

Привет, друзья!
NVIDIA — первая в истории компания, достигшая капитализации $4,725 трлн, что примерно на уровне номинального ВВП Германии. А всё почему? NVIDIA продаёт GPU компаниям, которые работают с ИИ (для сравнения: игровое направление приносит всего ~10% выручки, а ИИ-ускорители ~87%). Или возьмём AMD, котировки которой взлетели на 28%, когда они объявили о стратегическом партнёрстве с OpenAI по созданию инфраструктуры для следующего поколения ИИ-систем (поставки графических процессоров AMD Instinct для дата-центров OpenAI).
Цунами из больших языковых моделей (LLM, Large Language Model) и генеративного ИИ накрыло весь мир и всего за несколько лет изменило всю IT-индустрию. При этом облака не покрывают спрос крупных заказчиков, из-за чего цены на аренду растут. Многим приходится искать решения, которые можно развернуть в своей IT-инфраструктуре. И рынок серверов подстроился — все крупные игроки уже несколько поколений развивают свои решения с поддержкой профессиональных GPU.
А поскольку при выборе железа нужно учитывать бизнес-задачи, бюджет и даже политическую обстановку в мире, то самое время во всём этом разобраться.
Приступим!
CPU vs GPU: когда нужен графический ускоритель

Графические процессоры (GPU, Graphics Processing Unit) во многом похожи на классические центральные процессоры (CPU, Central Processing Unit), но они намного эффективнее работают с массовыми параллельными и специализированными вычислениями, так как содержат тысячи относительно простых вычислительных блоков. А CPU оптимизированы для быстрого выполнения отдельных последовательных задач (единицы, десятки или, редко, сотни сложных и универсальных ядер).
Со временем инженеры заметили, что архитектура GPU, которая подходит для рендеринга трёхмерной графики, отлично справляется и с другими задачами — от физического моделирования до обучения нейросетей. Так появилось направление GPGPU (General-Purpose computing on Graphics Processing Units) — использование графических процессоров для общих вычислений.

Топовые GPGPU кратно превосходят лучшие CPU по пиковой производительности (и в том числе на 1 Ватт затрачиваемой энергии) в оптимизированных задачах, и именно это позволило создать современные LLM и генеративный ИИ, вроде ChatGPT и Sora.
Но CPU универсальнее, и, как правило, в системе они работают с вычислениями вместе с GPU, забирая на себя часть задач: управление потоками данных, выполнение последовательной логики, подготовка и распределение задач между вычислительными ядрами, а также общение с операционной системой и внешними устройствами. Современные серверы комбинируют высокопроизводительные CPU (AMD EPYC или Intel Xeon последних поколений), сотни гигабайт памяти, быстрые NVMe SSD и GPU с HBM-памятью.
CPU может частично компенсировать неэффективный код за счёт сложных механизмов предсказания и кэширования, а GPU требует хорошей оптимизации исполняемого кода, потому что его производительность сильно зависит от эффективного распараллеливания нагрузки между тысячами ядер. Если код содержит слишком много ветвлений, обращения к памяти разбросаны или данные не выровнены по структурам, производительность резко упадёт.

Поэтому программы для GPU часто пишут с учётом архитектуры конкретного ускорителя — оптимизируют память, минимизируют ветвления и стараются загружать вычислительные блоки максимально равномерно.
Но не под все задачи нужны топовые ускорители NVIDIA Blackwell B200 по 3-4 млн рублей за штуку — это хайэнд сегмент для Enterprise-бизнеса, гиперскейлеров и других техногигантов. А серверы за 40-50 млн рублей с 8–16 ускорителями оправданы только при интенсивном обучении/инференсе масштабных моделей.
Выбор зависит от задач: глубокое обучение (deep learning) — явная зона профильных GPU, но для различных веб-сервисов, простых инференсов, обучения небольших моделей или обработки малых выборок часто достаточно обычного сервера на CPU и нескольких GPU среднего уровня.
GPU от NVIDIA: от Volta до Hopper и Blackwell

Сегодня NVIDIA доминирует на рынке ИИ-ускорителей — занимает около 90% рынка серверов с GPU. На серии Hopper (H100/H200) построено множество дата-центров, а новое поколение Blackwell (B200/GB200), которое пришло на смену, активно внедряется. Это уже не просто GPU, а полноценные вычислительные платформы с колоссальной пропускной способностью и энергоэффективностью (хоть и при очень высоком общем энергопотреблении).

Началось всё с NVIDIA TESLA V100 — это ускоритель на архитектуре Volta (2017 год) для задач машинного обучения и HPC. Там появились тензорные ядра 1-го поколения, которые ускорили обучение нейросетей, а также память HBM2 с пропускной способностью до 900 ГБ/с. Дальше шла архитектура Turing (модифицированная Volta), а потом архитектура Ampere (2020 год).

Ускоритель NVIDIA A100 получил тензорные ядра третьего поколения, память HBM2e (2 ТБ/с) и возможность разделения GPU на несколько независимых инстансов (Multi-Instance GPU, он же MIG) — то есть один ускоритель можно использовать параллельно для разных задач.

Ускоритель H100 построен по архитектуре Hopper (2022 год) с памятью HBM3 и пиковой производительностью для ИИ до 4 PFLOPS в формате FP8 и 2 PFLOPS в BF16/FP16 при энергопотреблении до 700 Вт.

Ускоритель NVIDIA H200 добавил к этому поддержку NVLink 4 (про это дальше) и сохранил тот же TDP, но получил более быструю память HBM3e (~4.8 ТБ/с), что повысило эффективность при работе с очень большими моделями.

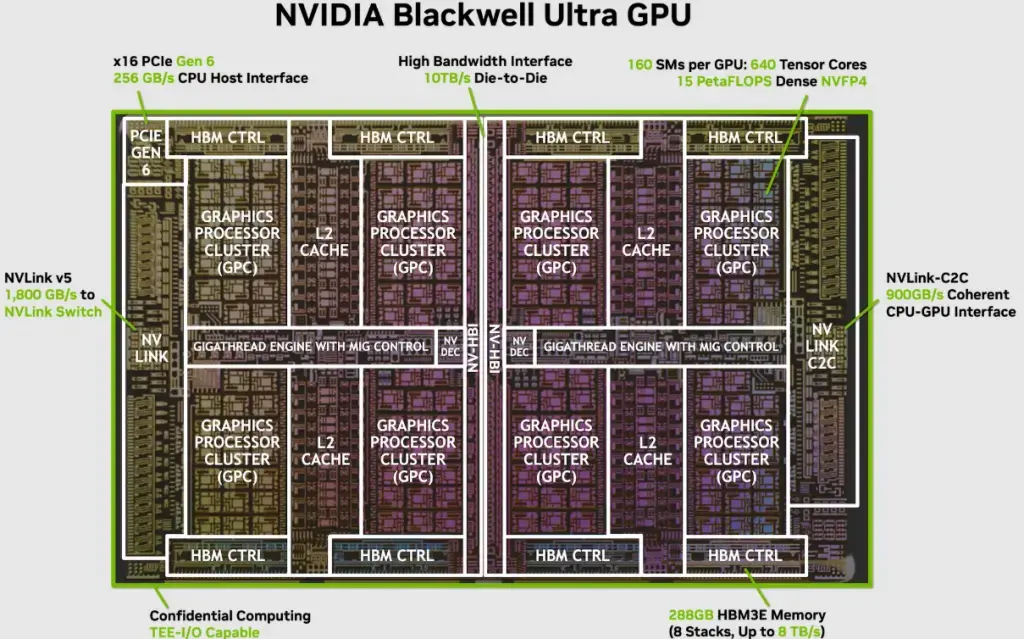
Архитектура Blackwell сделала качественный скачок. Ускоритель NVIDIA B100 анонсировали на GTC 2024 как референс, но первым в массовом внедрении стал GPU GB200. Он получил новое поколение тензорных ядер, появилась поддержка форматов FP6, FP4, пропускную способность памяти увеличили.

Ускоритель GB200 уже состоит из двух B200 GPU и Grace CPU, объединённых внутренним NV-HBI-интерфейсом с пропускной способностью 10 ТБ/с. Этот суперчип использует HBM3e-память и способен выдавать до 40 PFLOPS в ИИ нагрузках. Если рассматривать B200 как отдельный дискретный GPU-ускоритель (не в составе Superchip GB200 или rack-систем NVL72), то это микропроцессор, в котором все технологии размещены на одном кремниевом кристалле. Он нужен для гибких конфигураций (например, в HGX B200 системах с 8 GPU). У него 192 ГБ HBM3e памяти и пропускная способность до 8 ТБ/с, что даёт 10 PFLOPS в FP4 при энергопотреблении 1200 Вт на GPU.
В последней на 2025 год серии Blackwell каждый GPU Blackwell Ultra (B300) имеет 288 ГБ HBM3e памяти, GPU-кристаллы соединены через NV-HBI-интерфейс, а между GPU используется NVLink 5 с двунаправленной пропускной способностью 1,8 ТБ/с на один ускоритель в домене NVSwitch, что даёт 15 PFLOPS в FP4 при энергопотреблении 1400 Вт на GPU.
Межпроцессорное взаимодействие NVIDIA: NVLink, NVLink Switch и GB300 NVL72
Когда в сервере работают сразу несколько GPU, нужно, чтобы обмен данными между ними не стал бутылочным горлышком. Раньше это происходило через PCIe, но позже компании начали разрабатывать проприетарные решения.
NVLink — это проприетарная высокоскоростная шина, которая позволяет нескольким GPU (а также GPU и CPU в определенных системах) напрямую обмениваться данными с очень высокой пропускной способностью, минуя узкие места PCIe. Это не просто протокол, а физическая шина с выделенными линиями связи. Прямое соединение P2P (точка-точка) даёт минимальные задержки.
Но что ещё важно — NVLink позволяет нескольким GPU работать с памятью друг друга как со своей собственной, избавляя систему от проблем копирования данных через CPU. Это критически важно для сложных вычислений в ИИ и HPC. Получается нечто вроде CXL с когерентной памятью, но здесь проприетарное решение NVIDIA, а не общедоступный стандарт. Почитать про CXL можете в нашем материале на Хабре.
|
Поколение |
Пропускная способность на GPU |
Макс. линков на GPU |
Архитектуры |
|
3-е |
600 ГБ/с |
12 |
Ampere (A100) |
|
4-е |
900 ГБ/с |
18 |
Hopper (H100/H200) |
|
5-е |
1800 ГБ/с |
18 |
Blackwell (B200/GB200) |
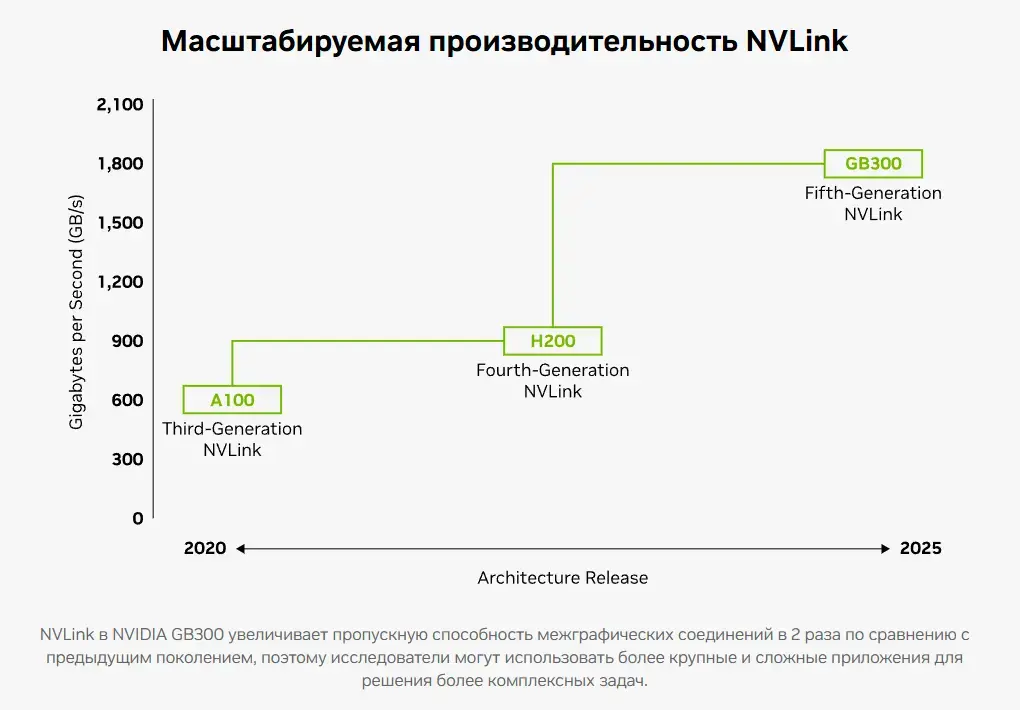
В пятом поколении архитектура NVLink поддерживает до 18 линков на ускоритель с пропускной способностью 100 ГБ/с каждое, что даёт суммарно до 1,8 ТБ/с двунаправленной передачи данных на GPU. Это вдвое больше, чем в предыдущем поколении, и в 7 раз выше, чем у PCIe 6.0 (256 ГБ/с через разъём x16).

У NVIDIA есть технология NVLink Switch, которая предлагает высокоскоростную связь между несколькими GPU и CPU внутри узла или стойки. Работает она на аппаратном (физическом) чипе-коммутаторе, который соединяет несколько графических процессоров с помощью высокоскоростных интерфейсов NVLink. Если сама шина предлагает соединение чипов по P2P (точка-точка), то NVLink Switch соединяется несколько GPU по топологии A2A (All-to-all — то есть все узлы напрямую общаются друг с другом).
Это не сетевая технология в привычном смысле — она не заменяет Ethernet или InfiniBand в ЦОДе, а дополняет их внутренней шиной с низкими задержками.
Например, 72 графических процессора NVIDIA Blackwell Ultra и 36 процессоров NVIDIA Grace на базе Arm в стойке NVIDIA GB300 NVL72 можно использовать как единый высокопроизводительный узел с вычислительной мощностью до 1,44 экзафлопс в FP4 для задач искусственного интеллекта. В сравнении с предыдущим поколением новая платформа GB300 предлагает в 1,5 большую производительность в сценариях инференса и reasoning.

Но современные GPU для ИИ — это не только решения от NVIDIA. AMD развивает платформу Instinct MI300 для гибридных CPU+GPU систем, а Intel продвигает свои AI-ускорители Gaudi 3 (лучше NVIDIA H100 по производительности и энергоэффективности).
GPU от AMD: линейка Instinct, Infinity Fabric и альтернатива NVIDIA

AMD вошла в гонку ИИ-ускорителей немного позже NVIDIA, но за последние поколения заметно сократила отставание — как по производительности, так и по зрелости экосистемы. Линейка Instinct — это профессиональные решения для ЦОДов, HPC (GPGPU) и ИИ вычислений: DL, ML, инференс больших моделей и т.д. Она стала для компании тем же, что и Ampere/Hopper/Blackwell — для NVIDIA: ядром всего серверного сегмента и символом технологического прорыва.

Первым серьёзным шагом стала серия AMD Instinct MI100, построенная на архитектуре CDNA. Она предлагала до 11,5 TFLOPS FP64 и 23.1 TFLOPS FP32, используя интерфейс PCIe 4.0 и память HBM2 с пропускной способностью около 1,2 ТБ/с. Уже тогда AMD сделала ставку на высокую плотность вычислений и энергоэффективность, ориентируясь на HPC-задачи и обучение моделей среднего масштаба.

Затем вышло поколение AMD Instinct MI200 — и вот здесь началась настоящая конкуренция с NVIDIA. Серия MI250/MI250X перешла на архитектуру CDNA 2 и получила двухчиповый дизайн (MCM), аналогичный тому, что NVIDIA реализовала позже в Blackwell. Каждый ускоритель содержал два кристалла, объединённых через Infinity Fabric, с совокупной пропускной способностью памяти HBM2e до 3,2 ТБ/с и производительностью до 95.7 TFLOPS в матричных операциях FP32. Эти GPU стали сердцем первого в мире экзафлопсного суперкомпьютера Frontier.

Следующим шагом стало семейство AMD Instinct MI300, где AMD объединила CPU и GPU в одном корпусе — APU для дата-центров. Вариант MI300A совмещает ядра Zen 4 и GPU CDNA 3, обеспечивая когерентность памяти и мгновенный обмен данными между CPU и GPU без внешних шин. Версия MI300X ориентирована исключительно на генеративные вычисления: 192 ГБ HBM3, пропускная способность свыше 5,3 ТБ/с с поддержкой FP8 и BF16 для ускорения ИИ-задач.

Наконец, новая серия MI350 — архитектура CDNA 4, память HBM3e (288 ГБ) c пропускной способностью 8 ТБ/с и новые форматы INT4/FP4/FP6 для матричных вычислений. В одной платформе можно использовать до 8 GPU (до 2.3 ТБ памяти). Ускорители MI350X рассчитаны на масштабные задачи генеративного ИИ и обучение LLM, обеспечивая линейное масштабирование и улучшенную энергоэффективность.
Всего за четыре поколения AMD прошла путь от классических ускорителей HPC до гибридных вычислительных систем с плотной интеграцией CPU и GPU. А благодаря открытой экосистеме ROCm, поддержке PyTorch и TensorFlow, и сотрудничеству с OpenAI и Microsoft, AMD Instinct уже превратился из догоняющего решения в реальную альтернативу на рынке дата-центров и ИИ-инфраструктур. Да, NVIDIA сохраняет доминирование с долей рынка около 90%, но конкуренция вендоров — всегда хорошо для заказчика.
Межпроцессорное взаимодействие AMD: Infinity Fabric

AMD использует проприетарный интерконнект — Infinity Fabric (IF), который связывает GPU, CPU, контроллеры памяти и другие компоненты системы с низкими задержками, высокой пропускной способностью и когерентностью. Это не просто шина (как часто пишут в определениях), а универсальный коммуникационный стек технологий, встроенный в архитектуру всех современных чипов компании — от консьюмерских Ryzen и видеокарт Radeon RX, до серверных процессоров EPYC и ускорителей Instinct.
В сериях MI200 и MI250X Infinity Fabric (через интерфейс XGMI) обеспечивала связь между двумя GPU-кристаллами в одном модуле с двунаправленной пропускной способностью около 400 ГБ/с. В MI300 эта технология перешла на версию Infinity Fabric 3.0, которая соединяет CPU, GPU и подсистему ввода-вывода (I/O) внутри одного модуля, предлагая когерентный доступ к общей памяти и совокупную внутреннюю пропускную способность до нескольких терабайт в секунду (в зависимости от конфигурации).
На уровне кластеров и ЦОДов Infinity Fabric не используется как сеть для межстоечных соединений. У AMD всё это реализуется стандартными средствами HPC-сети: InfiniBand (через адаптеры от Mellanox / NVIDIA), Ethernet (RoCE, RDMA) или через специализированные DPU/SmartNIC, такие как AMD Pensando.
Infinity Fabric в этом случае работает внутри каждого узла, а взаимодействие между узлами идёт поверх других протоколов, где когерентность обеспечивается уже на уровне ПО (MPI, RCCL, ROCm).
Серверные платформы с чипами NVIDIA
Решения на архитектурах Hopper и Blackwell развивают все ведущие OEM-игроки — Dell, HPE, Lenovo, Supermicro и другие. Например, Dell PowerEdge XE9680 поддерживает до 8 ускорителей NVIDIA HGX H100 или H200. HPE ProLiant DL380a Gen12 — до восьми NVIDIA H200 NVL ускорителей. Lenovo ThinkSystem SR680a V3 — до восьми NVIDIA H100 / H200.
 Модуль HGX
Модуль HGX
Платформы HGX и MGX позволяют масштабироваться от одиночных ускорителей (например, H100) до rack-решений уровня GB200 NVL72 с 72 GPU и 36 CPU Grace, объединённых через NVLink / NVLink Switch.
HGX — это проверенный стандарт для серверов с высокой плотностью GPU, часто в конфигурациях на 4, 8 или больше GPU, тогда как MGX предлагает модульный гибкий дизайн при построении систем с CPU, GPU, DPU и другими компонентами
В верхнем сегменте — серия DGX: готовые системы и кластеры, ориентированные на генеративный ИИ и LLM. DGX H100 и DGX GB200 NVL72 используют жидкостное охлаждение и оптимизированы под стек NVIDIA AI Enterprise, NGC, NeMo и прочие инструменты. Это очень дорогие решения.

В экосистеме NVIDIA есть практически полный стек: библиотеки (CUDA, cuDNN, NCCL, TensorRT), инструменты DevOps, мониторинг и т.д. Благодаря тесной интеграции ПО и железа, а также наличию масштабируемых сетей через NVLink / NVSwitch, NVIDIA сохраняет лидирующие позиции в области ускорителей ИИ.
Но важно, что NVLink / NVSwitch обеспечивают связь между GPU и в рамках стоек, а коммуникации между узлами дата-центра обычно строятся уже с использованием сетевых протоколов (InfiniBand, Ethernet, RDMA).
Серверные платформы с чипами AMD
Серверные платформы с Instinct тоже производят Dell, HPE, Lenovo, Supermicro и другие OEM-вендоры.
Например, Dell PowerEdge XE9680 поддерживает восемь ускорителей AMD Instinct MI300X. HPE ProLiant Compute XD685 — восемь ускорителей AMD Instinct MI300X или MI325X + два процессора AMD EPYC, с опциями воздушного и жидкостного охлаждения. Supermicro AS-2145GH-TNMR работает с четырьмя ускорителями MI300A и жидкостным охлаждением, а в Lenovo ThinkSystem SR685a V3 можно установить восемь MI300X.

Программная экосистема AMD тоже заметно выросла. ROCm, открытая альтернатива CUDA, поддерживает PyTorch (специальные версии или плагины, у NVIDIA тут получше), TensorFlow и другие популярные фреймворки, включая готовые оптимизации под Llama, Falcon, BLOOM и Mistral. Это позволяет использовать Instinct не только в исследовательских центрах, но и в корпоративных кластерах, где требуется гибкость и независимость от проприетарных решений NVIDIA. Но на практике степень оптимизации и стабильности может сильно варьироваться.
Сильные стороны решений AMD — архитектура APU (как в MI300A), объём HBM, пропускная способность, гибкость форматов данных, открытый стек и конкурентное соотношение цена/производительность, особенно в задачах инференса и обучения средних моделей, а также в гибридных архитектурах CPU+GPU.

Но есть ограничения. При масштабировании до сотен графических ускорителей системы на базе NVIDIA с NVLink / NVSwitch пока предлагают задержки ниже и лучшую согласованность памяти между GPU.
Подбор конфигураций серверов с GPU для компаний разных размеров
Ниже я приведу таблицу с серверами для разных сценариев GPGPU. Я ориентируюсь на известных производителей (Dell, HPE, Lenovo, Huawei и др.), но для импортозамещения также отмечу и отечественные серверы с поддержкой GPU.
ВАЖНО! Подборка ориентировочная — чтобы точно подобрать сервер с GPU под вашу задачу и бюджет, напишите нашим менеджерам в чат. Всегда согласовывайте спецификацию оборудования с бизнес-задачами. Платить за лишние GPU (или избыточные по производительности) — значит терять деньги.
И в таблице не будет цен, так как они сильно варьируются из-за рыночных условий (например, на момент публикации статьи будут одни цены, а под новый год — когда курс доллара вырастет — другие).
При подборе есть ещё один важный момент — форм‑фактор ускорителя.
-
PCIe — стандартное подключение через привычный слот на материнской плате. Основные плюсы: высокая совместимость с различными серверами и возможность строить связки NVLink (у NVIDIA) или ROCm‑PeerLink (у AMD) на несколько ускорителей.
-
SXM / OAM‑модули AMD — уровень выше. У NVIDIA такие GPU монтируются напрямую на специализированные платы HGX или DGX и соединяются через NVSwitch, создавая сеть GPU внутри сервера для максимально быстрой передачи данных. AMD использует аналогичный подход с GPU-модулями типа MI300A / MI300X, которые интегрируются на серверных платах и объединяются через внутреннюю шину Infinity Fabric для когерентного доступа к памяти. Результат: пропускная способность растёт, а узкие места PCIe нивелируются.
|
Категория |
Задачи и сценарии |
Примеры конфигураций |
|
Бюджетная (1 GPU) |
Инференс небольших моделей, лабораторные тесты, R&D, обучение средних моделей |
Серверы 1U/2U с одним GPU: Dell PowerEdge R750 8SFF (2x Intel Xeon Silver 4310, 64GB DDR4, до 8x 2.5" SFF, 1x NVIDIA A10); Dell PowerEdge R750 12LFF (2x Intel Xeon Gold 5315Y, 256GB DDR4, до 12x 3.5" LFF, 1x NVIDIA A30); HPE ProLiant DL385 Gen11 12LFF (1x AMD EPYC 9654, 64GB DDR5, до 12x 3.5" LFF, 1x NVIDIA A100 40GB); ASUS ESC N8-E11 10 SFF (2x Intel Xeon Gold 6442Y, 1TB DDR5, до 8x NVMe + 2x SATA, 1x NVIDIA HGX H100). Отечественные аналоги: OpenYard HN203I (до 4 GPU, но конфиг на 1; 2x Intel Xeon 6, до 8TB DDR5, до 320TB NVMe, поддержка NVIDIA H100 или специализированные L40/L40s/L4). |
|
Средняя (2–4 GPU) |
Fine-tuning LLM (дообучение больших языковых моделей с числом параметров примерно от 1 до 13 млрд под конкретные задачи или данные), разработка ИИ-приложений, комбинированные нагрузки, hybrid inference+training |
Серверы 2–4U с 2–4 GPU: Dell PowerEdge R760xa (конфигурируется до 4 GPU, например, с NVIDIA A100/H100); HPE ProLiant DL384 Gen12 (NVIDIA GH200 NVL); ASUS ESC N8-E11 (до 4 GPU с NVIDIA H100); HPE ProLiant DL380a Gen12 (2x Intel Xeon 6710E, 64GB DDR5, до 8x SFF/EDSFF, NVIDIA H200 NVL). Отечественные: Yadro G4208P G3 (конфигурируется до 4 GPU A100/H100/H200 NVL и другие, 2x Intel Xeon 4/5, до 8TB DDR5 ECC, PCIe 5.0). |
|
Топовая (8 GPU) |
Обучение крупных моделей (десятки – сотни млрд параметров), enterprise/HPC-центры, дата-сайенс кластеры |
Высокоплотные 4–6U-системы: Supermicro SYS-420GP-TNAR+ 6SFF (2x Intel Xeon Silver 4310, 256GB DDR4, до 6x NVMe/SAS, 8x NVIDIA A100 80GB); Dell EMC PowerEdge XE9680 8SFF (2x Intel Xeon Platinum 8468, 2TB DDR5, до 8x NVMe, 8x NVIDIA HGX H200 141G); NVIDIA DGX H800 640GB (2x Intel Xeon Platinum 8480C, 2TB DDR5, 8x 3.84TB NVMe, 8x NVIDIA H100 640G). |
В каждой категории возможны вариации: например, для бюджетного сервера можно взять более дешёвую GPU (RTX A5000/A6000 или аналоги от AMD), а для топового — другие версии.
Другие отечественные производители (Karma/Qtech, Гравитон, Trinity и др.) тоже выпускают решения с GPU.
Будущее ИИ-серверов
В целом будущее за комбинированными вычислительными платформами. Это позволит решать новые задачи ИИ быстрее и дешевле. Для закупщиков же важно наблюдать за этими трендами и вовремя адаптировать инфраструктуру под бизнес-задачи. В мире ИИ новые технологии и архитектуры выходят каждые 1–2 года.
Спасибо, что дочитали лонгрид до конца! В нашем каталоге вы найдёте серверы с поддержкой профессиональных GPU для любых задач — от лабораторных тестов и инференса небольших моделей до тренировки крупных LLM. Можно подобрать конфигурацию под один GPU или собрать высокоплотный узел с ускорителями NVIDIA или AMD.
Подберём решение под ваши задачи. Выездная гарантия до 5 лет, бесплатная доставка по всей России и коммерческое предложение за час (или быстрее).




Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение