

И снова привет!
В первой части сравнения Ceph и VMware vSAN я разобрал их философию, различия, версии и лицензирование (материал можно почитать здесь) — там было много теории и немного про организационные нюансы и деньги.
Ну а поскольку программно-определяемые хранилища (Software-Defined Storage, SDS) по больше части упираются в архитектуру, сайзинг железа (подбор конфигурации серверного и сопутствующего оборудования под конкретную нагрузку), топологию сети, руки админов, IT-архитекторов и иных причастных (тех, кто всё это дело собирает и сопровождает), то пора переходить от концепций к практике.
Из этого лонгрида-сравнения Ceph и VMware vSAN вы узнаете:
Про архитектуру и интеграцию;
Про минимальные требования к кластерам и установку (включая обновления);
Отдельно про сетевую инфраструктуру с полезными практиками;
Про масштабирование и рост;
Про отказоустойчивость и защиту данных;
Про администрирование, мониторинг и обслуживание.
Ремарка! Материал технически непростой — он рассчитан на людей с опытом в IT: сисадминов, технических директоров, IT-архитекторов и т.д. По возможности я буду оставлять ссылки на терминологию, которая у неподготовленного читателя будет вызывать вопросы, но давать определение каждому термину в рамках статьи я не стану, чтобы не раздувать объём и без того немаленького лонгрида. Поэтому, если вы новичок, запаситесь терпением и готовьтесь самостоятельно изучать теорию по ходу чтения.
Рекомендую изучить первую часть — с ней будет проще разобраться в сабже.
Обе статьи статьи в нашем блоге — самые подробные материалы с сравнением Ceph и vSAN в Рунете! Так что чайничек листового лишним не будет, а эту статью добавляйте в закладки (Ctrl + D), чтобы не потерять.
Начинаем.
Архитектура, производительность и интеграция: Ceph vs VMware vSAN
Ceph и vSAN — это два конкурирующих продукта и два разных подхода к хранению данных. Для начала сравним архитектуры и интеграцию, а следом перейдём к подбору железа, масштабированию, производительности, отказоустойчивости, администрированию и TCO. В конце самых сложных разделов будут итоговые таблицы с кратким и наглядным содержанием.
Коротко про архитектуру и интеграцию Ceph
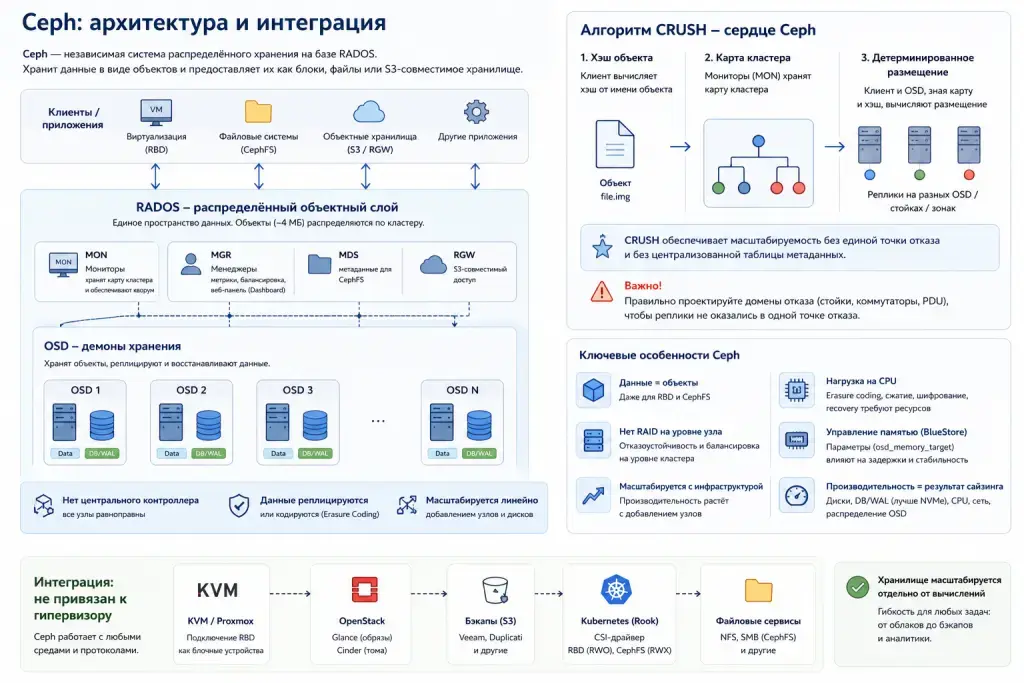
Ceph — это независимая система распределённого хранения на базе RADOS (Reliable Autonomic Distributed Object Store), слоя, через который общаются клиенты и кластер. Она не зависит от конкретного гипервизора и может отдавать данные как блочные устройства, как файловую систему или как S3-совместимое объектное хранилище. Кластер Ceph состоит из мониторов (MON), управляющих картами кластера, множества демонов OSD для хранения и репликации данных, метаданных MDS (для CephFS), менеджеров (MGR) с веб-панелью, при необходимости — MDS для CephFS и RGW для S3-совместимого доступа, и других сервисов.
Ремарка! Де-факто данные в Ceph хранятся в виде объектов, даже если вы работаете с блочными RBD или файловой CephFS — такая вот абстракция над объектным ядром.
Ceph работает на уровне мельчайших объектов (обычно 4 МБ), что позволяет ему равномерно размазывать кусочки каждой виртуальной машины по всем дискам кластера и восстанавливать потери параллельно с тысяч дисков.
ВАЖНО! В Ceph нет главного контроллера, через который проходит весь трафик. Распределение данных рассчитывается алгоритмом CRUSH (Controlled Replicated Under Scalable Hashing) на основе хэширования и карты кластера, которую поддерживают мониторы. Клиент и OSD, зная карту и хэш-имя, вычисляют размещение детерминировано. Если сервер упадёт, или вы добавите накопитель/сервер — карта кластера обновится.
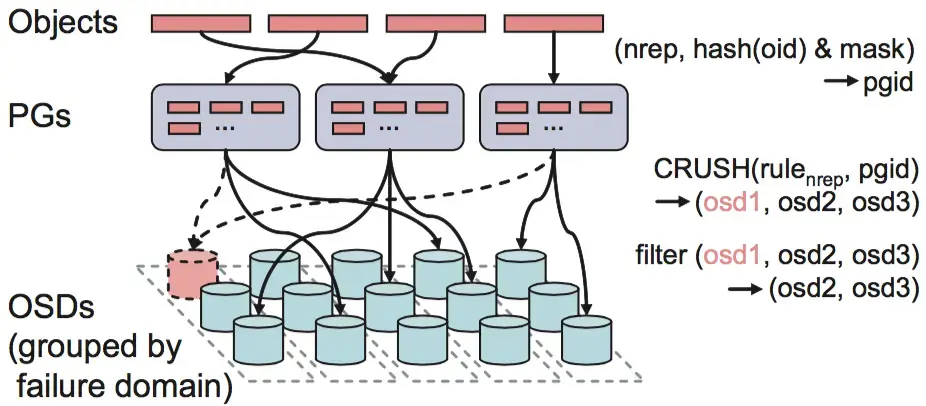
CRUSH — это главная архитектурная фича и преимущество Ceph, которая позволяет ему работать без централизованной таблицы метаданных (в отличие от многих других SDS). Это и даёт Ceph масштабируемость без бутылочного горлышка — система не упирается в один центральный контроллер, который маршрутизирует ввод/вывод.
Но если неправильно описать домены отказа failure domain (про это будет в разделе про отказоустойчивость), то при сбоях вы можете потерять, например, все реплики. Поэтому важно проектировать отказ не только накопителя, а целой стойки или коммутатора (обычно неожиданностью оказывается отказ не отдельного диска, а ToR-коммутатора или PDU).
Такая архитектура напрямую влияет на производительность. Ceph масштабируется вместе с инфраструктурой. Производительность здесь — это результат сайзинга: какие используются накопители, как распределены OSD, где размещены DB/WAL и насколько сбалансированы CPU и сеть. Использование NVMe под DB/WAL заметно снижает задержки и увеличивает IOPS, особенно при нагрузках с большим количеством мелких операций.
Важный момент — CPU. В Ceph он активно участвует в обработке данных: erasure coding, сжатие, шифрование и recovery. Эти процессы сильно нагружают процессор, поэтому слабые CPU могут стать узким местом даже при быстрых NVMe. Плюс Ceph управляет памятью самостоятельно (через BlueStore и параметры вроде osd_memory_target), что напрямую влияет на задержки и стабильность под нагрузкой. В отличие от классических СХД, здесь нет RAID на уровне узла — вся отказоустойчивость и балансировка происходят на уровне кластера, а значит и вся нагрузка распределяется между узлами.
Интеграция: Ceph не связан с конкретным гипервизором, его можно интегрировать почти с любыми средами. Хотите — подключайте RBD к KVM или Proxmox. Для OpenStack он и вовсе стал стандартом де-факто, закрывая сразу все потребности: от хранения образов Glance до дисков Cinder. Хотите — отдайте S3 под бэкапы (например, Veeam, Duplicati). Хотите — интегрируйте с Kubernetes через Rook, а CSI-драйвер предоставит тома для подов (RBD — для RWO, CephFS — для RWX).
Такая архитектура и гибкость позволяют масштабировать хранилище отдельно от вычислений, что огромный плюс в задачах и инфраструктурах, где нагрузка на хранилище растёт быстрее, чем требования к вычислительным мощностям кластера (или наоборот).
Коротко про архитектуру и интеграцию VMware vSAN
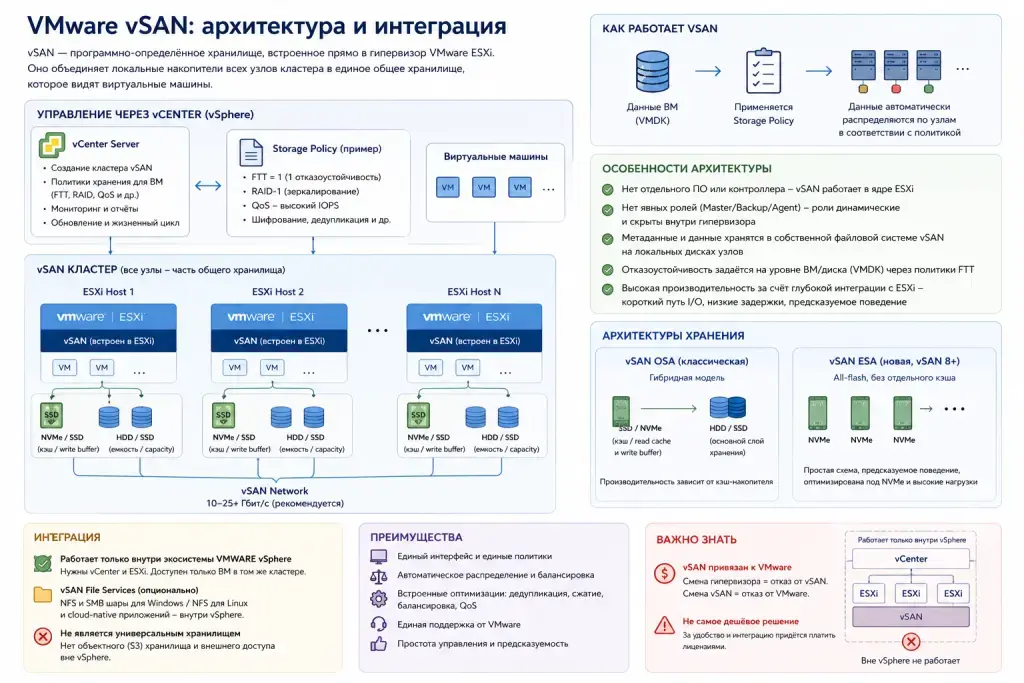
VMware vSAN — проприетарное программно-определённое хранилище, встроенное прямо в гипервизор VMware ESXi. Это не отдельное решение, вроде дополнительного ПО или СХД, а программный слой, который объединяет локальные накопители всех узлов кластера в единое общее хранилище. Физически данные хранятся на накопителях внутри серверов, но логически — это одно общее хранилище, которое видят виртуальные машины кластера.
ВАЖНО! vSAN тесно интегрирован с экосистемой VMware vSphere и работает только в ней. Для работы нужны vCenter и ESXi, а vSAN-диск доступен только виртуальным машинам (ВМ) в том же кластере. Через vCenter идёт управление— там задаются политики хранения для ВМ (количество копий — FTT, RAID-профили, QoS). Вы определяете, сколько отказов должна выдерживать ВМ, использовать ли зеркалирование или кодирование с избыточностью, какие требования к производительности применить. А через гипервизор ESXi (на каждом хосте кластера) происходит всё, что связано с обработкой данных и операциями ввода-вывода (I/O) — он автоматически распределяет данные по узлам в соответствии с заданными политиками и правилами.
У vSAN нет явного разделения на роли, которые нужно настраивать вручную, как в Ceph — нет ни мониторов, ни демонов хранения. Роли как бы есть (Master, Backup, Agent), но они динамические и скрыты в ядре гипервизора ESXi, а метаданные и данные хранятся в собственной файловой системе vSAN, которая работает на локальных накопителях в серверах.
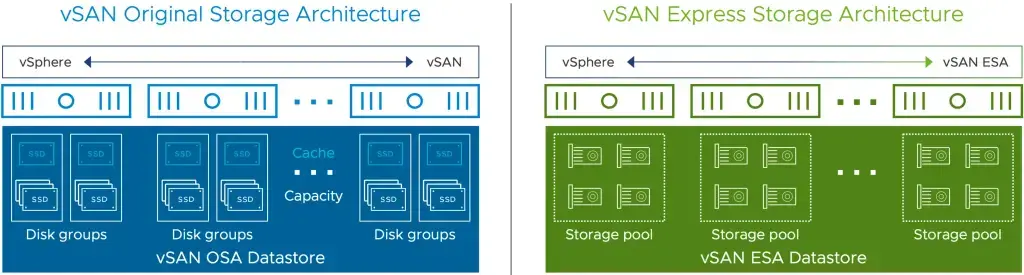
В классической архитектуре vSAN OSA (Original Storage Architecture) реализована гибридная модель хранения: быстрые NVMe или другие SSD работают как буфер записи и кэш чтения, а ёмкие, но относительно медленные HDD (или SSD для all-flash массивов) — как основной слой хранения (write buffer и read cache соответственно). Производительность здесь будет зависеть от кэш-накопителя.
В новой архитектуре vSAN ESA (Express Storage Architecture, появилась в vSAN 8) отдельного кэша уже нет. Система заточена под NVMe и работает с другим механизмом записи. Важно, что это альтернативная архитектура, а не полная замена. С ней схемы размещения данных становятся проще, а поведение предсказуемее при высоких нагрузках. При этом часть оптимизаций уже встроена: дедупликация, сжатие, балансировка и политики размещения работают на уровне платформы, а администратор управляет ими через Storage Policy, не погружаясь в низкоуровневую механику.
Высокая производительность vSAN достигается за счёт глубокой интеграции с гипервизором — здесь минимум абстракций, а значит и путь у данных короче: операции ввода-вывода обрабатываются непосредственно в ESXi, без отдельного слоя хранения, как в Ceph. За счёт этого задержки ниже, а поведение системы предсказуемее без сложной настройки.
И ещё про отказоустойчивость (подробнее будет в разделе ниже) — VMware vSAN применяет политики отказоустойчивости к целой виртуальной машине или её диску (VMDK), что проще для понимания и управления, чем в Ceph, но мы получаем тяжелое и менее гибкое восстановление при неравномерной нагрузке.
Интеграция: vSAN — это именно хранилище для ВМ внутри кластера VMware. Сменить гипервизор — значит отказаться от vSAN, а сменить vSAN — значит отказаться от VMware (мнение автора: не самое плохое решение в 2026 году, учитывая цены на лицензии). Как универсальное файловое или объектное решение со внешним доступом оно не подходит, так как всё работает в рамках vSphere. Например, vSAN File Services — опциональная функция (прямо поверх кластера vSAN), которая позволяет отдавать файловые NFS и SMB шары для Windows-систем и/или делать NFS-экспорты для Linux-систем и cloud-native приложений. Но это всё ещё работает внутри экосистемы vSphere.
Зато в пределах владений vSAN даёт единый интерфейс, единые политики и единую поддержку. Для бизнеса такая понятная, управляемая и предсказуемая система часто важнее всего остального. Но за такое удобство готовьтесь платить.
Таблица-сравнение Ceph и VMware vSAN:
Параметр
Ceph
VMware vSAN
Тип архитектуры и технологии хранения
Распределённая система (RADOS); блоки (RBD), файлы (CephFS), объекты (RGW, S3 API).
Гиперконвергентное блочное хранилище, встроенное в гипервизор ESXi (vSphere); блоки (виртуальное хранилище для ВМ); файловая подсистема vSAN File Service (опционально, работает сложнее, чем CephFS).
Консистентность
Сильная (после записи все читают одно и то же).
Сильная (для ВМ это обязательно).
Масштабирование, минимальный и максимальный кластер
Почти неограниченно – добавление OSD-узлов или кластеров; гибкое расширение; минимум 3 узла (или 1 для тестов, но это не в прод); масштабируется горизонтально (добавлением серверов) практически до бесконечности.
До 64 хостов на один кластер; вертикальное масштабирование (NVMe, SSD) на хостах; минимум 2 узла + 1 свидетель (или 3+ узлов); vSAN ограничен лимитами кластера vSphere (но 64 узла — это очень много).
Типовой узел кластера
MON, MGR, OSD (на любом x86 железе). Гибкий выбор дисков.
OSA: кэш + данные. ESA: единый пул NVMe. Строго из Hardware Compatibility List (HCL).
Сеть
Рекомендуется ≥10 Гбит/с (лучше 25/40/100 Гбит/с) между узлами.
Рекомендуется ≥10 Гбит/с между ESXi-хостами (выделенный стек TCP/IP для трафика vSAN, критичны задержки).
Администрирование
Оркестратор (cephadm) — основной способ, CLI/REST API, Ceph Dashboard, Prometheus/Grafana; требуются навыки Linux и Ceph.
Управление через vSphere Client/vCenter; знакомые VMware-интерфейсы; поддержка Skyline.
Отказоустойчивость
Репликация (по умолчанию 3 копии) или Erasure Coding; мониторы с кворумом устраняют SPOF, растянутый кластер, но сложнее, чем в vSAN — нужны CRUSH-карты и глубокие компетенции.
Политики FTT (Failures to Tolerate); минимум 3 узла (или 2 + свидетель); восстановление после отказов встроено в стек: (перестроение копий/паритетов) происходит автоматически на уровне гипервизора, без внешних RAID-контроллеров, есть классная нативная фишка — Stretched Cluster (растянутый кластер между ЦОДами).
Сообщество/поддержка
Open-source (сообщество) + коммерческая поддержка (Red Hat, SUSE, Canonical и др.).
Проприетарно: поддержка только от VMware (в составе подписок vSphere/vSAN).
Минимальные требования к кластеру и установка Ceph
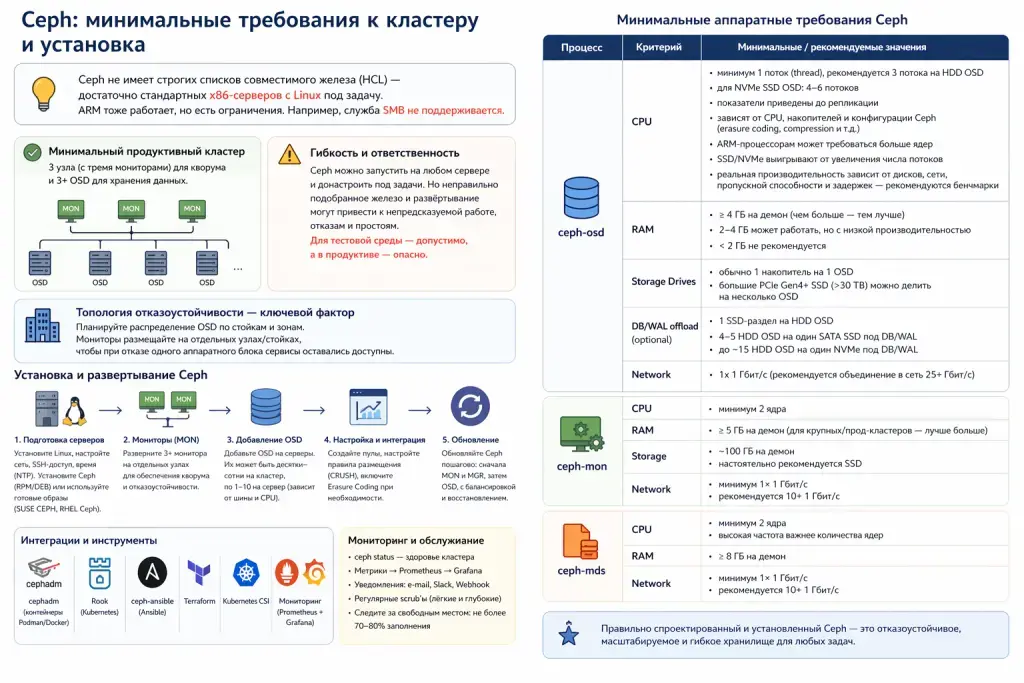
Ceph не имеет строгих списков совместимого железа (HCL, Hardware Compatibility List) — достаточно недорогих стандартных x86-серверов с Linux, сконфигурированных под задачу.
Ремарка! С ARM тоже работает, но есть ограничения. Например, служба SMB не поддерживается.
Как правило под MDS, MON/MGR и OSD делают отдельные узлы Ceph, а потому минимальный кластер для прода начинается с 3 узлов (с тремя мониторами) для отказоустойчивости и 3+ OSD для хранения данных.
Главная фича Ceph в том, что он гибок – можно выбрать любой калькулятор сервер, поставить Linux и при необходимости всё донастроить, докупить, докрутить. Требования к одному кластеру Ceph отличаются от требований к другому. Но это же и его слабое место — неправильно подобранное железо и развёртывание могут привести к непредсказуемой работе, отказам и простоям. Для тестовой среды это допустимо, а вот в продакшене — опасно.

Dell PowerEdge R770 — универсальный сервер, один из лучших серверов в своём классе
Итак, Ceph поддерживается многими вендорами первой величины (Dell, HPE, Lenovo и др.), которые поставляют серверы и комплектующие для Ceph-кластеров. Для Ceph архиважна топология отказоустойчивости — нужно продумать распределение OSD по стойкам и зонам, спланировать размещение мониторов на отдельных узлах/стойках, чтобы при отказе одного аппаратного блока сервисы оставались доступными.
При установке вручную нужно подготовить серверы Linux, настроить сетевые интерфейсы, SSH-доступ и установить Ceph RPM/DEB. Существуют образы (SUSE CEPH, Red Hat Ceph Storage) с преднастроенной ОС. Мониторы развёртываются по 3+ нодам для кворума. Затем добавляются OSD: их может быть десятки-сотни на кластере, по 1-10 на сервер (зависит от шины и CPU).
Ceph можно интегрировать с Ansible, Terraform, Kubernetes (CSI, Rook). Современный способ администрирования — утилита cephadm, которая разворачивает кластер в контейнерах (Podman/Docker). Альтернативно используются инструменты Rook (для Kubernetes) и ceph-ansible. Обновление Ceph идёт пошагово: сначала мониторы и менеджеры, затем OSD, с балансировкой и восстановлением после каждого шага.
Минимальные аппаратные требования Ceph:
Процесс
Критерий
Минимальные / рекомендуемые значения
ceph-osd
CPU
• минимум 1 поток (thread), рекомендуется 3 потока на HDD OSD
• для NVMe SSD OSD: 4–6 потоков
• показатели приведены до репликации
• зависят от CPU, накопителей и конфигурации Ceph (erasure coding, compression и т.д.)
• ARM-процессорам может требоваться больше ядер
• SSD/NVMe выигрывают от увеличения числа потоков
• реальная производительность зависит от дисков, сети, пропускной способности и задержек — рекомендуются бенчмарки
RAM
• ≥ 4 ГБ на демон (чем больше — тем лучше)
• 2–4 ГБ может работать, но с низкой производительностью
• < 2 ГБ не рекомендуется
Storage Drives
• обычно 1 накопитель на 1 OSD
• большие PCIe Gen4+ SSD (>30 TB) можно делить на несколько OSD
DB/WAL offload (optional)
• 1 SSD-раздел на HDD OSD
• 4–5 HDD OSD на один SATA SSD под DB/WAL
• до ~15 HDD OSD на один NVMe под DB/WAL
Network
• 1x 1 Гбит/с (рекомендуется объединение в сеть 25+ Гбит/с)
ceph-mon
CPU
• минимум 2 ядра
RAM
• ≥ 5 ГБ на демон (для крупных/прод-кластеров — лучше больше)
Storage
• ~100 ГБ на демон
• настоятельно рекомендуется SSD
Network
• минимум 1× 1 Гбит/c
• рекомендуется 10+ 1 Гбит/c
ceph-mds
CPU
• минимум 2 ядра
• высокая частота важнее количества ядер
RAM
• ≥ 8 ГБ на демон
Network
• минимум 1× 1 Гбит/c
• рекомендуется 10+ 1 Гбит/c
Минимальные требования к кластеру и установка vSAN

vSAN в базовой конфигурации требует минимум 3 хоста ESXi (вместо третьего хоста возможно подключение свидетеля). На каждом хосте нужно как минимум по одному SSD/NVMe (в современных версиях) для кэша и один или несколько накопителей для данных (тут уже по требованию: можно NVMe, а можно HDD). VMware vSAN поддерживает только строго сертифицированное оборудование по HCL, включая версии прошивок накопителей и контроллеров (vSAN ReadyNodes — предварительно сконфигурированные серверные решения, сертифицированные для работы с VMware vSAN), либо специализированные HCI-апплиансы (например, Dell VxRail, HPE SimpliVity). Это обеспечивает согласованность конфигураций, но ограничивает выбор и делает закупки дороже. vSAN HCI-узел строится по проверенной схеме: выделяется (минимум) один NVMe в кэш, один HDD/SSD в хранение; конфигурации сверяются с HCL. Также необходимо согласовать версию BIOS/UEFI/прошивок для предсказуемости (что, к слову, актуально и для крупных Ceph-кластеров).
Процесс установки vSAN по сути требует от админа только знания VMware-инструментов — с документацией там полный порядок. Администрируется он в основном через GUI vSphere, но есть и альтернативы — PowerCLI и REST API (с vSphere 7+). vSphere Lifecycle Manager (vLCM) упрощает обновление ESXi и прошивок узлов vSAN через типовой образ. Настройка идёт через vCenter: создаёте vSphere Cluster, включаете vSAN, указываете, какие диски использовать для кэша и хранения. Далее vSAN сам склеит их в дисковые группы (Legacy OSA) или пулы (ESA). Следом можете задать политики хранения (FTT, арена, шифрование, дедупликация и т.д.). В чистом виде можно развернуть 3–64 ESXi хоста в одном кластере. При этом стоит иметь ввиду, что ряд функционала — вроде дедупликации и шифрования — не будет работать на гибридном решении (SSD+HDD), только на all-flash. VMware как бы заботится и не даёт выстрелить себе в ногу, что является и плюсом, и минусом.
Подытожу. vSAN ограничивает вас на этапе закупки и проектирования, а Ceph — на этапе эксплуатации. vSAN не даст сделать ошибку за счёт жёсткого HCL и проверенных конфигураций, а в Ceph любые архитектурные просчёты проявятся, к сожалению, под нагрузкой в проде — роста задержек, деградация восстановления и неравномерное распределение данных. Если выбираете Ceph, то придётся думать и до развёртывания, и на всём жизненном цикле кластера — от топологии до балансировки и обновлений. vSAN тоже наказывает, но на этапе выбора железа и лицензий (и оплаты подписок), зато даёт больше предсказуемости.
В реальных проектах обычно всё ограничивает сеть (сводит на нет преимущества быстрых NVMe и грамотного сайзинга): ошибки в сегментации, oversubscription (переподписка — ситуация, когда суммарная пропускная способность всех клиентских портов превышает ёмкость магистрального — восходящего — канала) или недостаточная пропускная способность.
Поэтому, если опытной команды по работе с Ceph у вас нет, имеет смысл закладывать пилотный кластер и время на тестирование — уверяю, что ошибки будут, а в проде они могут обойтись дороже, чем лицензии vSAN.
Минимальные аппаратные требования vSAN:
Компонент / хост ESXi
Критерий
Минимальные / рекомендуемые значения
ESXi host (vSAN node)
CPU
• минимум ~16 ядер на хост (актуальные ReadyNode-профили)
• больше ядер требуется при высокой плотности VM и использовании ESA
RAM
• зависит от числа устройств и архитектуры
• минимум для современных ReadyNode-профилей: от ~128 GB
• для vSAN ESA: ≥128 GB (минимум по techdocs)
• для production ESA-профилей обычно значительно выше (сотни GB)
Storage (devices)
• требуется минимум один cache tier и один capacity tier (OSA)
• в ESA используется единый storage tier (all-NVMe)
Storage type
• OSA: SSD/HDD (гибрид или all-flash)
• ESA: только NVMe (all-flash архитектура)
Disk groups / storage pools
• OSA: минимум 1 disk group (cache + capacity)
• ESA: storage pool (без разделения на cache/capacity)
Network
• минимум: 1 Гбит/c (теоретический минимум и базовое требование)
• практический минимум: 10–25 Гбит/c
• для ESA: от 25 Гбит/c и выше (рекомендуется 25–100 Гбит/c)
Controller / HBA
• должен поддерживаться и быть в списке совместимости (passthrough или RAID0)
Hardware compatibility
• строгое требование: оборудование из Broadcom Compatibility Guide (vSAN ReadyNode или сертифицированные компоненты)
vSAN cluster
Минимальное число узлов
• 3 хоста ESXi (или 2 + witness)
Максимальный размер кластера
• до 64 хостов
Сеть кластера
• Layer 2 или Layer 3 сеть между всеми узлами
Однородность
• совместимые версии ESXi, драйверов и прошивок обязательны
Конфигурации
• рекомендуется использовать vSAN ReadyNode — преднастроенные и сертифицированные конфигурации
Отдельно про сетевую инфраструктуру Ceph и vSAN: полезные практики
Оба решения, как и любые SDS, сильно зависят от сети, поэтому про неё распишу чуть подробнее.
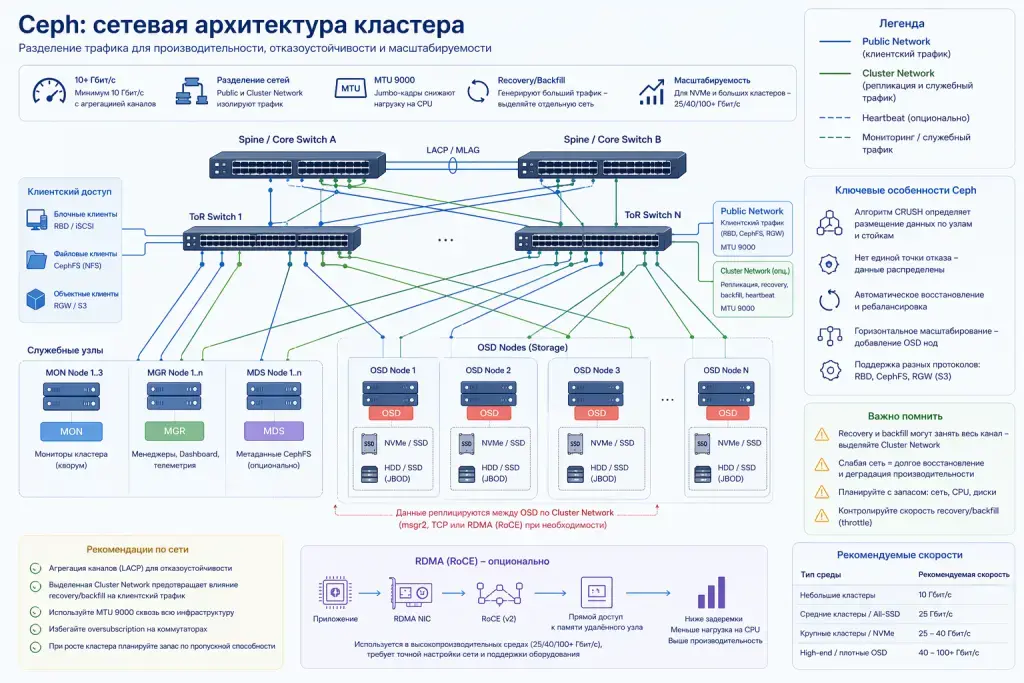
Ceph ориентирован на 10 Гбит/c Ethernet и выше — при медленной сети время репликации и восстановления данных сильно увеличивается. В официальных рекомендациях Ceph указаны минимум 10 Гбит/c с агрегацией каналов для отказоустойчивости. Если сеть 1 Гбит/c будет постоянно занята репликацией, то переход на 10 Гбит/c и выше доводит время восстановления до приемлемого. Учтите, что Ceph при recovery (восстановление) и backfill (перебалансиорвка — процесс переобработки исторических данных с применением новой или исправленной логики) генерирует очень агрессивный трафик, который может съесть весь канал.
Лучше всего использовать отдельные физические или логические сети: Public Network (для клиентов) и опционально отдельную Cluster Network (для репликации и восстановления) — это не даст трафику восстановления влиять на производительность приложений.
Ещё можно использовать Jumbo-кадр (MTU 9000) для снижения нагрузки на CPU: эффект есть при сквозной настройке MTU на всех узлах и коммутаторах (можно, но осторожно — при правильной настройке всей цепочки, иначе легко получить деградацию).
В высокопроизводительных средах на скоростях 25 Гбит/с и выше хорошо бы использовать RDMA для снижения задержек, но чаще используют обычный TCP (с протоколом msgr2), так как RDMA сильно усложняет сеть, а потому он чаще встречается в high-end конфигурациях.
Ремарка! RDMA — технология, которая позволяет узлам в сети напрямую получать доступ к памяти друг друга без участия операционной системы и CPU. Это снижает задержки, уменьшает нагрузку на CPU и повышает производительность за счёт минимизации копирования данных и переключения контекста. RDMA использует протокол RoCE (RDMA over Converged Ethernet), который работает поверх Ethernet. В отличие от традиционного TCP/IP, RoCEv2 позволяет маршрутизировать пакеты, а не ограничиваться одним широковещательным доменом (broadcast domain).
И ещё — если используете NVMe и плотные OSD-ноды, даже 10–25 Гбит/с может не хватать, а потому лучше брать с запасом, если планируете рост.
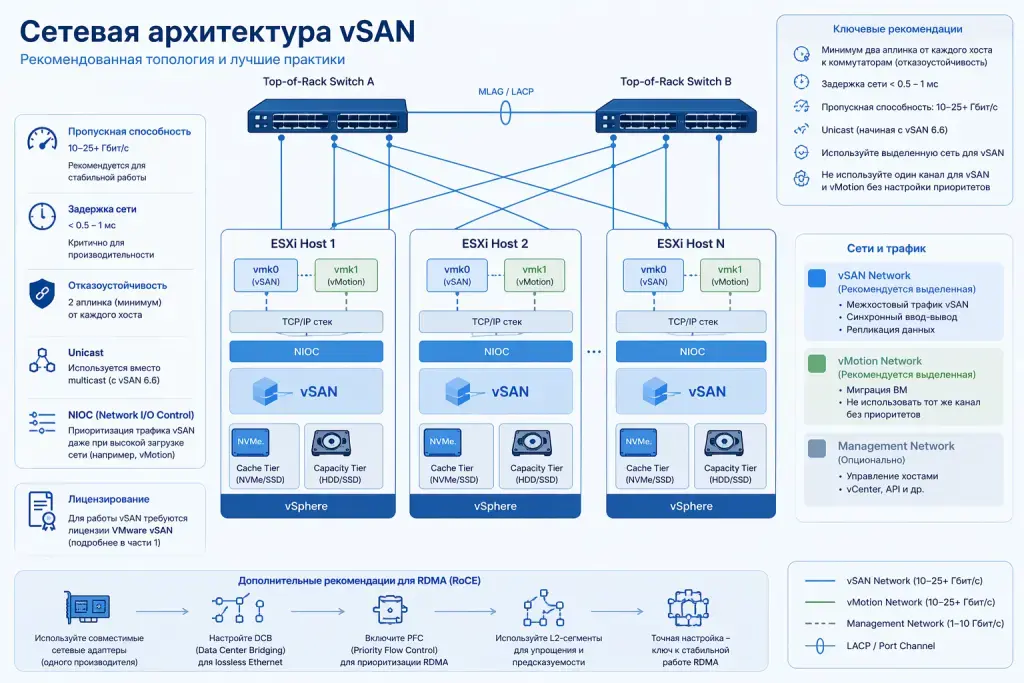
vSAN тоже лучше работает в 10–25+ Гбит/c среде, так как задержки сети влияют на производительность ввода-вывода между хостами. На меньшей скорости может даже отказаться работать вовсе, спасибо их заботе. VMware рекомендует использовать минимум два аплинка от каждого сервера к коммутаторам для отказоустойчивости — если один кабель или порт выйдет из строя, трафик vSAN пойдет по второму. Задержки в сети должны быть очень низкими (обычно <05-1 мс), иначе производительность будет снижаться. Начиная с версии vSAN 6.6 (то есть во всех актуальных кластерах), используется unicast вместо multicast, что упрощает настройку коммутаторов и развёртывание vSAN с точки зрения сетевых требований.
Для приоритизации трафика внутри VMware применяется механизм NIOC (Network I/O Control), который следит, чтобы vSAN всегда получал достаточно пропускной способности, даже когда сеть загружена другими операциями (например, миграцией vMotion). vSAN может работать в обычных TCP/IP сетях с VLAN (виртуальных локальных сетях), не требуя выделенного оборудования, но я бы всё же рекомендовал выделить отдельную сеть для максимальной производительности. И не стоит использовать один и тот же канал для vSAN и vMotion без настройки приоритетов, чтобы не плодить узкие места в сети.
Что ещё важно: RDMA в vSAN требует точной настройки; чаще всего используют L2-сегменты для упрощения и предсказуемости. Нужно правильно настроить коммутаторы и виртуальные сетевые адаптеры. Важно включить DCB (Data Center Bridging) для lossless Ethernet (без потерь) и настроить PFC (Priority Flow Control) для приоритезации трафика RDMA. Не используйте в одном кластере сетевые адаптеры разных производителей. Ну а поскольку всё это развёртывается как кластер VMware, то вам понадобятся лицензии vSAN (про это читайте в первой части статьи).
Ceph vs vSAN: сравнение сетевой инфраструктуры в таблице
Критерий
Ceph
VMware vSAN
Минимальная сеть
≥10 Гбит/с
≥1 Гбит/с (теоретически), практически от 10 Гбит/с
Рекомендуемая сеть (прод)
10–25+ Гбит/с, при плотных узлах — 25–100 Гбит/с
10–25+ Гбит/с, для современных конфигураций (ESA) — 25 Гбит/с+
Чувствительность к сети
Очень высокая (репликация, recovery, backfill)
Высокая (задержки влияют на I/O)
Поведение при деградации
Упор в пропускную способность сети
Упор в задержки (latency)
Разделение трафика
Public Network + опционально Cluster Network
VLAN / vmkernel-интерфейсы
Обязательность отдельной сети
Нет (рекомендуется)
Нет (рекомендуется или QoS)
Отказоустойчивость сети
Bonding (LACP / active-active)
Минимум 2 аплинка (NIC teaming)
RDMA (RoCE)
Поддерживается, но чаще применяется в high-end
Поддерживается, сложен в настройке, чаще применяется в high-end
Требования к задержкам
Важны, но вторичны к пропускной способности
Критичны (низкие задержки обязательны)
Тип сетевого трафика
Репликация, recovery, клиентский I/O
Синхронный межхостовый I/O
Приоритезация трафика
Через Linux / сеть
NIOC (встроенный механизм)
Переподписка
Критично избегать
Критично избегать
Подытожу про Ceph и vSAN. Вам понадобится хороший сетевик и оборудование: в нормальном состоянии оба решения могут работать стабильно даже в умеренной сети, но при деградации (выход дисков, ребилд) именно сеть будет определять время восстановления и стабильность прода. Для обеих SDS критически важно отсутствие переподписки (oversubscription) на коммутаторах, а при росте нагрузок и в high-end конфигах имеет смысл использовать RDMA.
Масштабирование и рост Ceph и vSAN
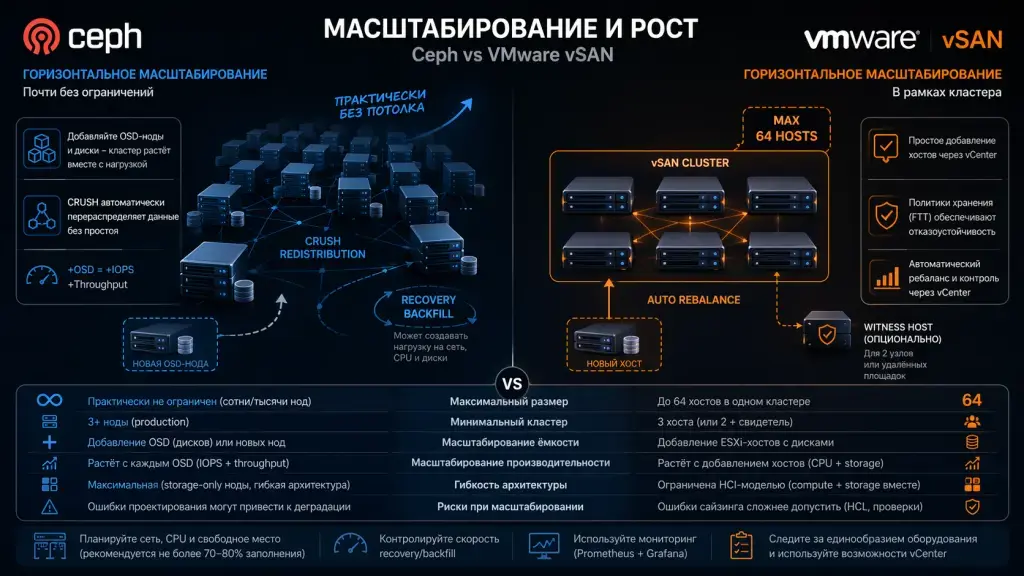
Масштабируемость Ceph: с программной точки зрения кластер можно масштабировать околобесконечно — у крупных провайдеров и гиперскейлеров в проде работают кластеры из сотен и тысяч узлов.
Просто добавляете воды новые серверы с OSD, а CRUSH автоматически перераспределит реплики и новые объекты на новые OSD. Важно заранее спланировать домены отказа (стойки, зонирование), и если не ограничить скорость восстановления и балансировки, то фоновые операции начнут съедать производительность боевых сервисов. Обычно кластеры растят линейно — +N OSD к существующему пулу, но можно и вглубь, выделяя ноды только для хранения.
Ремарка! Я всегда перед расширением снижаю параметры параллельного восстановления. Да, процесс идёт дольше, но зато пользователи не замечают просадки по задержкам.
Важно прогнозировать рост и документировать добавление узлов, чтобы избежать узких мест и дисбаланса. При выходе из строя узла нагрузка перераспределяется по остальным – а значит резерв памяти и CPU на OSD нужно закладывать с запасом. При больших кластерах (например, 50-100 нод) нужно внедрять системы мониторинга (Prometheus/Grafana), чтобы отслеживать нагрузку и планировать расширение.
Ceph отлично масштабируется по пропускной способности — добавление OSD с независимыми дисками в одном сервере (RAID тут не используется, Ceph любит JBOD в нодах) увеличивает совокупный IOPS и пропускную способность. Однако масштабирование завязано и на CPU (erasure coding, шифрование, сжатие) и с сетью (коммутаторы тоже нужно апгрейдить). Хотя большинство ограничений обычно связаны не с самой системой, а с сетью и — самое важное — опытом команды.
Масштабируемость в vSAN ограничена размером кластера vSphere. Максимальный — 64 хоста (после этого нужно архитектурно шардировать решение), а минимальный — 3 (или 2 плюс узел-свидетель для небольших площадок). Если нужно больше хостов в кластере, то либо строят ещё один, либо переходят на решение VMware Cloud Foundation, при этом такое масштабирование — это всегда дополнительное планирование, нельзя просто развернуть десятки узлов без внимания к сети и общей нагрузке.
vSAN масштабируется за счёт новых ESXi-хостов с накопителями, а каждый новый узел сразу начинает контрибьютить хранилище и CPU для ВМ, при этом данные автоматически ребалансируются (политики хранятся в vCenter). Производительность отдельных ВМ остаётся предсказуемой благодаря QoS (Quality of Service) — набора решений для оптимизации сети через приоритезацию трафика. Админам нужно следить за единообразием конфигурации оборудования и сети при масштабировании, так как VMware настоятельно рекомендует сохранять одинаковый профиль (качественные линейки HDD/SSD из HCL) для предсказуемой работы. Если работаете всего на двух узлах vSAN, то нужен выделенный хост-свидетель для кворума (про кворумы читайте в первой части статьи).
Ceph vs vSAN: масштабирование и рост кластера
Критерий
Ceph
VMware vSAN
Модель масштабирования
Горизонтальная (scale-out) почти без ограничений
Горизонтальная (scale-out) в рамках кластера
Максимальный размер кластера
Практически не ограничен (сотни/тысячи нод)
До 64 хостов в одном кластере
Минимальный кластер
3+ ноды (production)
3 хоста (или 2 + свидетель)
Масштабирование ёмкости
Добавление OSD (дисков) или новых нод
Добавление ESXi-хостов с дисками
Масштабирование производительности
Растёт с каждым OSD (IOPS + throughput)
Растёт с добавлением хостов (CPU + storage)
Автоматическое перераспределение данных
Да (CRUSH)
Да (vSAN storage policies + rebalance)
Поведение при расширении
Агрессивный rebalance/backfill (нагружает систему)
Автоматический ребаланс с контролем через политики
Контроль нагрузки при масштабировании
Ручной (throttle recovery/backfill)
Частично автоматизирован (через vSphere/vSAN)
Зависимость от сети при росте
Очень высокая (сеть — основной ограничитель)
Высокая (latency + resync)
Зависимость от CPU при росте
Высокая (EC, compression, recovery)
Умеренная (зависит от нагрузки ВМ)
Гибкость архитектуры
Максимальная (можно выделять storage-only ноды)
Ограничена HCI-моделью (compute + storage вместе)
Дезагрегированное хранилище
Нативно (архитектура изначально такая)
Через vSAN Max (отдельные storage-кластеры) (VMware Blogs)
Требования к однородности
Низкие (можно смешивать железо)
Высокие (желательно одинаковые конфигурации)
Риски при масштабировании
Ошибки проектирования приводят к деградации
Ошибки сайзинга сложнее допустить из-за HCL, который не даст развернуть систему на неподдерживаемом железе
Ограничение масштабирования
Практически нет (упирается в сеть и экспертизу)
Жёсткий лимит кластера + архитектурные границы
Подытожу про масштабирование Ceph и vSAN. Ceph масштабируется практически без ограничений — добавляете узлы или OSD, и кластер продолжает расти вместе с нагрузкой. Но вместе с этим растёт и сложность: сеть, CPU и фоновые операции (rebalance, recovery) — крайне важны, без контроля может падать производительность.
vSAN масштабируется легче, но в рамках жёстких границ кластера — до 64 хостов, после чего приходится строить новую архитектуру или сегментировать инфраструктуру. Зато добавление узлов проходит проще: система сама перераспределяет данные и сохраняет стабильное поведение под нагрузкой.
Отказоустойчивость и защита данных Ceph и vSAN
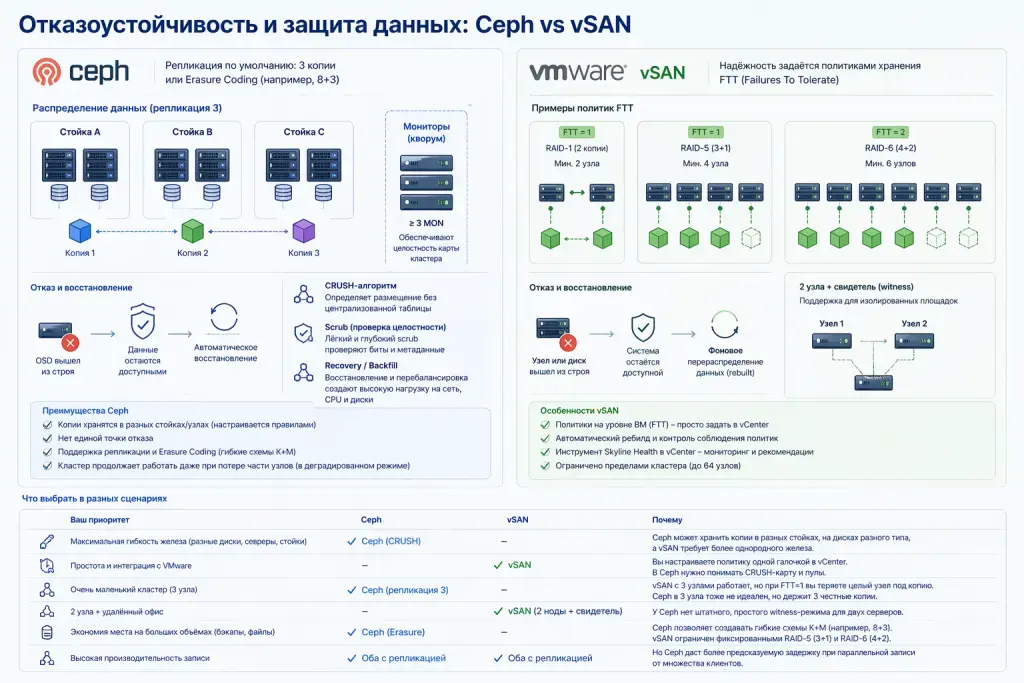
В Ceph данные по умолчанию реплицируются в кластере в 3 копии (или в кодированных фрагментах при Erasure Coding). Если OSD выходит из строя, другие ноды хранят реплики и автоматически восстанавливают заданный уровень копий. Мониторы на 3+ нодах реализуют кворум и целостность карты кластера.
Админ может задать правила размещения (например, реплика в 3 разных стойках), а алгоритм CRUSH определяет, где физически лежат данные — без централизованной таблицы. За счёт этого Ceph избегает единой точки отказа и автоматически перераспределяет данные при любом изменении кластера: добавление узлов, выход из строя накопителей или целых нод. У этого подхода есть минус — если неправильно задать домены отказа (например, не разнести реплики по стойкам), кластер на бумаге будет отказоустойчивым, а на деле сильно уязвимым.
Ceph регулярно выполняет scrub (процесс фоновой проверки консистентности данных в группах размещения, бывает лёгкий и глубокий scrub) — в ходе этой процедуры проверяется целостность битов на накопителях OSD и при необходимости восстанавливается путём сравнения данных между репликами.
Ceph продолжает работать даже при потере части кластера, но деградирует. В этот момент начинается активное восстановление данных (recovery, backfill), что создаёт дополнительную нагрузку на сеть, CPU и накопители. И крайне желательно, чтобы ресурсов в это время хватало.
В vSAN надёжность задаётся через политики хранения — FTT (Failures To Tolerate, количество допустимых отказов) определяет число копий или паритетных блоков.
Примеры: FTT=1 в двух копиях (RAID-1), FTT=1 в RAID-5 (нужно ≥4 узлов), FTT=2 в RAID-6 (≥6 узлов). Система сама следит за соблюдением политики. При выходе узла или диска vSAN в фоновом режиме перераспределяет блоки на свободные диски внутри кластера. vSAN поддерживает 2-узловой режим с центральным свидетелем, размещённым на другой площадке, для изолированных от глобальной сети локаций.
В целом отказоустойчивость высокая, но политика настраивается на уровне виртуальных машин и дисков, ну и ограничена пределами кластера. vSAN имеет панель Skyline Health в vCenter — это инструмент для мониторинга состояния кластеров, который позволяет оценивать работоспособность кластера, выявлять проблемы и тренды (изменение за заданный период) и предоставлять информацию для их устранения и запуска ребилда при сбоях.
В каких сценариях отказоустойчивости лучше Ceph, а в каких vSAN:
Ваш приоритет
Что выбрать
Почему
Максимальная гибкость железа (разные диски, серверы, стойки)
Ceph (CRUSH)
Ceph может хранить копии в разных стойках, на дисках разного типа, а vSAN требует более однородного железа.
Простота и интеграция с VMware
vSAN
Вы настраиваете политику одной галочкой в vCenter. В Ceph нужно понимать CRUSH-карту и пулы.
Очень маленький кластер (3 узла)
Ceph (репликация 3)
vSAN с 3 узлами работает, но при FTT=1 вы теряете целый узел под копию. Ceph в 3 узла тоже не идеален, но держит 3 честные копии.
2 узла + удалённый офис
vSAN (2 ноды + свидетель)
У Ceph нет штатного, простого witness-режима для двух серверов.
Экономия места на больших объёмах (бэкапы, файлы)
Ceph (Erasure)
Ceph позволяет создавать гибкие схемы K*+M* (например, 8+3). vSAN ограничен фиксированными RAID-5 (3+1) и RAID-6 (4+2).
Высокая производительность записи
Оба с репликацией
Но Ceph даст более предсказуемую задержку при параллельной записи от множества клиентов.
K (Data chunks) — количество исходных кусков данных, на которые разрезан ваш файл.
M (Parity chunks) — количество дополнительных (паритетных) кусков, которые вычисляются на основе исходных. Именно они обеспечивают отказоустойчивость.
K+M — обозначает схему распределения данных, где объект делится на K частей (данные) и M частей (кодирующий код для восстановления). Схема 8+3 означает, что объект будет разделён на 8 частей данных и 3 части кодирующего кода
Администрирование, мониторинг и обслуживание Ceph и vSAN

Ceph — это Open Source система, которая строится из обычных серверов и накопителей. Администратор Ceph работает через интерфейс командной строки (CLI) ceph, утилиты cephadm (современный способ развёртывания и управления) или через REST API. Все настройки кластера, правила размещения (CRUSH map), создание пулов, включение Erasure Coding, настройка scrub’ов и балансировщиков — всё это выполняется через команды или редактирование конфигурационных файлов.
Графические интерфейсы (например, встроенная панель Ceph Dashboard или сторонние инструменты, вроде Proxmox) лишь визуализируют те же команды — это надстройка над CLI, а сложные сценарии, работа с CRUSH-правилами и т.п. всё равно выполняются вручную.
Мониторинг Ceph построен на его собственной внутренней телеметрии: команда ceph status показывает здоровье кластера (HEALTH_OK / HEALTH_WARN / HEALTH_ERR), а детальные метрики (задержки, использование дисков, скорость восстановления, очередь операций) доступны через модуль Prometheus exporter, который затем визуализируется в Grafana.
Ceph умеет отправлять уведомления о проблемах через e-mail, также поддерживаются webhook-и в условный Slack или другие системы. Обслуживание Ceph — это постоянный, но фоновый процесс: кластер сам следит за целостностью данных через регулярные scrub’ы (лёгкие — проверяют метаданные, глубокие — сравнивают содержимое реплик побитово), сам запускает recovery и backfill при добавлении или потере дисков/узлов.
Задача администратора — не запускать эти процессы вручную, а следить за тем, чтобы в кластере всегда было достаточно свободного места (рекомендуется не более 70–80% заполнения) и ресурсов (сеть, CPU), иначе восстановление может сильно замедлиться или даже остановиться.
Ещё одна задача — правильно настроить домены отказа, так как Ceph ничего не знает о вашем ЦОДе. Он видит только OSD с номерами, и если ему не объяснить, что диски 1, 2 и 3 физически стоят в одной стойке, а диски 4, 5, 6 — в другой, он будет считать, что все они равноправны, и может разместить три реплики одного объекта на трёх дисках из одной стойки. Вроде правило трёх копий выполнено, кластер показывает HEALTH_OK, но если эта стойка потеряет питание или в ней упадёт ToR-коммутатор — вы потеряете все три реплики одновременно.
Обновление Ceph — это тоже командная операция: cephadm upgrade последовательно обновляет демоны на всех узлах, причём кластер продолжает работать.
VMware vSAN — это интегрированный компонент vSphere, и его администрирование полностью вписано в экосистему VMware.
Администратор работает через графический интерфейс vSphere Client (веб-интерфейс vCenter). Все операции — создание кластера vSAN, включение шифрования, настройка политик FTT, добавление узлов, замена дисков, проверка обновлений — выполняются через галочки, выпадающие списки и мастера. Командная строка (ESXCLI, PowerCLI) существует, но она нужна лишь для редких нештатных ситуаций или автоматизации.
Мониторинг vSAN также встроен в vCenter и называется Skyline Health (ранее — vSAN Health Service). Это не просто датчики, а набор заранее написанных проверок (около 50–70 штук), которые оценивают конфигурацию кластера, драйверы, прошивки, сетевое взаимодействие, состояние дисков, соответствие политик и многое другое. Результат представляется в виде обобщённого Cluster Health Score — числа от 0 до 100, где 100 — идеальное состояние. При любой проблеме интерфейс подсвечивает её красным, даёт описание на русском или английском языке и часто предлагает кнопку «Исправить» или ссылку на базу знаний VMware. Детальные метрики по задержкам, IOPS, использованию кэша и уровням хранения доступны на вкладках мониторинга vSAN.
Обслуживание vSAN максимально автоматизировано: система сама отслеживает выход дисков или узлов и запускает ребилд в соответствии с политикой FTT. Администратору нужно лишь следить за Health Score и при необходимости заменять вышедшие из строя диски (vSAN предложит заменить их через интерфейс, затем автоматически перестроит данные на новом диске). Плановое обслуживание (например, вывод узла из кластера для замены памяти) выполняется через режим обслуживания (Maintenance Mode) с выбором стратегии переноса данных: «перенести всё», «перенести только часть» или «стереть данные». Обновление компонентов vSAN происходит через стандартный механизм обновления vSphere Lifecycle Manager (vLCM) и может выполняться одним кликом для всего кластера с проверкой совместимости драйверов и прошивок.
Ниже — сводная таблица для быстрого сравнения:
Аспект
Ceph
VMware vSAN
Основной интерфейс управления
Командная строка (ceph, cephadm), REST API, веб-панель (Ceph Dashboard)
Графический интерфейс vSphere Client (встроен в vCenter)
Требуемая квалификация администратора
Высокая (понимание CRUSH, пулов, доменов отказа, CLI)
Средняя (опыт работы с vSphere, понимание политик FTT)
Мониторинг здоровья
Команда ceph status, метрики Prometheus + Grafana, проверка scrub'ов
Skyline Health (встроенные проверки), Cluster Health Score (0–100)
Уведомления о проблемах
Настраиваемые (e-mail, Slack, Webhook) через модуль alerting
Через vCenter (алерты, e-mail, SNMP)
Плановое обслуживание узла
ceph osd set noout, вывод узла, остановка демонов, режим обслуживания
Включение Maintenance Mode в vCenter (три варианта переноса данных)
Замена диска
Автоматически обнаруживается, администратор запускает перебалансировку, либо добавляет новый OSD вручную
Интерфейс vSAN предложит заменить диск, после замены — автоматический ребилд
Обновление системы
cephadm upgrade (последовательное обновление демонов на узлах)
vSphere Lifecycle Manager (vLCM) — обновление всего кластера одной политикой
Глубина диагностики
Очень высокая (можно посмотреть состояние каждого PG, каждого OSD, логов демонов)
Высокая, но в рамках интерфейса vCenter (встроенные проверки, performance charts, логи ESXi)
Самостоятельность системы
Сама делает scrub, recovery, backfill, но требует контроля свободного места и ресурсов
Почти полностью автоматизирована: ребилд, балансировка, Health Score подсказывает проблемы
Сложность для новичка
Высокая (порог входа)
Низкая (если знаком с vSphere)
Ceph требует инженера, который понимает внутреннее устройство распределённых систем, умеет работать с командной строкой и готов вручную настраивать правила и следить за метриками через Grafana. vSAN же спроектирован для обычного администратора VMware, который привык к графическим интерфейсам и хочет получать готовый диагноз в формате «всё плохо — сделай то-то».
Если у вас уже есть опытный Linux-инженер — Ceph даст максимум гибкости и прозрачности. Если же вы работаете в среде VMware — vSAN с его Skyline Health и автоматическим обслуживанием будет комфортнее.
Заключение
Ceph и vSAN — это зрелые SDS-решения, но подходят они для разных задач. Если ваша инфраструктура уже построена на VMware и вам нужен контракт с поддержкой, то выбирайте vSAN — это коробочное HCI-решение для экосистемы VMware, которое предлагает предсказуемую производительность и простоту управления из коробки (через vCenter), но привязывает к вендору и требует серьёзных затрат на лицензирование.
Если же нужна независимость от вендора, работа с разными протоколами и экономия на лицензиях в больших или бюджетно-чувствительных проектах, то выбирайте Ceph — это открытая масштабируемая платформа с максимальной гибкостью (работает с любым железом, поддерживает блок, объекты и файлы), она выигрывает по стоимости лицензий (CAPEX), но требует высокой квалификации персонала и ручного тюнинга (выше OPEX).
Спасибо, что дочитали этот лонгрид! В Сервер Молл вы можете выбрать серверы, СХД, коммутаторы и другое серверное оборудование для Ceph и vSAN под ваш бюджет. У нас бесплатная доставка по всей России, гарантия до 5 лет с выездом инженера, неограниченные консультации с персональным менеджером и КП за час. Пишите в чат на сайте или звоните!
А в комментариях ниже оставляйте отзывы или вопросы по статье — я всё читаю и на всё отвечаю :)




