основана на управлении рисками (анализ, оценка, нужен ли вообще план восстановления, планирование). Один из вариантов — дублирующая инфраструктура, способная взять на себя всю нагрузку, если основная система откажет. В идеале ключевые узлы инфраструктуры должны работать по принципу георезервирования.
Disaster Recovery Plan не защитит серверное оборудование от потопа или пожара, но позволит спрогнозировать форс-мажор и быстро вернуться к работе бизнес-процессов.”
Чтобы построить отказоустойчивую архитектуру ВНС, нужен комплексный подход: репликация, кластеризация и продуманный план восстановления (DRP). Ключ к успеху — грамотное проектирование, регулярное тестирование и применение современных инструментов для автоматизации и мониторинга.
Чтобы минимизировать последствия сбоев, можно использовать следующие подходы:
-
Тестирование на устойчивость: например, инструменты типа Chaos Monkey вводят искусственные сбои для проверки готовности системы.
-
Снимки состояния (snapshots): регулярное сохранение состояния системы для ускоренного восстановления.
-
Геораспределение: дублирование данных в разных дата-центрах для защиты от потерь при региональных авариях.
Эти техники позволяют системам оставаться функциональными даже в условиях серьёзных отказов и катастроф.
Основные стратегии отказоустойчивости для ВНС

Резервирование (Redundancy):
Создание резервных копий компонентов системы. Например:
-
Аппаратное резервирование: использование нескольких серверов с автоматическим переключением в случае отказа одного из них.
-
Программное резервирование: запуск нескольких экземпляров приложения, работающих параллельно.
Инструменты: балансировщики нагрузки (например, NGINX или AWS ELB) часто используются для перенаправления трафика на доступные экземпляры.
Обнаружение и обработка ошибок (Failure Detection and Recovery):
-
Использование health-check'ов для мониторинга состояния сервисов.
-
Автоматическое перезапуск сервисов, которые перестали отвечать (например, через Kubernetes).
-
Реализация схемы "Circuit Breaker", которая блокирует отправку запросов на проблемный сервис, чтобы предотвратить лавинообразное увеличение нагрузки.
Ретрай (Retry):
Повторные попытки выполнения запросов при временных сбоях. Этот подход особенно полезен при взаимодействии с внешними API или при кратковременных отказах сетевых соединений.
Пример: библиотека Hystrix позволяет эффективно управлять ретраями и обработкой ошибок в микросервисной архитектуре.
Деградация системы (Graceful Degradation):
Когда некоторые функции временно отключаются для поддержания работоспособности основных. Например:
-
Отключение персонализированных рекомендаций при высокой нагрузке.
-
Ограничение функциональности мобильного приложения в моменты пиковых запросов.
Пример отказоустойчивой архитектуры ВНС
Представьте себе интернет-магазин, который обрабатывает тысячи заказов каждую минуту. Система этого магазина построена следующим образом:
|
Фронтенд |
Деплоится в несколько географически распределённых зон через CDN. Запросы распределяются балансировщиками нагрузки (например, Cloudflare или AWS ALB). |
|
Бэкенд |
Запущен в виде контейнеров в Kubernetes — и тоже в разных зонах доступности, как и базы данных. Поддерживается кластеризация и автоматический перезапуск контейнеров при сбое. |
|
Базы данных |
Используется кластер PostgreSQL с репликацией (основной узел и реплики). Для кэширования запросов — Redis с кластеризацией. |
|
Бэкапы |
Автоматическое резервное копирование данных каждый час с сохранением на отдельный облачный сервер. Или вариант с периодическим резервным копированием на ленточные хранилища с вывозом их физических копий в ядерный бункер (не шутка) на случай, например, успешной атаки хакеров. |
|
Мониторинг и алертинг |
Grafana визуализирует состояние системы, а Prometheus генерирует алерты при отклонении от нормы. |
Инструменты для отказоустойчивости в ВНС
|
Категория |
Инструмент / Технология |
Описание |
|
Репликация |
MongoDB, Cassandra |
Реализация репликации для обеспечения доступности данных. |
|
|
Amazon Aurora |
Управляемая реляционная база данных с репликацией. |
|
Кластеризация |
Kubernetes |
Автоматическое восстановление и перераспределение контейнеров. |
|
|
PostgreSQL с Patroni |
Управление кластеризацией реляционных баз данных. |
|
Балансировка нагрузки |
HAProxy, NGINX |
Распределение запросов между узлами. |
|
|
AWS Elastic Load Balancer |
Облачное решение для балансировки нагрузки. |
|
Резервное копирование |
Veeam, AWS Backup |
Регулярное создание резервных копий данных. |
Разделение ответственности и микросервисная архитектура: секрет успеха высоконагруженных систем

Микросервисы стали стандартом в проектировании высоконагруженных систем благодаря своей модульности и гибкости. Каждый микросервис работает как отдельный процесс и взаимодействует с другими через чётко определённые интерфейсы.
Представьте себе идеально отлаженный оркестр, где каждая группа музыкантов играет строго свою партию. Разработчики высоконагруженных систем стремятся к такому же порядку, применяя принцип разделения ответственности (Separation of Concerns). Этот подход позволяет каждому компоненту системы сосредоточиться на определённой задаче, а командам — не наступать друг другу на пятки.
Микросервисы в ВНС: маленькие, но полезные

Один из самых популярных способов разделить ответственность — микросервисная архитектура. Представьте, что вы разбили огромную монолитную систему на маленькие автономные кубики, которые общаются друг с другом через простые интерфейсы. Каждый такой кубик знает своё дело и не суёт нос в чужие процессы.
Преимущества микросервисного подхода:
-
Масштабируемость. Нагрузка растёт? Просто добавьте больше кубиков для самого востребованного сервиса.
-
Отладка без нервов. Ошибки локализуются внутри одного микросервиса — не нужно рыть весь проект в поисках причины.
-
Свобода для разработчиков. Разные команды могут разрабатывать свои микросервисы на любимых языках и технологиях.
Пример разделения ответственности в системе:
-
Авторизация и аутентификация: отдельный сервис, который пускает (или не пускает) пользователей в систему.
-
Обработка заказов: модуль, управляющий транзакциями и заказами.
-
Уведомления: самостоятельный сервис для отправки email или пушей.
Золотые правила разделения — чтобы ваши микросервисы не стали хаотичным набором модулей, придерживайтесь этих принципов:
-
Чёткие границы: каждый сервис должен иметь минимально необходимый интерфейс для взаимодействия с другими.
-
Минимизация связности: сервисы должны быть максимально изолированы друг от друга.
-
Логика внутри сервиса: бизнес-логика не должна расползаться по уровням интеграции — она должна быть сосредоточена в пределах сервиса.
В итоге получается гибкая, масштабируемая и легко поддерживаемая система, где каждый компонент знает своё место и задачу.
Взаимодействие между сервисами в ВНС

Микросервисы могут общаться друг с другом разными способами, и выбор метода зависит от задач:
-
REST API. Простой, надёжный и любимый многими разработчиками инструмент. Это своего рода общепринятый язык общения, который особенно хорош для взаимодействия с клиентами через HTTP.
-
gRPC. Для тех, кто любит производительность, особенно если нужно передавать двоичные данные. Быстрее и легче, чем REST.
-
Брокеры сообщений. Такие системы, как Kafka или RabbitMQ, позволяют передавать данные между сервисами асинхронно. Это идеальный выбор для задач, где важна надёжность обработки событий. Но сообщения идут в очередь и потихоньку (или нет) ползут от источника к приёмнику.
Пример: REST отлично подходит для получения данных о пользователях, а Kafka — для организации очереди событий, например, отправки уведомлений.
Очереди сообщений в ВНС

Очереди сообщений играют роль буфера, упрощая асинхронное взаимодействие и снижая нагрузку на сервисы. Если один сервис передаёт задание другому, а тот не успевает обработать его сразу, сообщение отправляется в очередь, чтобы дождаться своего часа/минуты/секунды/мгновения.
Примеры популярных инструментов для работы с очередями сообщений в ВНС
|
Категория |
ПО |
Описание |
|
Классические брокеры |
RabbitMQ |
Надёжный брокер сообщений с поддержкой протокола AMQP, часто используется для сложных систем. |
|
|
ActiveMQ |
Популярное open-source решение, совместимое с протоколами JMS, MQTT, STOMP и AMQP. |
|
|
Apache Kafka |
Распределённая платформа для обработки потоков событий, ориентированная на большие объёмы данных. |
|
Лёгкие брокеры |
ZeroMQ |
Очень быстрый и компактный брокер, который хорошо работает в сценариях peer-to-peer. |
|
|
NATS |
Высокопроизводительная система для обмена сообщениями с простой архитектурой. |
|
Облачные решения |
AWS SQS (Simple Queue Service) |
Надёжная облачная очередь сообщений от AWS с возможностью автоматического масштабирования. |
|
|
Azure Service Bus |
Облачная очередь от Microsoft с поддержкой сложной маршрутизации и FIFO-очередей. |
|
|
Google Pub/Sub |
Распределённая очередь для потоковых данных и событий. |
|
Распределённые брокеры |
Redpanda |
Kafka-совместимая альтернатива, ориентированная на высокую производительность. |
|
|
Pulsar |
Apache Pulsar предлагает распределённые очереди с поддержкой хранения больших объёмов данных. |
Очереди особенно полезны там, где поток событий высок: обработка заказов, оповещения или сбор данных от пользователей.
Кэширование в ВНС

Кэширование позволяет значительно снизить нагрузку на базу данных и ускорить отклик системы. Основные стратегии:
-
Кэш на стороне клиента. Данные сохраняются прямо на устройстве пользователя. Это как заготовки на зиму: быстро, удобно, но требует места.
-
Промежуточное кэширование. CDN или прокси-серверы берут на себя часть запросов, разгружая основную систему.
-
Серверное кэширование. Redis или Memcached — идеальные инструменты для хранения часто используемых данных.
Кэширование не только ускоряет отклик системы, но и снижает нагрузку на базу данных, превращая вашу инфраструктуру в хорошо отлаженную систему. В итоге, правильный выбор инструментов и подходов к взаимодействию помогает микросервисам работать слаженно, эффективно и без перегрузок.
Подборка популярных инструментов для кэширования
|
Категория |
ПО |
Описание |
|
Кэш на стороне клиента |
LocalStorage, IndexedDB |
Для веб-приложений: хранение данных прямо в браузере (например, для сохранения сессий). |
|
|
SQLite |
Локальная база данных для десктопных и мобильных приложений. |
|
Промежуточное кэширование |
Varnish Cache |
HTTP-акселератор для кэширования веб-страниц. |
|
|
NGINX (с модулями) |
Поддерживает встроенное кэширование и помогает ускорить доставку статических и динамических данных. |
|
|
Cloudflare, Akamai |
CDN-сервисы для кэширования контента ближе к пользователю. |
|
Серверное кэширование |
Redis |
Высокопроизводительная база данных in-memory для кэширования и управления сессиями. |
|
|
Memcached |
Лёгкий и быстрый инструмент для хранения ключ-значение в оперативной памяти. |
|
|
Hazelcast |
Распределённый кэш, подходящий для кластеров в больших системах. |
|
Комплексные решения |
Apache Ignite |
Кэш и вычислительная платформа для распределённых систем. |
|
|
Ehcache |
Популярный инструмент Java-приложений для кэширования данных. |
Структуры данных в ВНС

Структуры данных (Data structures) — это средства, с помощью которых программы хранят и извлекают данные, базовый инструмент для уменьшения времени обработки.
В высоконагруженных системах — это как правильно организованный склад: если товары разложены хаотично, поиск и обработка занимают больше времени, а значит, страдает производительность. Подходящая структура данных помогает оптимизировать доступ, хранение и манипуляцию данными, что критично для систем с миллионами запросов в секунду.
Что делает структуры данных важными в ВНС? Во-первых, скорость обработки — время, затраченное на поиск, вставку или удаление данных, прямо влияет на отклик системы. Оптимальные структуры позволяют минимизировать эти операции. Во-вторых, экономия ресурсов — компактное хранение данных снижает нагрузку на оперативную память и хранилище. И в-третьих, устойчивость к нагрузкам. Внедрение структур, адаптированных под конкретные типы запросов, позволяет избежать узких мест даже при пиковой активности.
Структура ключ-значение для высоконагруженных систем

Структура ключ-значение (Key-Value) — это один из самых популярных типов структур данных, особенно в высоконагруженных системах. По своей сути, это абстракция, которая реализуется через хэш-таблицы или другие механизмы хранения и поиска.
Как это работает: у каждой записи есть ключ (уникальный идентификатор) и значение (данные, связанные с этим ключом, сам контент).
Пример:
{
"userID:123": "Дмитрий Иванов",
"session:789": "активна",
"config:theme": "тёмная"
}
При добавлении данных ключ передаётся через хеш-функцию, которая вычисляет индекс для их хранения. Для извлечения значения достаточно знать ключ: система использует тот же алгоритм, чтобы мгновенно найти данные.
Если используется хэш-таблица, операция вставки и поиска может быть выполнена за О(1), то есть за фиксированное время.
Ремарка! Когда сложность алгоритма или операции равна О(1), это означает, что время выполнения не зависит от количества элементов в структуре данных. Операция выполняется за фиксированное время (константа), будь то 10 элементов или миллион. Но есть и нюансы: хеширование может иметь коллизии, что замедляет операции. Реализация имеет накладные расходы, которые влияют на реальное время выполнения.
Ключ-значение ≠ хэш-таблица

Хотя хэш-таблицы — это наиболее распространённая реализация структуры ключ-значение, на практике есть и другие. Та же файловая система, грубо говоря, тоже ключ-значение: имя файла — это ключ, его содержимое — значение. Бывают и другие реализации, вроде распределённых хранилищ (например, Consistent Hashing или Merkle Trees).
Примеры разных структур данных
Структура данных “Хеш-таблица”. Обеспечивают доступ к данным за константное время О(1), что идеально для задач поиска. Пример — кэширование запросов, где нужно быстро найти уже обработанные данные. Хэш-таблицы обычно требуют много памяти для минимизации коллизий, что не всегда подходит для некоторых приложений. А сложность в реальной жизни может бытьO(n) в худшем случае (при плохой хэш-функции или множестве коллизий) — это редкость, но важно учитывать.
Структура данных “Сбалансированное дерево поиска”. AVL-деревья или красно-чёрные деревья (Red Black Tree) поддерживают сбалансированность (это значит, что ни одна ветка не станет слишком длинной или короткой по сравнению с остальными), обеспечивая логарифмическую сложность O(log n) для поиска, вставки и удаления. Пример — индексация данных в файловых системах или СУБД. Они хорошо подходят для баз данных или индексации. К слову — деревья полезны не только для баз данных, но и для реализации множества и словаря (например, TreeSet и TreeMap в Java)
Структура данных “Куча” (англ. heap). Оптимальна для задач приоритетной обработки, например, в очередях задач, где нужно быстро извлекать элементы с максимальным или минимальным приоритетом. Часто используется в алгоритмах (например, алгоритм Дейкстры для поиска кратчайшего пути, сортировка кучей). Вставка и удаление минимального/максимального элемента в двоичной куче выполняются за O(log n). А ещё, как бы странно это не звучало, куча бывает разная: двоичная, белая, красная, биномиальная, Фибоначчиева.
Списки и массивы. Для последовательного хранения данных можно использовать связанные списки, где важна быстрая вставка, или массивы, где важен быстрый доступ по индексу. Односвязные списки имеют О(n) для доступа по индексу, тогда как массивы обеспечивают О(1), но требуют непрерывного блока памяти. Списки удобны для сценариев с частыми вставками/удалениями в середине, а массивы предпочтительны, если нужен быстрый доступ по индексу.
Важно! Выбор структуры данных должен соответствовать задачам, он зависит не только от скорости выполнения операций, но и от ограничений по памяти и сложности. Например, некоторые структуры данных могут требовать меньше памяти, чем другие, но при этом быть сложнее в реализации и поддержке. Важно тщательно проанализировать требования, задачи и выбрать ту структуру данных, которая подходит именно под ваш проект.
Промежуточный итог
Вот мы подобрались к концу второй статьи о высоконагруженных системах. В первой части мы разобрали аппаратные аспекты: что такое ВНС, из чего она состоит и как правильно подбирать оборудование под задачи и бюджет. Вторая часть сосредоточилась на программной составляющей: мониторинг, масштабирование, отказоустойчивость, микросервисная архитектура — всё, что делает систему не только производительной, но и гибкой, надёжной, устойчивой к нагрузкам.
Однако даже этих двух материалов (больших, надо сказать) недостаточно, чтобы охватить всю глубину темы. Архитектура ВНС — это не просто набор решений, это стратегия, требующая постоянной адаптации к новым вызовам и технологиям. Если у вас остались вопросы или вы хотите узнать больше о конкретных аспектах, смело переходите в комментарии ниже.
А если же нужна помощь с проектированием или подбором оборудования, обращайтесь к нашим менеджерам в Сервер Молл — они всегда готовы подсказать и помочь воплотить ваши идеи в жизнь.
Спасибо, что читаете и интересуетесь высоконагруженными системами. Если я что-то забыл, то дайте знать — про тот же кибербез в ВНС можно написать и третью статью :)







