

Привет!
Статей про выбор систем хранения данных (далее — СХД) много, но толковых днём с факелом не сыщешь.
Часть материалов морально устарела, часть — поверхностная, а где-то информация vSAN обрывки информации. В итоге, чтобы действительно разобраться в теме, приходится перелопатить с десяток источников (часто на английском, а то и вовсе на китайском),а потом на практике пройти все круги ада и стадии принятия неизбежного:
Отрицание: «Да ладно, не может быть всё настолько сложно. Это же просто коробки с дисками!»
Гнев: «Почему всё так запутано? Почему нельзя сделать нормальные, понятные решения, как у Apple?!»
Торг: «Может, если взять самое дорогое хранилище, оно просто будет работать и не создавать проблем?»
Депрессия: «Я в этом никогда не разберусь…»
Принятие: «Окей. СХД — это сложная тема. Придётся вникать. Так… что тут у нас, статья в блоге Сервер Молл? Отлично, начнём отсюда.»

Когда ищешь годную статью в интернете.
Да, хорошее оборудование подобрать сложно. Причём дело не только в выборе железа: СХД нужно правильно встроить в инфраструктуру, настроить, учесть нагрузки, сценарии отказа и будущий рост. Ошибка на любом этапе — это не просто неудобство, а вполне реальные финансовые и репутационные потери.
Поэтому давай разберёмся системно. В этом материале я собрал актуальную на 2026 год информацию по СХД и дополнил её практическим опытом инженеров, которые каждый день работают с серверным оборудованием, виртуализацией и хранением данных в реальных проектах.
СХД для бизнеса: что это и какая связь с потребностями организации

СХД (системы хранения данных) — это специализированный комплекс аппаратно‑программных решений для размещения, управления и защиты информационных ресурсов. В отличие от серверов (которые ориентированы на обработку данных), СХД оптимизирована для операций ввода‑вывода, максимальной ёмкости и надёжности хранения. Если жёсткий диск в ПК — это книжный шкаф, то СХД — это уже полноценная библиотека с каталогами, системой доступа, резервными копиями и контролем целостности.
В английском чаще используют термины data storage systems или просто storage. В русском иногда возникает путаница: аббревиатуру СХД могут расшифровывать как «сеть хранения данных», хотя речь идёт именно о системах хранения данных. В рамках статьи будем придерживаться этого значения.
Идём дальше. СХД — это либо аппаратные системы (специализированные серверы), либо программно-определяемые решения (SDS/HCI), которые работают поверх обычных серверов и объединяют ресурсы в единое хранилище. Причём в современных инфраструктурах второй подход встречается всё чаще.
Такие системы решают сразу несколько задач: хранят данные, управляют ими, обеспечивают резервное копирование и восстановление, распределяют нагрузку и дают доступ приложениям и пользователям.
Если сравнивать с обычными компьютерами, СХД обеспечивают гораздо более высокую производительность, отказоустойчивость и контроль над данными. Но здесь есть важный нюанс: итог зависит не столько от самого оборудования, сколько от архитектуры — как настроены репликация, снапшоты, аварийное восстановление и политика хранения.
СХД используют в корпоративных сетях, дата-центрах и облачных инфраструктурах — везде, где с данными одновременно работают десятки, сотни или тысячи пользователей и сервисов.
ВАЖНО! выбор СХД напрямую влияет на всю IT-инфраструктуру. От него зависит скорость приложений, доступность сервисов, устойчивость к сбоям и, в конечном счёте, деньги бизнеса. |
Пара слов об архитектуре СХД.
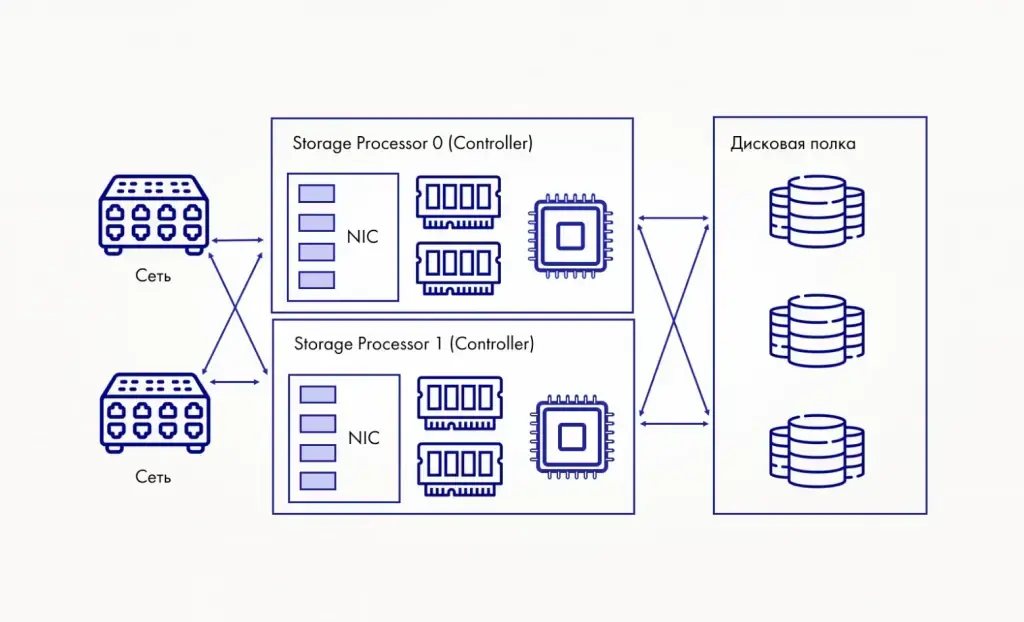
В основе большинства современных аппаратных систем лежит принцип избыточности: критически важные компоненты дублируются и работают либо в режиме active-standby (резерв включается при отказе), либо в active-active (нагрузка распределяется, износ меньше, доступность больше).
Если сравнить — это как несколько колёс на одной оси у грузовика — пробил шину на ходу, но едешь дальше.

Разберём ключевые элементы архитектуры.
Дисковые контроллеры и кэширование.
В большинстве СХД используется несколько контроллеров, каждый из которых работает с собственной кэш-памятью. Кэш — это быстрая, но энергозависимая память, где временно держатся часто используемые данные. За счёт этого ускоряется доступ к информации и снижается нагрузка на дисковую подсистему. Как понимаете, если контроллеров несколько, система продолжит работать даже при отказе одного из них.Диски и логика хранения.
Накопители объединяются в RAID-массивы, чтобы защитить данные от отказа отдельных дисков. Однако в современных системах этим всё не ограничивается: в распределённых СХД RAID дополняется репликацией и erasure coding на уровне кластера. Это даёт более гибкую и масштабируемую защиту, особенно в больших инфраструктурах.Горячая замена компонентов.
Большинство элементов СХД можно менять без остановки системы: диски, блоки питания, контроллеры. Это критично для бизнеса, где простой даже на несколько минут может стоить дорого.
В результате вся эта избыточная и многослойная архитектура позволяет СХД обеспечивать высокую производительность, устойчивость к отказам и предсказуемую работу под нагрузкой. Именно поэтому такие системы используют для хранения действительно важных данных, где ошибка или простой обходятся слишком дорого.
Какая связь у СХД с потребностями бизнеса

Выбор СХД напрямую влияет на то, как работает бизнес: насколько быстро открываются сервисы, падают ли они под нагрузкой, теряются ли данные и сколько денег всё это стоит в перспективе нескольких лет.
Разберём ключевые моменты.
Производительность СХД.
Для онлайн-магазинов, сервисов, SaaS-продуктов и любых систем с высокой нагрузкой критичны скорость обработки запросов и транзакций, задержки (latency), стабильность под нагрузкой и способность системы обрабатывать тысячи параллельных операций.
По статистике человек ждёт несколько секунд загрузку сайта или приложения, если не дожидается — уходит к конкурентам.х
Надёжность и доступность СХД.
Банки, интернет-магазины, маркетплейсы, соцсети — для них доступность данных 24/7 не опция, а базовое требование. Любой простой — это не просто техническая проблема, а прямые убытки и репутационные потери.
Поэтому СХД проектируют с учётом отказов, дублирования и сценариев аварийного восстановления. Никто не хочет лишиться доступа к банковскому приложению или своим фоточкам в запрещённограмме.
Масштабируемость СХД.
Сегодня у вас команда из 10 человек, через год — 50, через два — сотни клиентов и кратный рост данных. С ростом бизнеса растёт и ответственность объём данных.
Современные СХД позволяют масштабироваться двумя способами: вертикально (добавлять диски, расширять полки) и горизонтально (добавлять новые узлы в кластер). Второй вариант особенно важен в 2026 году, потому что даёт почти линейный рост производительности и объёма без полной замены системы.
Безопасность СХД и соответствие требованиям.
Конфиденциальность, целостность и доступность данных — основа любой инфраструктуры. Но в 2026 году к этому добавляется ещё один фактор: киберугрозы, особенно программы-вымогатели.
Бизнесу важно не только хранить данные, но и защищать их: шифрование, контроль доступа, неизменяемые (immutable) бэкапы, защита от удаления и шифрования. Плюс требования регуляторов (GDPR, отраслевые стандарты и т.д.) никто не отменял.
Безопасность всё чаще реализуется не столько на уровне железа, сколько на уровне программной логики и политики хранения.
Стоимость владения СХД.
СХД — это не разовая покупка. Важно учитывать полную стоимость владения: обслуживание, лицензии, энергопотребление, охлаждение, обновления и поддержку.
Иногда более дорогая система на старте оказывается выгоднее в долгую за счёт меньших затрат на эксплуатацию и лучшей эффективности. Поэтому смотреть только на цену здесь и сейчас — частая ошибка. Про экономическую эффективность и окупаемость инвестиций будет дальше — подробно и с примерами.
Интеграция СХД.
Современная IT-среда — это не один сервер, а набор сервисов: виртуализация, контейнеры, облака, базы данных, аналитика.
СХД должны без проблем встраиваться в эту экосистему: поддерживать нужные протоколы (NFS, SMB, iSCSI, S3 и др.), работать с гипервизорами и контейнерными платформами, не ломать текущие процессы.
Управление данными СХД.
Хранить данные — это только половина задачи. Не менее важно уметь ими управлять.
Бизнесу нужны инструменты для резервного копирования, восстановления, дедупликации, архивирования, репликации между площадками и автоматического распределения данных по уровням хранения.
И чем больше данных и сложнее инфраструктура, тем сильнее растёт роль этих механизмов. Без них СХД превращается просто в дорогой набор дисков — а это совсем не то, что нужно бизнесу.
Типы систем хранения данных
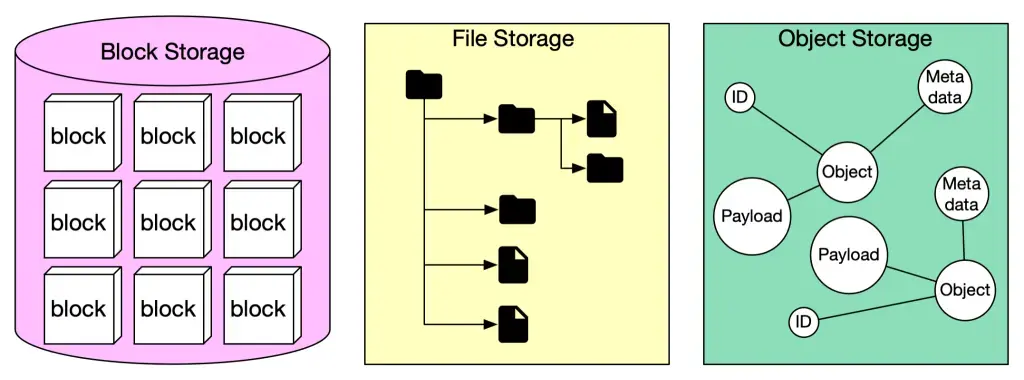
В IT-инфраструктурах в основном используют 3 типа хранилищ, но на деле их больше. Выбор, как и полагается, зависит от потребностей бизнеса и бюджета. Для наглядности сравню всё это дело в таблице.
Сравнение типов хранилищ: когда выбирать и другие параметры
Файловые хранилища (File Storage / NAS) | Блочные хранилища (Block Storage / SAN) | Объектные хранилища (Object Storage) | |
Когда выбирать | Когда нужен общий доступ к файлам: документы, медиаконтент, совместная работа, файловые сервисы. Например, для общих сетевых папок, документооборота или совместной работы над файлами. | Когда важна высокая производительность и низкая задержка: базы данных, транзакционные системы. Также подходит для виртуализации серверов, где несколько виртуальных машин может обращаться к одному и тому же блочному хранилищу. | Когда работаете с большими объёмами неструктурированных данных: бэкапы, архивы, Big Data, основа облаков, data lake и ИИ нагрузок (S3-совместимые решения стали стандартом де-факто), а также хорошо подходят для геораспределенных систем. |
Примеры | NAS (Network-Attached Storage): Synology DiskStation, NetApp FAS, Western Digital My Cloud. Серверы документов, медиасерверы, шаринг файлов. | SAN (Storage Area Network), дисковые массивы: HPE 3PAR StoreServ, Dell EMC VMAX (или PowerMax). Виртуализация, кластеризация, резервирование и восстановление данных, размещение баз данных. | Amazon S3, Google Cloud Storage, OpenStack Swift, а также S3-совместимые решения (MinIO, Ceph, Wasabi и др.). Хранение Big Data и аналитика, архивация, облачное хранение (соцсети), геораспределённое хранение. |
Описание | Данные организуются в файлы и каталоги. Предоставляют доступ к данным на уровне файловой системы. | Данные разбиваются на блоки и адресуются по их номеру. Предоставляют доступ на уровне блоков, что делает их идеальными для баз данных и дисковых систем. | Данные хранятся в виде объектов, каждый из которых имеет уникальный идентификатор, а также метаданные. Масштабируемость и управление данными на уровне объекта. |
Применение | Файловые шары, документооборот, медиа, пользовательские данные. | Базы данных, которым требуется высокая производительность и низкая задержка, виртуальные машины, ERP/CRM-системы. | Хранение огромных объемов неструктурированных данных: Data lake, бэкапы, архивы, облачные сервисы, ИИ/аналитика. |
Протоколы | NFS (Linux), SMB/CIFS, NFS, FTP, SFTP, HTTP, WebDAV, DC, BitTorrent и др. | iSCSI, Fibre Channel (FC), Fibre Channel over Ethernet (FCoE), ATA over Ethernet (AoE) и др. | S3 (от Amazon), Swift (от OpenStack) и др. |
Преимущества | Простота использования и управления, интуитивно понятный интерфейс, возможность совместного использования данных между множеством пользователей. | Высокая производительность и низкая задержка, идеально подходит для приложений, требующих быстрого доступа к данным, например, базы данных. | Почти неограниченная масштабируемость, поддержка географически распределенных данных, устойчивость к ошибкам (репликация и устойчивая к сбоям архитектура). |
Недостатки | Ограниченная масштабируемость в классических NAS, узкие места по производительности, особенно при большом объеме и разнообразии данных. | Сложность настройки, стоимость, требования к инфраструктуре. Обычно дороже и сложнее в управлении, требует специализированного оборудования. | Относительно высокие задержки, не подходит для классических БД и транзакционных систем (без адаптации), невозможность редактировать данные (только перезапись), слабая работа с большим количеством мелких объектов. Неидеально для приложений, требующих высокой производительности на блочном уровне. |
Другие типы хранилищ (помимо СХД)
Также есть и другие типы хранилищ, которые встречаются в современных инфраструктурах и часто дополняют классические модели.
Гибридные системы хранения.
Комбинируют характеристики разных типов хранилищ: блочных и файловых или блочных и объектных. Это позволяет одной системе закрывать сразу несколько сценариев — например, обслуживать базы данных и одновременно хранить файловые данные или бэкапы. В 2026 году такие решения всё чаще встречаются в виде унифицированных платформ с поддержкой нескольких протоколов (SAN + NAS + S3 в одной системе).
In-memory хранилища.

Например, RAM-диск или распределённые системы вроде Redis (Remote Dictionary Service). Данные в них хранятся в оперативной памяти, что даёт минимальные задержки и максимально возможную скорость доступа.
Такие решения активно используют как слой ускорения: кэш для баз данных, промежуточное хранение сессий, ускорение веб-приложений и аналитики. Но важно понимать, что это не замена СХД, а дополнение к ним — долговременное хранение они не обеспечивают (да и цели такой нет).
Многоуровневые системы хранения (Tiered Storage).
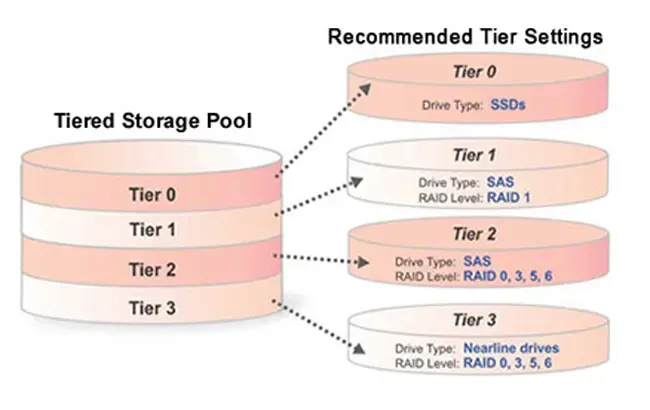
Здесь данные автоматически распределяются между разными типами накопителей — NVMe, SSD, HDD и даже ленточными библиотеками — в зависимости от частоты доступа и критичности.
Горячие данные (hot data), к которым часто обращаются, остаются на быстрых NVMe или SSD. Холодные (cold data) постепенно перемещаются на более дешёвые носители — HDD или ленты.
В современных системах этот процесс автоматизирован: используются алгоритмы и политики, которые анализируют поведение данных и сами принимают решение, где их хранить. В отдельных решениях подключаются элементы машинного обучения для более точного распределения нагрузки.
Чтобы не хранить все данные на дорогом высокопроизводительном уровне, компании распределяют их по уровням хранения, учитывая важность и частоту доступа. NVMe и SSD (условный Tier 0 / Tier 1) дают максимальную скорость, но стоят дороже. HDD (Tier 2) дешевле и подходят для менее критичных данных. Магнитные ленты (Tier 3) — самый экономичный вариант для архивов в пересчёте на гигабайт полезного хранилища.
Так и экономят, и оптимизируют производительность, разделяя данные между разными уровнями Tier, сохраняя высокую скорость для критичных нагрузок.
Программно-определяемые хранилища (Software-Defined Storage, SDS).
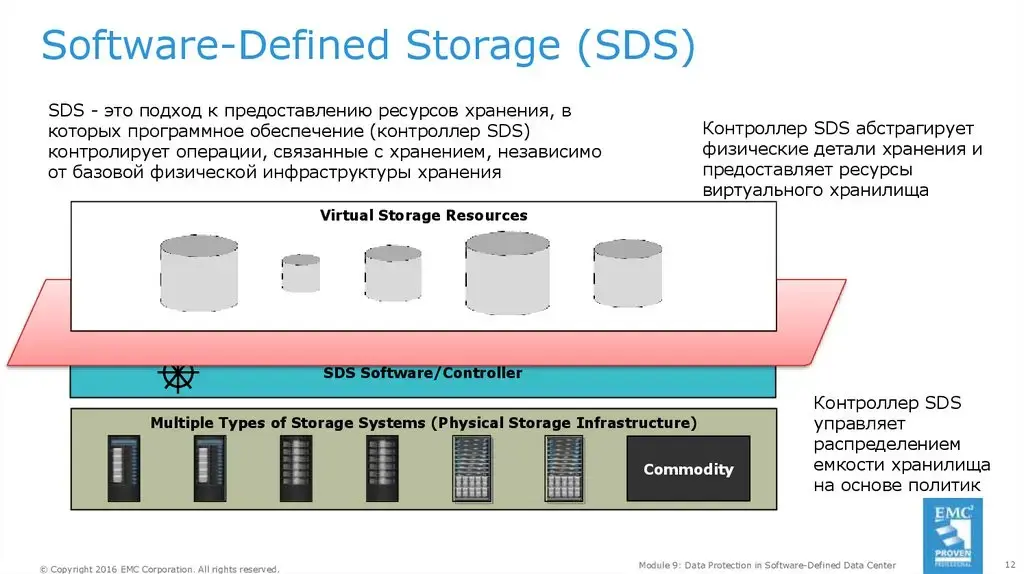
Это скорее подход к хранению данных, когда создание, управление и организация хранилища (абстракция) основаны на софте, а не на железе. SDS позволяет объединять разные ресурсы — диски, SSD, NVMe и даже облачные хранилища — в единое централизованное пространство. По сути, это абстракция над железом, которая даёт гибкость и масштабируемость.
В 2026 году SDS — это основа гиперконвергентной инфраструктуры (HCI) и облаков. Его используют в Kubernetes-средах, в VMware vSAN, Ceph, MinIO и других платформах.
Современные реализации хорошо оптимизированы, но производительность сильно зависит от сети и конфигурации. Особенно это заметно при использовании NVMe over Fabrics и RDMA (например, RoCEv2), где можно добиться очень низких задержек, но требования к инфраструктуре возрастают.
Небольшая аналогия. Традиционные системы хранения данных — вы заказали блюдо, а повар готовит его исключительно на одной конкретной сковороде с определёнными ингредиентами, которые именно для этого блюда хранятся в отдельном холодильнике. То есть всё очень негибко, ведь традиционные хранилища часто связаны с конкретным оборудованием. SDS — повар может взять любую сковороду и ингредиенты из любого холодильника, чтобы приготовить ваше блюдо. Повар решает на основе текущих потребностей и доступности, какие ингредиенты и какая сковорода ему подходят. SDS даёт решение без привязки к конкретному оборудованию, что делает его идеальным для гетерогенных и облачных сред. |
Преимущества SDS: гибкость, масштабируемость, автоматизация управления и возможность снизить затраты за счёт использования commodity hardware — массового, доступного и взаимозаменяемого оборудования вместо дорогих проприетарных решений.
Недостатки: сложнее эксплуатация, выше требования к квалификации специалистов. Кроме того, из-за дополнительных уровней абстракции могут расти задержки доступа к данным — особенно при неправильной настройке. Поэтому в high-load сценариях важно внимательно подходить к архитектуре и сетевой части.
Советы по выбору подходящей системы хранения данных
Масштабируемость и потенциал будущего роста СХД

Каждый отсек — это накопитель в СХД.
Задача сисадмина сделать так, чтобы корпоративные данные были всегда доступны, надёжно хранились, а объём хранилища мог расширяться вместе с ростом компании.
Поиграем немного в Sim City. Представьте, что ваша компания — это растущий город. Сначала это маленькая деревня с несколькими домами и центральным водоснабжением (данными). Но со временем деревня растёт, появляются новые улицы, высотки, инфраструктура. Ваша задача — предусмотреть, чтобы этот город мог расти и развиваться. Если у вас изначально маленький резервуар с водой, то когда город превратится в мегаполис, у вас будут проблемы с водоснабжением.
Так же и с СХД. Если вы изначально выберете систему, которая не может масштабироваться, то рано или поздно вы столкнётесь с проблемами.
Масштабируемость СХД, если очень кратко, это способность системы расти и адаптироваться к увеличивающемуся объёму данных. Это не просто добавление дополнительных дисков или хранилищ — система должна обрабатывать большие объёмы данных так же эффективно, как и при малой нагрузке.
Чтобы масштабируемость была не в теории, а на деле, нужно учитывать потенциал будущего роста ещё на этапе закупки оборудования. Подумайте не только о текущих потребностях, но и о том, что будет через 5 или 10 лет. Не экономьте на возможностях системы в ущерб будущему росту. Помните, что закупка масштабируемых СХД — это инвестиция, а не просто расход. То есть оборудование окупится и сэкономит деньги в будущем, если вы всё правильно рассчитаете.
Побудьте архитектором, который планирует развитие города на десятилетия вперед, учитывая потребности жителей, инфраструктуры, транспорта и т.д. А пример того, как это сделать и как рассчитать экономическую эффективность и окупаемость (ROI) для СХД, будет в конце статьи.
Требования к производительности и пропускной способности СХД
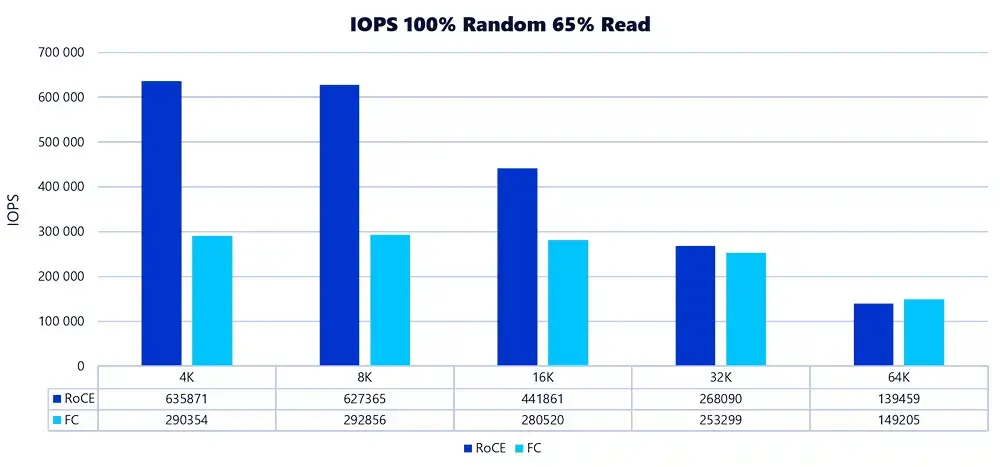
При выборе СХД важен не только объём данных, который она может хранить, но и то, как организован доступ к этим данным. В современных инфраструктурах это часто даже важнее объёма — особенно для компаний с высоким трафиком, распределёнными сервисами и приложениями реального времени.
Давайте представим, что система хранения данных — это большой водоём, а вода — это данные, которые постоянно двигаются по трубе. Если в город ведёт одна узкая труба, рано или поздно начнутся перебои с водоснабжением. И неважно, сколько воды в резервуаре — если её нельзя быстро доставить, система не справляется.
Максимальный объём воды, который наша труба может пропускать — это и есть аналог нашей пропускной способности (МБ/с, ГБ/c) в СХД: количество данных, которое можно передать за определённое время.
Теперь второй параметр. Количество воды, которое водозабор может отдать трубе в секунду — это производительность СХД, измеряемая в IOPS (Input/Output Operations Per Second, количество операций ввода-вывода в секунду) — этот показатель отражает, насколько хорошо система справляется с большим количеством мелких запросов.
ВАЖНО! Если у СХД плохая производительность, то даже при отличной пропускной способности будут проблемы с доступом к данным. Например, если у вас старый или маленький водозабор (низкая производительность), то даже при широкой трубе горожанам не будет хватать воды.
Если бизнес растёт, увеличивается количество пользователей и сервисов, то СХД должна быть готова обрабатывать растущий поток запросов без деградации.
Считаем IOPS для СХД
Первое, с чего стоит начать — оценка требований к IOPS.
Если у вас уже есть инфраструктура, проще всего оттолкнуться от текущих метрик: собрать статистику, посмотреть пики нагрузки, характер операций. Но важно не зацикливаться на текущем состоянии. В 2026 году системы проектируют с горизонтом минимум 3–5 лет, а нагрузка за это время может вырасти кратно — за счёт аналитики, контейнеров, ИИ и роста пользовательской базы.
Для базовой оценки иногда используют упрощённую формулу для расчета IOPS для конкретного диска (а не всей системы): IOPS = 1000 / (Seek Latency + Rotational Latency).
Но, конечно, никто каждый раз не считает, все опираются на типовые значения:
Тип накопителя | Скорость вращения (RPM) | Типовой IOPS (чтение) | Типовой IOPS (запись) |
HDD | 7,200 | ~75–100 | Немного ниже, чем у чтения (примерно на 5–10%) |
HDD | 10,000 | ~125–150 | Немного ниже, чем у чтения |
HDD | 15,000 | ~180–250 | Немного ниже, чем у чтения |
SSD (SATA) | — | ~50,000–100,000 | ~30,000–80,000 |
SSD (NVMe 3 поколения) | — | ~200,000–500,000 | ~200,000–400,000 |
SSD (NVMe 4/5 поколения) | — | до 1,500,000 | до 1,000,000 |
В реальных же системах (особенно с SSD и NVMe) поведение намного сложнее и зависит от контроллеров, очередей, кэширования и сетевой части. Поэтому в 2026 году ориентируются не только на IOPS, но и на задержки (в миллисекундах или даже микросекундах), пропускную способность, стабильность под нагрузкой и в пики.
Если смотреть на систему в целом, производительность масштабируется за счёт количества накопителей и архитектуры. Например, два диска со скоростью вращения 15 тыс. об/мин, работающие вместе, могут выдать теоретические 360 IOPS (180 + 180). Десять дисков могут выдать 1800 IOPS, а 100 дисков теоретические 18 000 IOPS. Но на практике итог ограничивается контроллерами, сетью и выбранным уровнем RAID или распределения данных.
Примеры рабочих нагрузок СХД
Базы данных.
Требуют высокий IOPS и низкую задержку из-за большого количества случайных операций чтения и записи. Пропускная способность тоже важна, но вторична.
Файловые серверы.
Если работа идёт с крупными файлами (видео, бэкапы, образы), важнее пропускная способность. IOPS при этом играет меньшую роль. В современных архитектурах такие нагрузки всё чаще уходят в объектные хранилища или распределённые файловые системы (например, CephFS).
Виртуализация.
Комбинированная нагрузка: требуется и высокий IOPS, и хорошая пропускная способность. Всё зависит от количества ВМ и их профиля.
Какие требования к пропускной способности СХД
Тип рабочей нагрузки.
Последовательное чтение/запись: некоторые рабочие нагрузки, например, потоковое видео или резервное копирование, требуют высокой пропускной способности для последовательного чтения или записи. Случайное чтение/запись: базы данных и веб-серверы могут работать с большим количеством операций случайного чтения или записи.
Объём данных и количество пользователей. Системы с большим объёмом данных и/или пользователей могут требовать большой пропускной способности для нормальной работы.
Распределённые системы. Распредёленные системы (Ceph, MinIO, vSAN) предлагают большую пропускную способность по сравнению с одноплатформенными решениями. Это стандарт для масштабируемых хранилищ и облачных архитектур.
И ещё несколько важных моментов, которые влияют на производительность и пропускную способность.
Какие есть сетевые соединения для СХД
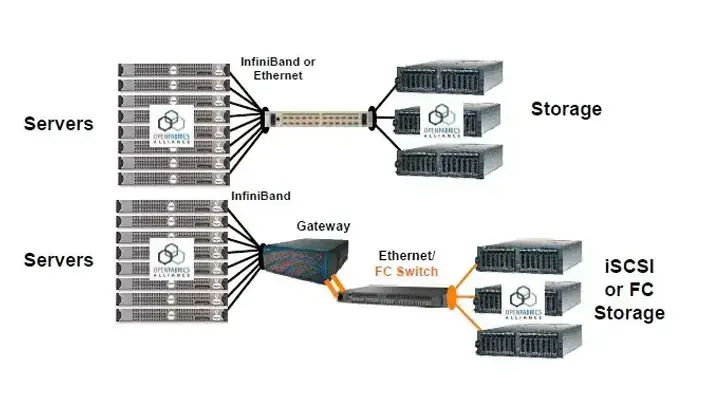
Сеть сегодня — один из ключевых факторов производительности.
Ethernet. 25/50/100/200/400 Гбит/с — стандарт для современных дата-центров. 100 Гбит/с уже массовый уровень, 200–400 Гбит/с используются в высоконагруженных ИИ-кластерах.
Fibre Channel (FC). Классический вариант для SAN: низкая задержка, высокая стабильность. Используется в enterprise-средах (16/32/64G FC), но конкуренция со стороны Ethernet-решений всё больше.
InfiniBand. Ключевая технология для HPC, ИИ-кластеров и GPU-инфраструктуры, даёт минимальные задержки и высокую пропускную способность, особенно в связке с RDMA и RoCEv2, активно используется в современных дата-центрах.
SAS SAN. Фантастическая тварь, но в корпоративных и legacy-инфраструктурах она обитает, а потому тоже упомяну. SAS SAN — это сети на базе дискового интерфейса SAS, со специальными SAS-коммутаторами для соединения СХД и серверов. Получаем высокую пропускную способность и низкую задержку. Это нечто среднее между DAS (прямое подключенное хранилище) и сетью хранения — расширяемой и гибкой. SAN на SAS используют всё реже, так как они уступают Ethernet/NVMe-oF решениям.
Другие технологии. NVMe over Fabrics (NVMe-oF), RoCEv2, FCoE — современные подходы для построения высокопроизводительных СХД. NVMe-oF и RDMA-сети сегодня — основа для систем с минимальными задержками.
Какой тип подключения выбрать для СХД (подробнее здесь)
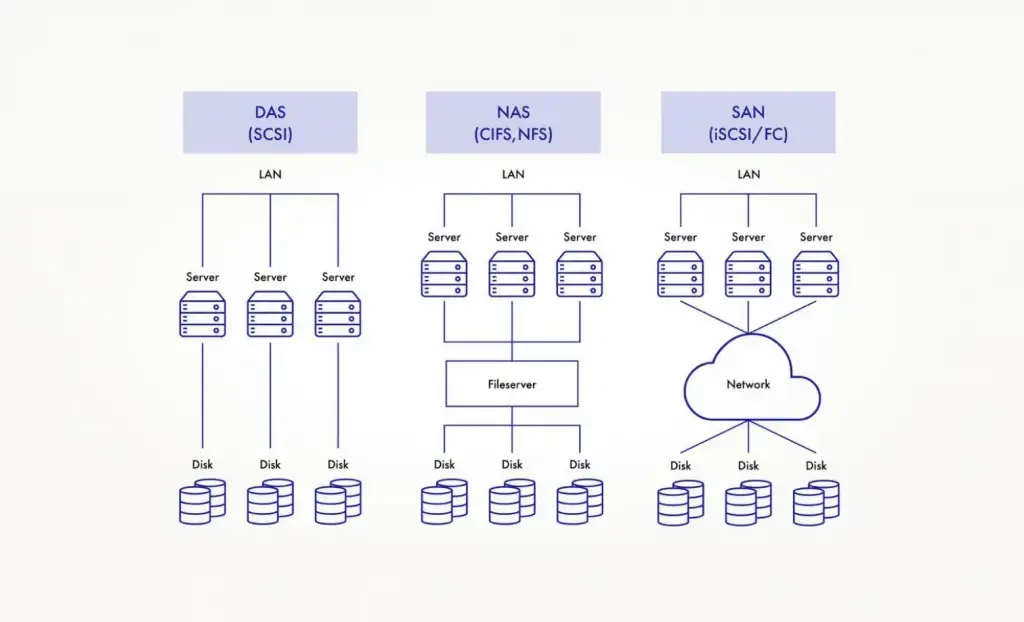
SAN (Storage Area Network).
Выделенная сеть хранения, где серверы получают доступ к блочным устройствам. Классика — Fibre Channel и iSCSI, но сейчас всё чаще встречается NVMe-oF (NVMe over Fabrics) — это NVMe поверх сети (RoCE, TCP), дающий меньшие задержки и лучшую масштабируемость. SAN по-прежнему остаётся стандартом для критичных нагрузок: баз данных, виртуализации, ERP.
NAS (Network Attached Storage).
Файловый доступ по сети (NFS, SMB/CIFS). Прост в развёртывании и управлении, хорошо подходит для общих файловых хранилищ, бэкапов, медиаконтента. NAS актуален, но всё чаще выступает как часть гибридной инфраструктуры с поддержкой S3 API, автоматического тиринга и репликации в облако.
DAS (Direct Attached Storage).
Накопители, подключённые напрямую к серверу (SAS, SATA, PCIe) и, как правило, без сетевых соединений..Минимальные задержки и простота — его главные плюсы. Чаще всего используется внутри узлов виртуализации и HCI-кластеров, где программный слой уже сам собирает распределённое хранилище. Как отдельная СХД почти не применяется.
Object Storage (объектное хранилище)
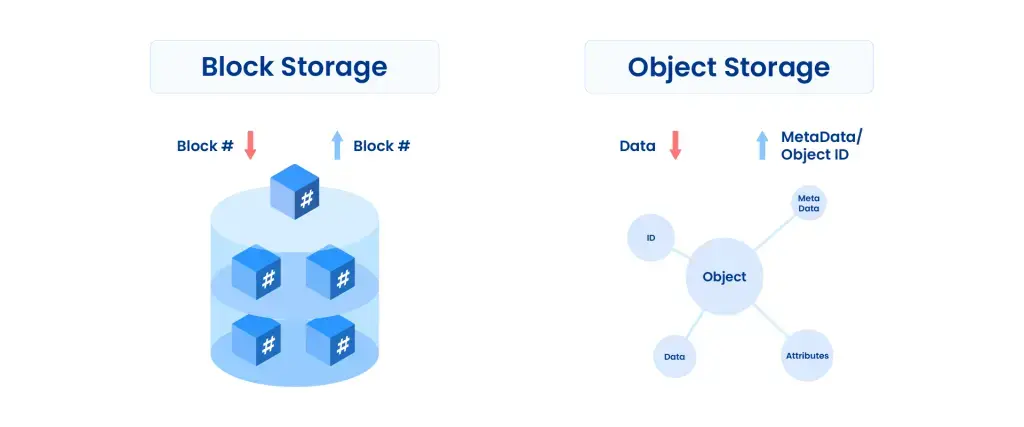
Работает через HTTP/S3 API, хранит данные в виде объектов с метаданными. Отлично масштабируется и подходит для бэкапов, архивов, ИИ-датасетов и медиаконтента. В корпоративной среде часто сосуществует с SAN/NAS, а не заменяет их.
Какой тип дисков выбрать для СХД
HDD (жёсткие диски)

Хороши для больших объёмов данных, где высокая производительность — не основной приоритет. У них относительно небольшая цена за ГБ. Современные серверные HDD (включая SMR/CMR и helium-диски) хорошо масштабируются по ёмкости и показывают достойную производительность в RAID и при последовательных нагрузках. Но они постепенно переходят в категорию комплектующих для тёплых и холодных данных, а также архивов.
SSD (твердотельные накопители)

Значительно быстрее и дороже HDD, у них высокая производительность и меньшее время отклика. Из минусов — сложнее прогнозировать отказ (HDD, поскольку являются механическими устройствами, чаще предупреждает заранее, мол, Хьюстон, у нас проблемы, памагити, а у SSD более вероятен внезапный сбой в электронике, хотя метрики износа тоже есть (SMART, wear-leveling, предсказание ресурса).
Есть разные классы SSD под разные задачи:
SATA SSD — бюджетный вариант для замены HDD;
SAS SSD — стабильность и отказоустойчивость в enterprise-среде;
NVMe SSD — минимальные задержки и максимальная производительность.

Также важно учитывать тип памяти. Та же QLC предлагает выше ёмкость и меньшую стоимость, но хуже подходит для интенсивной записи, поэтому часто используется в сочетании с кэшированием.
Какие выбрать интерфейсы дисков для СХД

SAS/SATA
Традиционные интерфейсы для серверных накопителей (SATA при этом давно перекочевал и в обычные ПК). SATA — это про доступность и массовость, SAS — про надёжность, масштабируемость и корпоративные сценарии. SATA в серверах чаще используют для холодных данных или как бюджетный вариант, а SAS — там, где важны стабильность, надежность и производительность. SAS выигрывает у SATA не только в скорости, но и в архитектуре: поддерживает dual-port (два пути доступа к диску), что позволяет строить отказоустойчивые схемы с многопутевым вводом-выводом (MPIO, Multipath I/O), ещё один плюс — более стабильная работа под нагрузкой и лучшая работа с очередями команд.
NVMe
Протокол, изначально заточенный под SSD и работу через PCIe. Его преимущество — не просто быстро, а другая модель работы с очередями и минимальные задержки. В реальных сценариях NVMe даёт кратное преимущество по IOPS и задержкам, особенно в нагрузках вроде баз данных, виртуализации и ИИ. К 2026 году NVMe — это стандарт для производительных систем.
ВАЖНО: NVMe вышел за пределы одного сервера — появился NVMe-oF (NVMe over Fabrics), позволяющий использовать NVMe по сети (через Ethernet или InfiniBand). Это прямой конкурент классического SAN.
SCSI
Устаревший интерфейс, который использовали в первых серверах и рабочих станциях. В отличие от IDE, SCSI позволял подключать много устройств к одному порту. Сейчас SCSI устарел, а на замену пришли более современные варианты, вроде SAS — это по сути эволюция SCSI (Serial Attached SCSI), а команды SCSI до сих пор используются в ряде протоколов (включая сетевой протокол iSCSI).
Fibre Channel (FC)
Здесь нужно небольшое уточнение. FC — это высокоскоростной сетевой протокол, который можно встретить в корпоративных средах, например, в сетях хранения данных (SAN). Основная роль FC — связать серверы и СХД в выделенную высокоскоростную сеть.
Со временем разработали жёсткие диски, которые можно напрямую (через FC-интерфейс) подключать к СХД и серверам, но использование FC-дисков — редкость, почти экзотика. Fibre Channel востребован в enterprise (16/32/64G FC), но с ним конкурируют NVMe-oF и Ethernet-решения (RoCEv2).
CXL (Compute Express Link)
CXL — не совсем интерфейс накопителей в привычном смысле, а новый тип соединения поверх PCIe, который меняет саму логику работы с памятью и устройствами.
Если раньше все ресурсы в устройстве были четко разделены — вот оперативная память, а вот диски, — то CXL это положение дел меняет. Он позволяет подключать к серверу внешнюю память и работать с ней почти как с локальной, с гораздо меньшими задержками, чем у NVMe.
В контексте СХД это важно потому, что часть задач можно переместить из классического хранилища ближе к памяти. Например, базы данных, аналитика или ИИ-нагрузки, где критичны низкие задержки, а не только производительность.
При этом CXL, разумеется, не заменяет ни SAS, ни тем более NVMe — это просто удобная надстройка над PCIe. Но со временем, возможно, он и изменит подход к работе с данными. На 2026 год это ещё не массовая история, но технологию активно внедряют крупные корпораты. Подробную статью про CXL можете почитать в нашем блоге на Хабре!
Какой RAID выбрать для СХД
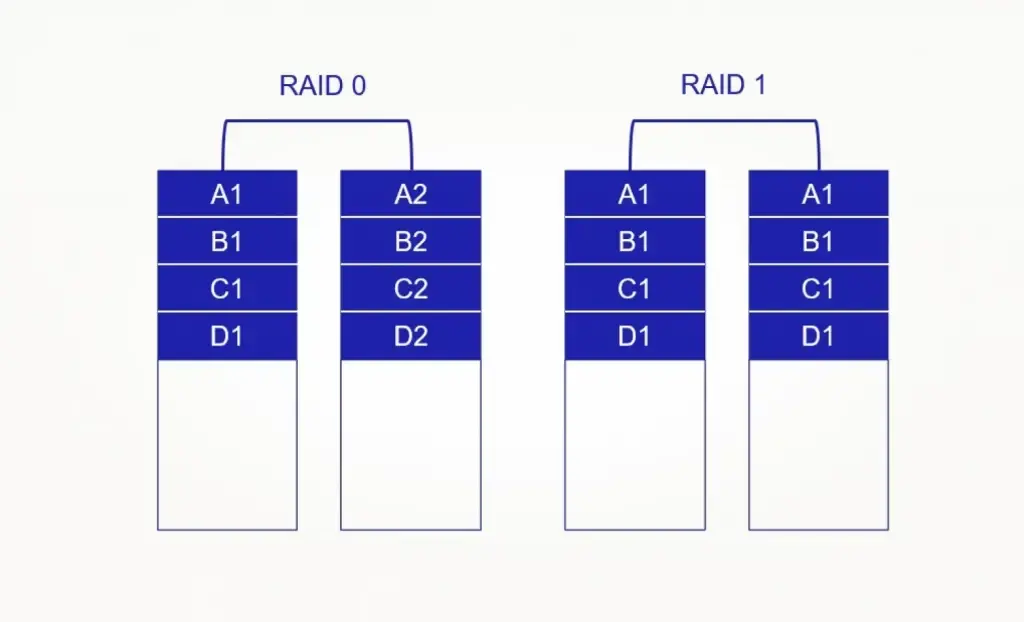
RAID (Redundant Array of Independent Disks) — технология, которая объединяет несколько накопителей в один логический массив. За счёт этого можно либо ускорить работу, либо повысить отказоустойчивость — но чаще ищут баланс между этими двумя крайностями.
Разные уровни RAID дают разные преимущества и недостатки:
RAID 0 — максимум производительности за счёт распределения данных по дискам (striping), но без какой-либо защиты: выходит из строя один диск — теряется всё;
RAID 1 — зеркалирование, простая и надёжная схема: данные дублируются, но половина объёма съедается;
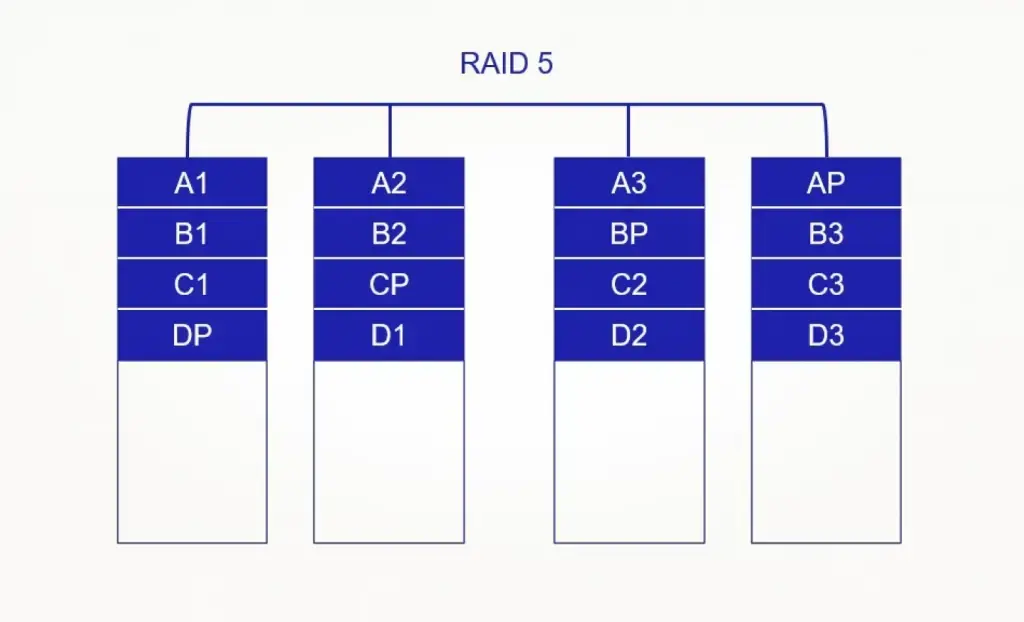
RAID 5 — данные и контрольная информация распределяются по дискам. В продакшене его избегают, так как восстановление массива (ребилд) после отказа одного диска может занимать десятки часов, а иногда и дни. Всё это время массив работает в деградированном состоянии, и если в этот момент откажет ещё один диск или всплывёт ошибка чтения (URE), можно потерять данные. Плюс из-за повышенной нагрузки другие диски тоже могут выйти из строя;
RAID 6 — то же самое, но уже с защитой от выхода из строя двух дисков, что актуально для массивов большой ёмкости;
RAID 10 — комбинация RAID 1 и RAID 0: высокая производительность плюс отказоустойчивость, но ценой в 50% полезного объёма.
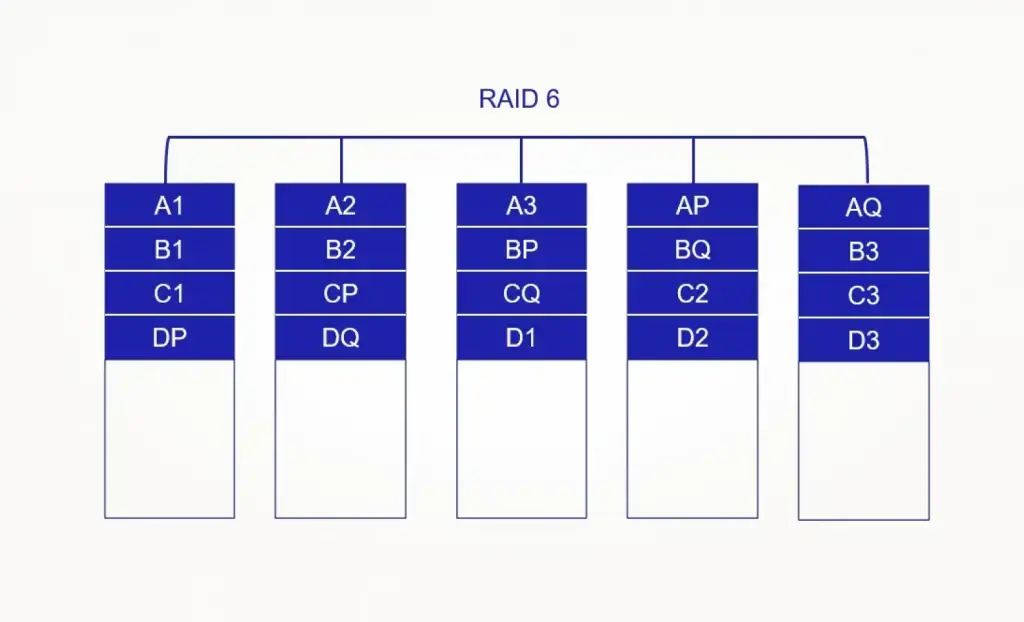
На практике выбор RAID сильно зависит от типа нагрузки: для баз данных и виртуализации чаще берут RAID 10 (минимальные задержки), для архивов и тяжёлых массивов — RAID 6.
Важно понимать, что RAID — это не замена бэкапам. Он защищает от отказа дисков, но не спасает от ошибок пользователя, сбоев ПО или зловредов.
Отдельный тренд последних лет — уход в сторону программных реализаций (SDS, HCI), где классические RAID дополняются или заменяются более гибкими механизмами (например, erasure coding), особенно в масштабируемых и распределённых системах.
Кэширование в СХД: разложим по полочкам
СХД могут работать с кэш-памятью, чтобы оптимизировать производительность. Кэширование — это временное хранение частоиспользуемых данных на быстрых (обычно твердотельных) носителях информации. Например, как у процессора есть L1/L2/L3-кэш, так и в СХД данные стараются держать как можно ближе к вычислениям — там, где меньше задержки и доступ быстрее.
В СХД есть разные уровни кэширования:
Read-Ahead Cache (кэш предварительного чтения): когда система читает блок данных, СХД может прочитать и следующие блоки с расчётом на то, что они скоро понадобятся. Это уменьшает задержки на чтение. Хорошо работает при последовательных нагрузках (например, бэкапы, стриминг, аналитика), снижая задержки за счёт угадывания доступа.
Write-Back Cache (кэш с отложенной записью): данные записываются сначала только в кэш. Запись в память начинается, когда кэш переполнен и ему нужно место для новых данных. Операция записи считается завершенной, как только данные попадают в кэш, что ускоряет процесс. Но при таком подходе необходимо обеспечить запись в память из энергозависимого (как оперативная память) кэша при сбое питания — поэтому такие СХД часто идут с отдельными батарейками или суперконденсаторами. Даже если пробки выбьет, батарейка (а в современных решениях — конденсатор) обеспечивает сохранение данных. За счёт батарейки данные копируются из кэша, а после устройство отключается. Если батарейка тоже выходит из строя, то кэш переключается на Write-Through, а в Write-Back доступен не будет. В современных средах кэширование дополняют уровнем хранения на NVMe и энергонезависимой PMem (в отдельных решениях).
Write-Through Cache (кэш со сквозной записью): в этом методе кэширования данные записываются одновременно и в кэш, и на диск. Это надёжно, но медленнее, чем отложенная запись, — поэтому чаще используется как fallback-режим или в системах, где критична консистентность.
Multi-level Cache (многоуровневый кэш): некоторые системы используют многоуровневое кэширование, где есть несколько уровней кэша с разной производительностью и стоимостью. Например, первый уровень использует быструю, но дорогую DRAM, а следующие уровни основаны на памяти помедленнее и подешевле (NVMe/SSD — кэш второго уровня или read/write tier). Многоуровневая система кэша разработана для оптимизации доступа к данным: чем чаще данные требуются обработчику данных (процессору, почти как обычный CPU в компьютере), тем ближе они должны находиться к нему (в более быстром кэше). Когда обработчик запрашивает данные, он сначала проверяет L1-кэш, затем L2, затем L3 и так далее, пока не найдёт нужные данные или не обратится к основной оперативной памяти.
Global Cache (глобальный кэш): это кэш, который доступен для всех контроллеров в среде СХД. Он обеспечивает более эффективное использование ресурсов памяти по сравнению с отдельными кэшами для каждого контроллера. Позволяет избегать ситуаций, когда один контроллер перегружен, а у другого кэш простаивает.
Mirrored Cache (зеркальный кэш): данные в кэше дублируются на другом контроллере или узле для высокой доступности и защиты от сбоев. В современных СХД кэш часто распределён между узлами кластера.
Некоторые СХД используют кэш-память для повышения производительности. Кэширование может быть реализовано на уровне диска или на уровне всей системы (или даже нескольких систем). Идём дальше.
Резервирование данных и возможности аварийного восстановления СХД

Выбор подходящей системы хранения данных — это не только вопрос её производительности или масштабируемости, но и способности эффективно резервировать информацию и быстро восстанавливать её при необходимости.
Представим, что информация в вашей системе — это бесценное произведение искусства, которое выставлено в музее. Экспонаты в музее надёжно защищены, но также есть и копии этих произведений, которые выставляют вместо оригинала (да-да, не факт, что вы Апофеоз войны увидели в Третьяковке, а не искусную копию). Обычно это делают для реставрации или для защиты от кражи и порчи.
Резервирование данных — это как создание этих копий для вашего бизнеса.
Однако резервирование данных — это только половина дела. Важно уметь быстро и корректно восстанавливать данные в случае их потери или повреждения. Да, если в музее всё сгорит при пожаре, то копия картины не заменит оригинал. Но нам повезло, что мы работаем с данными — здесь резервная копия ничем не отличается.
Итак. Время и точность здесь критически важны: каждая секунда простоя может стоить компании больших денег, именно поэтому быстрое восстановление — одна из ключевых характеристик хорошей системы.
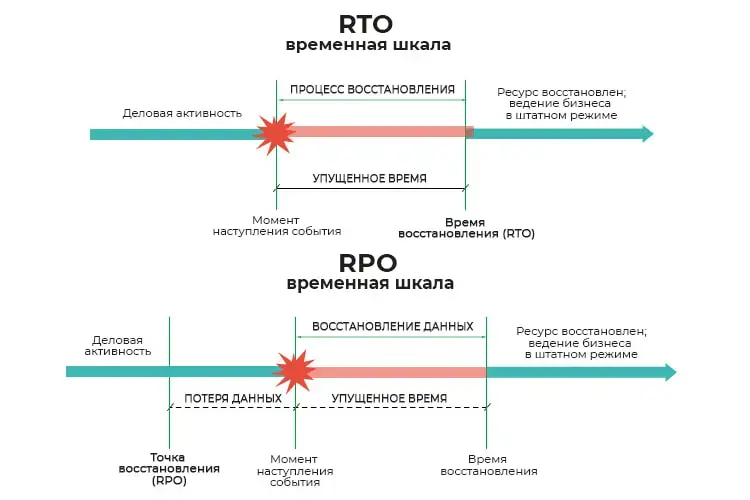
И здесь пора познакомиться с метриками времени восстановления aka RTO (Recovery Time Objective) и точки восстановления aka RPO (Recovery Point Objective). RTO — это время, за которое данные должны быть восстановлены после сбоя, а RPO — это сколько данных вы можете позволить себе потерять.
Давайте посмотрим на проблему глазами админа. Помните я говорил, что не все данные одинаково важны? Некоторую информацию можно восстановить из еженедельных резервных копий, а другую информацию, например, финансовые транзакции банка могут требовать синхронного резервного копирования, так как за секунду происходят тысячи и миллионы транзакций.
Также стоит учесть и место, где хранятся резервные копии.
Травмированные опытные сисадмины хранят несколько копий в разных физических местах по стратегии 3-2-1 (три копии данных на двух разных носителях, одна из которых хранится вне основной площадки) остаётся фундаментом надёжности. Однако сегодня её дополняют двумя механизмами защиты от программ-вымогателей: неизменяемые (иммутабельные aka immutable) резервные копии — их невозможно изменить, удалить или зашифровать даже с правами администратора; копии air‑gap — физически или логически изолированные от сети, исключающие удалённое заражение.
Если ваши данные и их резервная копия хранятся в одном помещении, то вы рискуете потерять всё при пожаре, потопе или краже.
Неважно, насколько мощная и современная у вас СХД — она уязвима для внешних угроз, а потому без надёжных механизмов резервирования и восстановления нельзя. Особенно крупному бизнесу.
И не забывайте тестировать восстановление! Если вы ни разу не пробовали восстановиться — у вас нет бэкапа.
Интеграция с существующей инфраструктурой и совместимость СХД
Итак, плавно подходим к концу. Осталось ещё парочка важных моментов: интеграция с существующей инфраструктурой и совместимость.
Если вы купите СХД, которая не работает с вашими текущими программами и оборудованием, то это будет как покупка PlayStation 5 к старому кинескопному телевизору — даже подключить не получится без костылей.
С СХД такое возможно, если ваше IT-оборудование разных производителей, поколений и/или назначений. При этом для устаревшей IT-инфраструктуры очень сложно подобрать современную СХД (и раскрыть её потенциал). Придётся сидеть со своим кинескопным ТВ и PlayStation 1, пока не модернизируете всё это добро.
Что сделает опытный сисадмин для совместимости и нормальной интеграции СХД? Проведёт предварительный аудит IT-инфраструктуры до покупки нового оборудования. Определит, какие технологии, стандарты и интерфейсы есть в IT-среде, а какие устарели и требуют апгрейда. Прикинет все за и против, взвесит бюджет и примет решение.
Последнее: IT-индустрия вошла в равноускоренное падение (новые требования из-за ИИ, Big Data и облачные сервисы. Вы берёте систему, которая идеально подходит сейчас, но через 3–5 лет архитектура может потребовать модернизации из-за роста данных и новых нагрузок (ИИ, аналитика). А значит цикл обновления можно повторять, но перед этим нужно рассчитать экономическую эффективность и окупаемость инвестиций.
Экономическая эффективность и окупаемость инвестиций (ROI) в СХД

Мысленный эксперимент.
Компания Peace Data занимается анализом данных для благотворительных организаций и планирует заменить старую СХД на более современное решение. Но есть важные критерии выбора: экономическая эффективность и окупаемость инвестиций (ROI).
Исходные данные:
Старая система стоила компании $50 000 и служила 5 лет. За это время на обслуживание и ремонт было потрачено еще $10 000.
Новая система будет стоить $80 000 долларов, но ожидается, что срок её службы составит не менее 8 лет, а обслуживание будет стоить всего $1 000 в год.
Ремарка! В реальной жизни расчёт будет сложнее. Учитывают лицензии, поддержку, энергопотребление, плотность хранения, стоимость стойко-места и — самое неприятное — цену простоя. Здесь всё упрощено, чтобы увидеть сам принцип. Я же сильно упростил для наглядности. Все оценки условны, а реальные суммы зависят от вендора и лицензирования. |
Как рассчитать экономическую эффективность и окупаемость (ROI) для СХД
Я приведу простые денежные расчёты. Однако новая система подтянет уровень сервиса, скорость и надёжность системы. Можно получить не только прямую денежную выгоду, но и больше довольных клиентов, как новых (привлечение), так и старых (удержание). Да, выбор подходящей СХД влияет и это.
Расчёт экономической эффективности СХД:
Расчёт среднегодовых затрат на старую систему: (50 000 (начальные затраты) + 10 000 (обслуживание))/ 5 (лет) = $12 000 в год.
Прогноз затрат на новую систему за 8 лет: 80 000 (начальные затраты) + 1000 (обслуживание) x 8 (лет) = $88 000 за 8 лет.
Расчёт среднегодовых затрат на новую систему: 88 000 / 8 = $11 000 в год.
Сравнивая эти числа, "Peace Data" видит, что новая система будет стоить на $1 000 в год дешевле.
На первый взгляд разница небольшая — всего $1 000 в год. Но компания Peace Data, видит, что новая система не только лучше технологически, но и дешевле в эксплуатации.
Расчет окупаемости инвестиций (ROI) для СХД:
Допустим, благодаря новой системе, компания сможет обрабатывать больше заказов и увеличит свою прибыль на $17 000 в год. И вдобавок смогла продать старую систему за $20 000. Формула: ROI = (Доход– Затраты) / Затраты х 100%.
ROI: (17 000 (доп. прибыль) x 8 (лет) - 60 000 (стоимость новой системы после продажи старой)) / 60 000 x 100% = 126,6%
За 8 лет компания не только полностью отбивает вложения, но и зарабатывает сверху ~26,6%. А также есть и косвенные эффекты: больше клиентов, выше SLA, меньше простоев и штрафов, так как современная платформа производительнее, отказустойчивее и лучше масштабируется без замены оборудования.
ВАЖНО! В тщательных расчётах нужно оценивать и скрытые расходы старой системы: рост стоимости обслуживания с возрастом, дефицит запчастей, увеличение времени простоя при отказах, ограничение по масштабированию (которое тормозит бизнес) |
Выводы
Не стоит идти на компромисс, выбирая дешёвую систему здесь и сейчас, которая невыгодна на длинных дистанциях.
Скупой сисадмин не тратит деньги на надёжный СХД — он тратит деньги на психотерапевтов :) Но на практике админ — это просто исполнитель, которому достаётся от разъярённых сотрудников с факелами и вилами, а он лишь пытается уложиться в бюджет. Не надо так.
Не переплачивайте за функции или характеристики, которые вам не нужны, но и не экономьте чрезмерно на архитектуре, ведь ошибки и простои стоят дороже железа. Помните, что сисадмин — ваш друг, который будет искать баланс между ценой, производительностью и надежностью для правильного подбора СХД с хорошей окупаемостью.
Если штатного админа, который подберёт оптимальное решение, нет, то обращайтесь к менеджерам Сервер Молл. Наши специалисты подберут оборудование под задачу и бюджет, а КП отправят за час.








{kind=link}