

I. Введение
Привет, это очередная статья из цикла “Сервер под задачу” :)
Здесь вы найдёте всё, что нужно знать про VMWare vSphere — ведущую платформу для виртуализации.
VMWare — это американский IT-гигант, разработчик софта для виртуализации. И да, компания благополучно ушла с рынка РФ в 2022 году. Но их продукты от этого хуже не стали, а регулярные запросы от заказчиков подтверждают это. Спойлер: пользоваться можно даже после ухода компании.
Ремарка! К сожалению, после поглощения VMware корпорацией Broadcom вендор сильно сменил курс — теперь основной фокус VMware направлен на крупных корпоративных клиентов, а малый и средний бизнес оставили за бортом. Broadcom даже убрала бесплатную версию ESXi, потом вернула — но в урезанном виде, больше для тестов и лабораторных целей, чем для реальной работы.
Чтобы ответить на частые вопросы (а их много), я решил сделать большой, длинный и необрезанный лонгрид — перед вами самая актуальная информация по VMware vSphere на 2026 год.
И да, разобрать нужно over 100500 вопросов, поэтому прорабатывать будем тщательно, но без нудятины и излишних подробностей. Только самое полезное, но если у вас появятся уточняющие вопросы, то задавайте их в чате, по телефону или пишите на почту СЕРВЕР МОЛЛ. Мы общительные :)
Итак, статья подойдёт начинающим технарям, эникеям и админам со стажем (освежить память всегда полезно). Людям, далеким от технологий, тоже пойдёт, но придётся немного по ссылкам попрыгать (найдёте их в статье).
Что ж, заваривайте термос, откидывайте спинку кресла — расслабляйтесь и получайте удовольствие :)
VMware серверы


 5 лет гарантии
5 лет гарантии Бесплатная доставка
Бесплатная доставка
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставка
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставка
Что такое VMWare vSphere

Сфера Пузо — фотошоп, ни один хищник не пострадал от переедания.
VMWare vSphere (читается “висфер”) — это ведущая платформа для создания и управления виртуальными машинами. По сути это набор профессионального программного обеспечения (ПО) от компании VMWare. А виртуальные машины (ВМ) — это что-то вроде программной версии физических серверов.
Для использования нужна платная лицензия или ловкость рук админа, если вы понимаете, о чем я :)

Пиратство мы осуждаем! Честно-честно!
У vSphere есть 2 основные составляющие:
ESXi (от англ. "Elastic Sky X Integrated") — гипервизор 1 типа, то есть установленный сразу на сервер/хост/голое железо (Bare-Metal), без прослойки в виде серверной ОС. Гипервизор — упрощенно — это программа, создающая и управляющая ВМ, которые могут работать и храниться на различных физических серверах и системах хранения данных (СХД). Кстати, у ESXi есть и бесплатная лицензия с урезанным функционалом (нет поддержки vCenter Server и его составляющих, нет Active Directory и обновлений через vSphere Update Manager, недоступен API для резервного копирования).
vCenter Server — служба (приложение) для централизованного управления виртуализированной инфраструктурой, включая хосты ESXi и все запущенные на них ВМ. Раньше vCenter Server можно было установить на Windows (+ база данных), но в версиях vSphere 7.0 и новее эта опция не поддерживается.
Сейчас при развёртывании vCenter Server админы используют vCSA (vCenter Server Appliance) — это предварительно настроенная виртуальная машина на основе Linux, развернутая на хостах ESXi. Очень удобная штука, так как вы получаете комплексное решение со всем необходимым для работы vCenter Server: Photon OS 3.0, The vSphere authentication services, VMware vSphere Lifecycle Manager Extension, VMware vCenter Lifecycle Manager и база данных PostgreSQL

WARNING! Перечислю самые важные изменения по версиям VMware ESXi и срокам поддержки версий. На этом сайте вы всегда можете свериться с актуальной информацией.
Поддержку линейки ESXi 7.x продлили до 2 октября 2025 года — это дата окончания общей поддержки (EoGS, End of General Support) для VMware vSphere 7.x и всей связанной продукции (vSAN и vCenter). После этой даты продукт больше не получает исправления, обновления безопасности и официальную поддержку.
По продукту VMware vCenter Server, работающему на Windows: с версии 6.7/7.0 классическая Windows-установка больше не поддерживается — официально рекомендуют использовать виртуальную appliance-версию (vCenter Server Appliance (VCSA)) на базе Photon OS.
Версия ESXi 8.0: релиз Update 3d (Build 24585383) вышел 4 марта 2025 года. Далее вышла версия Update 3e (Build 24674464) — релиз 10 апреля 2025 года.
VMware vSphere 8.x во многих инфраструктурах используют как основную платформу. Для ESXi 8.0 конец общей поддержки запланирован на ~11 октября 2027, а конец технического сопровождения (End of Technical Guidance) — на ~11 октября 2029.
Но компания уже выпустила новую версию ESXi 9.0: релиз GA (General Availability) — Build 24755229 — вышел 17 июня 2025 года. Затем 15 июля 2025 года выпустили патч 9.0.0.0100 (Build 24813472), а 29 сентября 25 года вышла ESXi 9.0.1.0.
При этом базовая линейка vSphere Standard/Enterprise Plus остаётся отдельно в версии 8.x. Это пока переходный продукт для самых современных инфраструктур, так как некоторые старое железо и компоненты не будут поддерживаться в 9 версии.
Что даёт виртуализация в целом и vSphere в частности?
Дальше в статье будут разъяснения, так что не пугайтесь, если не поняли, а пока отвечу коротко — вы сможете запускать несколько независимых друг от друга операционных систем (ОС) и приложений на одном физическом сервере (или нескольких, включая СХД), эффективно распределять и разделять ресурсы, гибко управлять ими (миграция виртуальных машин, балансировка нагрузки и высокая доступность). И всё это добро объединено в единую платформу (сферу) создания, управления и мониторинга — то есть решение комплексное.
Сфера в названии vSphere — это что-то вроде отсылки к концепции полной виртуализации, которая позволяет абстрагировать виртуализированную инфраструктуру от физического оборудования. Но, возможно, маркетологи VMWare закладывали и другие смыслы в название :)
Значение оборудования для VMWare vSphere

Здесь я вас не удивлю: для хорошей производительности, надёжности и масштабируемости (потенциал роста нагрузок без замены всего сервера) vSphere нужно правильно подбирать оборудование.
Сходу WARNING!
Развёртывание vSphere — процесс непростой. Тут понадобится архиадмин. Опытный юзер Excel — не вариант. Если вы не из тех, кто любит жизнь, то придётся изучить дополнительную информацию и провести некоторое кучу времени на настройке и тестировании. Благо у VMware много длинных FAQ’ов, обширной документации и руководств — каждому воздастся по делам его, было бы желание :)
Но не так страшен админ, как его пингуют. Есть в vSphere и вещи, облегчающие страдания. Например, админы поопытнее, понимающие в архитектуре vSphere, используют функционал vSphere Auto Deploy, чтобы автоматически разворачивать хосты ESXi в сети. То есть подключенный сервер автоматически настроится и добавится в управляемую IT-инфраструктуру — вам только пару проводов воткнуть. На сайте VMWare, разумеется, есть инструкция — велкомен.
Как сказал Тони Старк Артур Кларк: "Любая достаточно продвинутая технология неотличима от магии".

По конкретным комплектующим я пройдусь дальше в статье, дам конкретные советы по выбору, но перед этим нужно учесть кое-что чертовски важное:
Сначала определяем задачу и требования, а потом покупаем оборудование.
Вы же не будете на Toyota Supra возить мешки навоза на дачу, так? Для этого есть грузовики или пикапы. С vSphere можно решать огромный пул задач, а под каждую задачу есть своё оборудование. Серверное, конечно же. Про ПК я говорить не буду. Почему? В двух словах не объяснить, но ответ есть в другой моей статье.
А теперь перейдём к задачам и требованиям.
II. Определение задач и требований vSphere

Для каких задач подходит vSphere:
Перечислю основные сценарии использования vSphere, чаще всего их комбинируют — всё зависит от ваших требований и хотелок.
Консолидация ресурсов через vSphere

Бывает, что компания растёт, серверов становится больше, но каждый загружен лишь частично — на 30-50%, когда могут в теории на 80% (больше не стоит). То есть вы купили серверы, но не используете весь их потенциал — это называют простоем мощностей.
С помощью vSphere вы можете создать ВМ, которые будут выполнять все те же задачи, но с важным преимуществом — у вас появится общий пул ресурсов (процессор, память, хранилище), из которого будут выделяться вычислительные мощности на нужды каждой виртуалки.
Нагрузка на почтовый сервер минимальна в сезон низкой нагрузки? vSphere выделит нужный ресурс, а остальное распределит между другими ВМ, которым ресурсы нужнее. Всё это может происходить динамически — без вашего прямого участия.
Благодаря консолидации ресурсов можно уменьшить количество физических серверов и нивелировать простой мощностей. Или оставить все серверы, но решать больше задач с их помощью. Такие дела.
Динамическое масштабирование в vSphere

Выше я описал сценарий, когда мощности простаивают, но часто нагрузка на серверы изменчива, особенно в сезонных бизнесах. Бывает, что физический сервер в пиковые нагрузки “не вывозит”, и вылезают проблемы с производительностью — может дойти до отказа, как при DDoS-атаках.
Нагрузка на почтовый сервер возросла в предновогоднюю распродажу? Не проблема. Если ресурсов в кластере достаточно, то виртуальная инфраструктура выделит их почтовой виртуалке.
Итак, vSphere позволяет динамически масштабировать вычислительные ресурсы. Это означает, что вы можете увеличивать или уменьшать вычислительные мощности в реальном времени — под ваши потребности прямо сейчас. Гибко и экономит ресурсы. Но учтите, что это возможность, а не классический вариант инсталляции. Чтобы динамическое масштабирование работало, нужно и настраивать долго, и дополнительное физическое оборудование покупать.
Безопасное тестирование и развертывание приложений в vSphere

С помощью VMWare vSphere вы сможете создавать изолированные виртуальные среды для разработки, тестирования и развертывания приложений. Прежде чем выкладывать изменения в прод, можно протестировать всё на аналогичном тестовом пространстве, попробовать новый софт или установить обновления, если лень изучать патчноут.
Плюсов очень много: сокращение рисков, ускорение разработки, выявление конфликтов между версиями и приложениями. Быстро и безопасно :)
Бесперебойная работа и восстановление после сбоев в vSphere

Тестовые пространства от всех бед не спасут — проблемы бывают и на аппаратном уровне: сгоревший БП, жёсткий диск или другой компонент могут остановить работу сервера — это ночной кошмар любого админа.
Можно, конечно, дублировать комплектующие (второй БП, RAID-массив), но для полноценной отказоустойчивости и высокой доступности (High Availability) вашей IT-инфраструктуры придётся пользоваться софтом.
Например, vSphere High Availability (HA). Если сервер откажет, то виртуальные машины автоматически перезапускаются на других работающих серверах. Это же можно реализовать на распределённом (Stretched) кластере серверов — при сбое всего датацентра ВМ запустятся в резервном датацентре. Такой подход называют георезервированием, он нужен, чтобы пожар, потоп, беспилотник или другой локальный апокалипсис не остановил надолго работу сервисов.
В дополнение к vSphere HA есть функция vSphere vMotion, которая позволяет перемещать работающие ВМ между серверами без остановки работы — разве что минимальные проседания производительности и задержки пакетов возможны.
Или другой пример — vSphere Replication. Относительно недорогой в реализации, но мгновенного восстановления не даёт. Это механизм репликации на уровне хоста, который создаёт резервные копии виртуальных машин и копирует их данные на удаленные серверы или хранилища. Так вы сможете защитить информацию и восстановить работу в кратчайшие сроки после критического сбоя. Репликацию данных можно настроить на на разных уровнях: ВМ, диск или файл. И всё это с выбранной периодичностью, автоматически и по расписанию — каждые несколько минут, часов или дней.
Также есть функционал Fault Tolerance (FT). Если не углубляться, то это полный дубликат основной ВМ, который работает параллельно с ней на другом серверном оборудовании; при сбое управление и работа сразу переходят на копию — без простоев и потерь данных. Фича довольно специфична, есть ограничения по ресурсам виртуальной машины, повышенные требования к аппаратному обеспечению — но если другими средствами реализовать отказоустойчивую работу архикритичного сервиса не представляется возможным, то это станет этаким запасным парашютом для IT-инфраструктуры.
Централизованное управление в vSphere

У обычной IT-инфраструктуры есть недостаток — ей сложно управлять, если она разрастается, как борщевик. Каждый сервер нужно админить отдельно, а это большая нагрузка. Некоторые вендоры знают о проблеме и внедряют свои решения (некоторые даже интегрируются с vCenter для удобства), например, консоль Dell OpenManage, которая сильно упрощает управление серверами Dell в сети, но и это не панацея — что, если у вас серверы разных производителей?
В виртуальной инфраструктуре vSphere всё управление централизованно в приложении vCenter Server: мониторинг, контроль над ресурсами (процессоры, память), функциями и т.д. Администраторы смогут управлять виртуальными машинами, физическими серверами разных производителей, хранилищем данных, сетями, резервным копированием, восстановлением миграцией и многим другим в IT-инфраструктуре. И всё это в едином интерфейсе — наглядно и понятно.
На задачах пока остановимся, но знайте, что их значительно больше. Теперь поговорим об оценке вашей будущей среды под vSphere.
Оценка требований к вашей среде виртуализации под vSphere
Если всё делать по уму, то алгоритм получится сложный, но лучше я сразу расставлю все точки над 泳.
Вам придётся определить объём нагрузки на будущие ВМ и их характеристики, масштабируемость и уровень доступности всей IT-инфраструктуры (он же он же аптайм или SLA в разрезе сервиса, при расчётах важно учесть и TIER датацентра), учесть безопасность и интеграцию с существующими системами, провести оценку расходов (TCO и ROI) и квалификации персонала, нанять новых сотрудников и(или) обучить старых.
Каждый момент достоин отдельных статей.
Например.
Общая стоимость владения (TCO) и ожидаемая отдача от инвестиций (ROI) включают в себя не только стоимость лицензий на ПО, но и затраты на оборудование, поддержку, электроэнергию, процесс миграции, обучение персонала и так далее.
Поэтому я расскажу только про виртуальные машины и их характеристики для vSphere. Остальное останется на вашей совести или совести админа :)
Количество виртуальных машин и их характеристики

Количество ВМ можно определить, прикинув, какие из них будут заниматься приложениями (возьмут на себя серверные роли, например почтовый сервер), а какие выполнять задачи пользователей, разработчиков, тестировщиков и т.д. Плюс, если требуется высокая доступность уровня Fault Tolerance для критических приложений, то добавляем параллельно работающие ВМ на удалённых серверах и СХД. И, конечно же системные требования vSphere (гипервизор ESXi тоже кушать хочет, в пределах погрешности, но учесть это нужно).
Звучит сложно — и так оно и есть. Подсчётами должен заниматься опытный сисадмин. Если будут сложности, то опишите задачу менеджерам СЕРВЕР МОЛЛ — ребята бесплатно подберут серверное оборудование, чётко следуя ТЗ и бюджету, а КП отправят в течение часа.
Итак, сначала нужно подсчитать ваши базовые потребности — это сумма характеристик всех ВМ, учитывая их нагрузку (какие бизнес-процессы и приложения будут работать?).
УСЛОВНЫЙ ПРИМЕР для небольшой компании из 10 человек:
Рабочие станции: По виртуальному рабочему месту для каждого из 10 сотрудников. Каждая рабочая станция может иметь 2 ядра, 8 ГБ оперативной памяти и 200 ГБ дискового пространства — достаточно для простых офисных задач. Для более сложных нагрузок можно добавить ресурсов.
Файловый сервер: Это место, где будут храниться все корпоративные файлы и документы. Например, виртуальная машина с 2 ядрами, 8 ГБ оперативной памяти и 2 ТБ дискового пространства.
Сервер электронной почты: Если компания предпочитает хостить свою электронную почту локально, со своим доменом, то может потребоваться отдельный сервер для этого. Это может быть виртуальная машина с 2 ядрами, 8 ГБ оперативной памяти и 500 ГБ дискового пространства.
Сервер баз данных: Если у компании есть какие-либо бизнес-приложения, которые требуют базы данных, вы можете создать отдельную виртуальную машину для этого. Это может быть виртуальная машина с 4 ядрами, 16 ГБ оперативной памяти и 1 ТБ дискового пространства.
Далее нужно сложить вычислительные ресурсы, необходимые для одновременной работы каждой ВМ: процессор (ядра, потоки и их производительность), память (объем и скорость), хранилище (объем, скорость, резервное копирование, RAID, тип хранилища), сеть (пропускная способность, интерфейсы), безопасность (фаерволы, контроль доступа, шифрование). В моём упрощенном примере базовые потребности следующие: 28 ядер, 112 ГБ оперативной памяти и 5.5 ТБ постоянной.
Не забываем про масштабируемость. Если трафик и нагрузка на ВМ растут, например, на 20% год к году, а вы меняете/обновляете серверы раз в 3 года, то ваши базовые потребности вырастут на 1,728 (1.2 * 1.2 * 1.2) за это время.
И сверху накидываем еще 20% про запас, чтобы сервер не работал в третий год на последнем издыхании, а имел хоть какой-то запас “прочности”.
Получим формулу.
Базовые потребности * 1,728 (масштабирование на 3 года) * 1.2 (запас) = целевая производительность IT-инфраструктуры.
В моём примере:
58 ядер;
224 ГБ или более ОЗУ (здесь округление, по формуле получим 232 ГБ);
11,4 ТБ полезного дискового пространства (заходите в калькулятор и считайте, сколько дисков нужно под ваш вариант RAID-массива).
А ещё нужно посчитать сеть и ресурсы под безопасность. Но сам принцип подсчёта теперь должен быть понятен из упрощённого примера.
III. Совместимость сервера с VMWare vSphere

Итак, мы прикинули (или наши менджеры вам помогли), сколько ВМ и какая производительность серверного оборудования под них нужны, поэтому самое время выбрать вендора и конкретные модели, которые точно будут совместимы с VMWare vSphere.
Список совместимого оборудования на официальном сайте VMWare.
Первое, что стоит сделать, это свериться с рекомендациями VMWare.
WARNING!
Изучить рекомендации VMWare по совместимости оборудования (Hardware Compatibility List, HCL) — супер-важно, даже критично, начиная с 7 версии vSphere.
Раньше VMWare использовала образ на основе Linux с его драйверами, но в vSphere 7 (и старше) уже околосамостоятельная ОС, со своими драйверами — поэтому список поддерживаемого оборудования существенно сузился. Дело доходит до прошивок жёстких дисков и конкретных сетевых адаптеров. А для vSAN это ещё важнее — иначе стабильная работа (или вообще работа) не гарантируется. В vSphere 8 список ещё уже — особенно по сетевым адаптерам и контроллерам хранилищ. Часть старых NIC и SAS-контроллеров удалена из поддержки с U2.
VMWare не пытается усложнить жизнь строгими HCL, скорее наоборот — всеми силами не даёт аминам прострелить себе ногу некорректной конфигурацией и неправильным подбором железа.
Итак, ссылка на новый Hardware Compatibility List (после поглощения Broadcom) — https://compatibilityguide.broadcom.com. Там вы сможете проверить своё старое оборудование или подобрать что-то новое.

Минимальные системные требования VMWare vSphere v8.0
Помните, я говорил, что в основе vSphere лежит гипервизор ESXi? Именно под его требования и нужно подстраиваться. Старые версии — 6.5 и 6.7 — давно сняты с поддержки, 7.0 перешла в стадию extended support и постепенно уходит из продакшена.
В 2026 году всё ещё актуальна vSphere 8.x — она остаётся основной платформой в корпоративных и облачных инфраструктурах. Новая vSphere 9.0 будет постепенно вытеснять её с рынка (и должна занять её место примерно 11 октября 2027).
Итак, всю информацию я брал с официального сайта (и перевёл для вас). Так что в достоверности можете не сомневаться :)
Минимальные системные требования к оборудованию vSphere 8.0 и vSphere 9.0 (ESXi 8 и ESXi 9)
Чтобы установить или обновить ESXi 8 или 9 (требования у них аналогичны), оборудование и системные ресурсы должны соответствовать следующим требованиям:
Поддерживаемая серверная платформа. Полный список совместимых платформ см. в VMware Compatibility Guide.
ESXi 8.0 и ESXi 9.0 требует хост минимум с двумя ядрами CPU.
Поддерживаются 64-битные многоядерные процессоры архитектуры x86. Список протестированных моделей приведён в VMware Compatibility Guide.
Для работы ESXi 8.0 и ESXi 9.0 необходимо, чтобы в BIOS был включён бит NX/XD (No-eXecute / eXecute Disable).
Минимальный объём оперативной памяти — 8 ГБ, но для типовой производственной среды рекомендуется не менее 12 ГБ.
Для запуска 64-битных виртуальных машин требуется, чтобы на процессорах x64 была включена аппаратная виртуализация (Intel VT-x или AMD RVI).
Необходим один или несколько гигабитных сетевых контроллеров Ethernet или быстрее. Список поддерживаемых моделей также приведён в VMware Compatibility Guide.
Загрузочный диск должен иметь не менее 32 ГБ постоянного хранилища (HDD, SSD или NVMe). Загрузочное устройство не должно использоваться совместно несколькими хостами ESXi.
Для размещения виртуальных машин требуется диск SCSI или локальный, не сетевой RAID-LUN с незанятым пространством.
При использовании SATA диск должен быть подключён через поддерживаемый SAS-контроллер или поддерживаемый встроенный SATA-контроллер. SATA-диски рассматриваются как удалённые, а не локальные, и по умолчанию не используются для scratch-раздела, поскольку считаются внешними.
SATA-CD/DVD-привод нельзя подключить напрямую к виртуальной машине на хосте ESXi. Чтобы использовать SATA-CD-ROM, нужно включить IDE-эмуляцию.
Примечание:
Вы не можете подключить устройство SATA CD-ROM к виртуальной машине на хосте ESXi. Чтобы использовать устройство SATA CD-ROM, необходимо использовать режим эмуляции IDE.
Требования к загрузке ESXi — BIOS и UEFI:
Крайне рекомендую изучить этот (https://kb.vmware.com/s/article/84233) раздел базы знаний VMware, чтобы сэкономить время и убедиться в совместимости серверной платформы.
В vSphere 8.0 поддержка устаревших BIOS (Basic Input/Output System) ограничена, поэтому лучше загружать хосты ESXi с помощью UEFI (Unified Extensible Firmware Interface) — будет меньше проблем.
UEFI — это современная замена BIOS. С его помощью можно загружать системы с жестких дисков, приводов CD-ROM или USB-носителей. vSphere Auto Deploy поддерживает сетевую загрузку и инициализацию хостов ESXi с UEFI. Если система имеет DPU (Data Processing Unit, продвинутые сетевые карты, которые разгружают основной процессор сервера), то вы можете использовать UEFI только для установки и загрузки ESXi на DPU.
ESXi может загружаться с накопителя объемом более 2 ТБ, если системная прошивка и прошивка любой используемой дополнительной платы поддерживают это.
Требования к хранилищу при установке или обновлении ESXi 8.0:
При загрузке с локального диска, SAN или iSCSI LUN нужен накопитель не менее 32 ГБ — для создания системных томов хранения, которые включают загрузочный раздел, банки загрузки и том ESX-OSData на базе VMFS-L. Том ESX-OSData — это место размещения операционной системы ESXi, он также выполняет роль традиционного раздела /scratch, раздела блокировки (locker) для VMware Tools и назначения дампа ядра.
Для быстрой установки ESXi 8.0 используйте загрузочные внешние устройства объемом от 32 ГБ.
Для обновления до ESXi 8.0 требуется загрузочное устройство объёмом не менее 8 ГБ.
Примечание:
В ESXi 8.0 том ESX-OSData считается единым разделом, а отдельные компоненты, такие как /scratch и VMware Tools, объединены в один постоянный раздел OSDATA.
Другие параметры для обеспечения наилучшей производительности установки ESXi 8.0 следующие:
Для оптимальной поддержки ESX-OSData рекомендуется использовать локальный диск объемом 128 ГБ или больше. Данный диск содержит загрузочный раздел, том ESX-OSData и VMFS хранилище данных.
Устройство, поддерживающее минимум 128 ТБ записи (Total Byte Written). Прим. автора: TBW — показатель, который указывает на общее количество байтов, которое можно записать на накопитель (обычно SSD), до достижения его предельного ресурса износа. TBW выражается в терабайтах.
Устройство, обеспечивающее скорость последовательной записи не менее 100 МБ/с. Прим. автора: скорость последовательной записи означает, что накопитель может записывать данные последовательно на свою память без разделения на отдельные блоки или файлы.
Для обеспечения надежности в случае отказа устройства рекомендуется использовать зеркальное RAID 1 хранилище. Прим. автора: RAID 1 обеспечит дублирование данных на двух накопителях для повышения защищённости и возможности восстановления в случае отказа одного из них. Плюс скорость чтения выше (при распараллеливании). Что такое RAID-массивы?
Устаревшие устройства SD и USB поддерживаются со следующими ограничениями:
Устройства SD и USB поддерживаются для разделов банка загрузки. Использование устройств SD и USB для хранения разделов ESX-OSData устаревает, лучшая практика — предоставление отдельного постоянного локального устройства с минимальным объемом 32 ГБ для хранения тома ESX-OSData. Постоянное локальное загрузочное устройство может быть флэш-памятью M.2 промышленного класса (SLC и MLC), SAS, SATA, HDD, SSD или устройством NVMe. Оптимальная ёмкость постоянных локальных устройств составляет 128 ГБ.
Если вы не обеспечите постоянное хранилище, появится сигнал тревоги, например, Secondary persistent device not found. Переместите установку на постоянное хранилище, поскольку поддержка конфигурации только для SD-карты/USB прекращается.
Вы должны использовать флэш-устройство SD, одобренное поставщиком сервера для конкретной модели сервера, на котором вы хотите установить ESXi на флэш-устройство SD. Список одобренных устройств можно найти на сайте partnerweb.vmware.com.
Обновленное руководство для сред на базе SD-карт или USB см. в статье базы знаний 85685.
Чтобы выбрать подходящее загрузочное устройство SD или USB, см. статью базы знаний 82515.
В процессе обновления до ESXi 8.0 с версий ранее 7.x происходит переразметка загрузочного устройства и объединение исходных разделов дампа ядра, locker и scratch в том ESX-OSData.
В процессе переразметки происходят следующие события:
Если пользовательское место назначения дампа ядра не настроено, то местоположение дампа ядра по умолчанию — файл в томе ESX-OSData.
Если служба syslog настроена на хранение файлов журналов на 4 ГБ VFAT scratch partition, файлы журналов в var/run/log переносятся на том ESX-OSData.
Инструменты VMware переносятся из раздела locker, и раздел стирается.
Раздел дампа ядра стирается. Файлы дампа ядра приложения, хранящиеся на нулевом разделе, удаляются.
Примечание:
Откат к более ранней версии ESXi невозможен из-за процесса переразметки загрузочного устройства. Чтобы использовать более раннюю версию ESXi после обновления до версии 8.0, необходимо создать резервную копию загрузочного устройства до обновления и восстановить загрузочное устройство ESXi из резервной копии.
Если вы используете USB-или SD-устройства для обновления, то лучше всего выделить место под ESX-OSData на доступном постоянном диске или SAN LUN. Если постоянный диск или SAN LUN недоступны, ESX-OSData автоматически создаётся на RAM-диске. Для раздела ESX-OSData можно также использовать VMFS.
После обновления, если ESX-OSData находится на RAM-диске (ramdisk) и при последующих загрузках обнаруживается новое постоянное устройство с параметром autoPartition=True, ESX-OSData автоматически создаётся на новом постоянном устройстве. ESX-OSData не перемещается между постоянными хранилищами автоматически, но вы можете вручную изменить расположение ESX-OSData на поддерживаемом хранилище.
Чтобы изменить конфигурацию /scratch, см. раздел Настройка раздела Scratch из vSphere Client.
Для настройки размера системных разделов ESXi можно использовать параметр systemMediaSize. Дополнительные сведения см. в статье базы знаний https://kb.vmware.com/s/article/81166.
При равзёртывании через Auto Deploy программа установки пытается выделить нулевую область на доступном локальном диске или хранилище данных. Если локальный диск или хранилище данных не найдены, установка заканчивается неудачно.
В средах, загружающихся с SAN или использующих Auto Deploy, том ESX-OSData для каждого хоста ESXi должен быть создан на отдельном SAN LUN.
IV. Как подобрать сервер под VMWare vSphere: железо, комплектующие

Напомню, что я не знаю вашей задачи, а потому могу дать только общие рекомендации по железу. Но вы можете описать ситуацию менеджерам СЕРВЕР МОЛЛ — ребята бесплатно проконсультируют :) Во-вторых, есть полезные рекомендации из других моих статей. Советы отлично подойдут и под vSphere.
Чтобы не повторяться, я оставлю ссылки на популярные вопросы:
Какое поколение сервера выбрать в 2026 году
На 2026 год самые современные серверы — Dell PowerEdge G17 и HPE ProLiant Gen12. Это мощные, энергоэффективные и полностью готовые к новым поколениям процессоров Intel Xeon 6 и AMD EPYC 9005 Turin серверы. Они уже появляются в ограниченной продаже, но официально в Россию не поставляются — только через параллельный импорт ограниченными объёмами. В каталоге СЕРВЕР МОЛЛ некоторые модели есть в наличии.
ВАЖНО!
Самые последние поколения серверов подойдут только тем, кто хочет максимальную производительность и запас по будущим задачам, кто не планирует обновлять инфраструктуру ближайшие годы и готов к особенностям поставок по параллельному импорту (актуально и в 2026 году).
Так как G17 и Gen12 пока встречаются редко и стоят дорого, оптимальным выбором остаются предыдущие два-три поколения:
Dell PowerEdge: G16, G15 и G14;
HPE ProLiant: Gen11, Gen10 Plus / Gen10 Plus v2 и Gen10.
Эти поколения уже обкатаны в продакшене, поддерживают современные CPU и памяти DDR5 (начиная с Gen11 и G16), а также современные GPU-ускорители и PCIe 5.0. Для большинства задач — от корпоративных файловых серверов до виртуализации и ИИ-нагрузок среднего уровня — их производительности более чем достаточно.
После ухода Dell и HPE с российского рынка официальные партнёры (в том числе мы) продолжили поставки актуальных моделей по параллельным каналам. Серверы предыдущих поколений не столько устаревают, сколько сменяются новыми поколениями, но при этом остаются производительными и надёжными (если подходят под вашу задачу). Особенно сейчас, когда цены на G16 и Gen11 стабилизировались, а на G15 и Gen10 Plus v1/v2 — заметно снизились.
Актуальные серверы прямо сейчас (2026 год) — это Dell G16 и HPE Gen11. Они широко доступны, у них прекрасный баланс цены и производительности, поддерживают почти все современные технологии, есть почти во всех списках аппаратной совместимости (HCL), и останутся актуальны ещё как минимум 5–7 лет.
В СЕРВЕР МОЛЛ они в наличии, как и другие поколения: есть новые и восстановленные серверы под любой бюджет, с выездной гарантией до 5 лет и бесплатной доставкой. Если у вас нет времени разбираться в нюансах — просто опишите нам задачу (можно в чате на сайте даже), и мы подберём оптимальную конфигурацию под ваш бюджет.
С теорией разобрались — вернёмся к нашим электроовцам :)
VMWare серверы
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставка
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставка
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаПроцессор для VMWare vSphere

Процессор, он же ЦПУ aka CPU.
Итак, в первую очередь нужно понять, какие задачи будет выполнять сервер.
Если на виртуальных машинах будут работать высокотребовательные приложения, то понадобится процессор с большим количеством ядер и/или высокой тактовой частотой. Больше ядер — больше виртуалок, больше частота — быстрее обработка данных. Если же ВМ будут прогонять через себя большой объем данных, то нужно сделать упор на кэш-память — L2 и L3.

Учитывайте поколение процессора, так как одинаковая герцовка у разных поколенией (и даже производителей) даёт разный результат.
Не забывайте про многопроцессорность. Кстати vSphere практикует посокетную модель лицензирования (и не только).
Количество процессоров | Ядер на процессор | Количество лицензий |
1 | 1-32 | 1 |
2 | 1-32 | 2 |
1 | 33-64 | 2 |
2 | 33-64 | 4 |
Получаем, что иногда выгоднее взять 1 процессор на 32 ядра, чем 2 процессора по 16 ядер. Разумеется, для тех кто покупает VMware. Ну вы поняли.
Ремарка! Так как VMware в 2024 перешла на подписочную модель после того, как её поглотила Broadcom, посокетная схема больше не актуальна для новых подписок. Лицензирование теперь через VMware Cloud Foundation Subscription и vSphere Foundation, а не по сокетам. В конце статьи про это будет подробнее.
У Intel в 2026 году в серверном сегменте актуальны: Xeon 6 Granite Rapids (P-ядра) и Sierra Forest (E-ядра, до 288 ядер — для плотной виртуализации). Также на рынке много Xeon Scalable 5-го поколения (Emerald Rapids) — на них работает много серверов.
У AMD — актуальна серия EPYC 9005 (Turin, Zen 5), но EPYC 9004 (Genoa, Zen 4) пока встречается чаще. Кстати, Zen 5 добавил поддержку DDR5-6400 и PCIe 5.0/6.0.
Если закупка на 3–5 лет, то лучше ориентироваться на новые платформы (Intel Xeon 6, AMD EPYC Turin), поскольку они дают больший запас по производительности, технологиям, ядрам и т.д. Если бюджет ограничен, то смотрите на Xeon Scalable 5 и EPYC 9004.
Перед покупкой сервера проверьте, сколько сокетов под CPU в нём; очень важный параметр, если ваша компания и нагрузки vSphere растут, так как можно будет масштабироваться без замены оборудования.

Если у вас целый парк серверов, то процессоры с низким TDP сэкономят большую сумму в масштабах нескольких лет, но жертвовать производительностью не стоит, так что изучайте параметры энергопотребления CPU.
И не забывайте, что вы можете ограничивать TDP через BIOS/UEFI и профили энергосбережения; а также всегда учитывайте эффективное охлаждение и отвод тепла из серверной.
И раз уж о деньгах, то скажу страшное — серверные CPU стоят дороже обычных. Но экономить на процессоре — дело неблагодарное, если вопрос 5-10 тысяч, то лучше доплатить. Скупой сисадмин платит дважды: первый раз за дешевое оборудование, второй — за сбои в системе :)
Если денег совсем впритык, то ищите золотую середину между тем, что нужно, и тем, на что есть деньги: можно посмотреть предыдущие поколения или восстановленные серверы, или пишите менеджерам СЕРВЕР МОЛЛ — ребята бесплатно подберут решение.
Чтобы больше не повторяться про бюджет в других комплектующих , закреплю это здесь: подобрать комплектующие — полдела, уложиться в бюджет — вот где кáбель зарыт.
Оперативная память для VMWare vSphere

Теперь об оперативной памяти, она же память, она же ОЗУ aka RAM.
Количество виртуальных машин, которые будут работать на сервере — это база.
Каждая ВМ требует конкретного количества ОЗУ (напомню, что VMware vSphere тоже кушает ресурсы, так что закладываем память и на это). Нужно убедиться, что в совокупности у вас будет достаточно памяти для всех планируемых виртуалок и других потребностей сервера.
Следующее — это тип нагрузки. Для сложных задач, требующих большого объема памяти (аналитика, работа с базами данных и т.п.), нужно больше золота ОЗУ. Учтите, что модули в сервере нужно ставить группами в разные каналы, чтобы обеспечить многоканальный режим работы: Single Mode, Dual Mode, Triple Mode и Flex Mode. Иногда можно получить кратную преимущество в скорости работы.
8-канальный режим памяти стал де-факто стандартом для новых платформ, а неправильное заполнение слотов приводит к просадке пропускной способности.

И да, часто смотрят на объем, но скорость памяти (частота) важна не меньше. Если вы поставите в сервер высокопроизводительные процессоры и медленную память, то последняя при высокой нагрузке станет бутылочным горлышком — это как чайной ложкой уголь в горн засыпать. Смотрите на характеристики CPU (пример), требования приложений и подбирайте соответствующую по скорости память. Диапазон частот DDR5 — от 4800 до 6400 МГц в зависимости от платформы.

По поколениям — в 2026 году уже ориентируйтесь на DDR5. Если в сервере DDR4, то перед вами устаревающее оборудование (оно будет отлично работать, но индустрия переходит на новое). Все новые серверные платформы на базе AMD EPYC 9004/9005 и Intel Xeon 5/6 поддерживают только DDR5. А потому сервер с DDR4 сократит срок актуальности вашего оборудования.
Дальше — выбирайте одинаковые модули по всем характеристикам. Поясню: если коррекция ошибок (ECC) есть в одном модуле, то она должна быть везде. Если частота — 6400 МГц, ёмкость одного модуля — 32 ГБ, а тип — RDIMM, то это должно быть у всех модулей. Вникать в этот нюанс не обязательно, но знать его нужно.
Важна и поддержка CXL (Compute Express Link) — технология, в том числе пригодится для расширения оперативной памяти (и создания когерентного пула) в серверах. Почти всё оборудование корпоративного класса уже поддерживает CXL.
Ну и куда же без масштабируемости. Если в будущем понадобится больше виртуальных машин или работа более ресурсоемких приложений, то лучше взять памяти с запасом и посмотреть, какой потолок по объему у сервера. Слоты, к слову, тоже не безграничны, в некоторых моделях серверов их больше, в некоторых меньше — зависит от позиционирования оборудования и количества процессоров.
Напоследок расскажу про ранги памяти (полезная статья коллеги). Про них обычно умалчивают — тема относительно сложная, поэтому объясню на примере из жизни.

Представьте, что у нас есть библиотека, где каждый ряд книжных полок — это ранг памяти. Каждая книга на полке — это бит информации. Библиотекарь (в моём примере это контроллер памяти) может взять только одну книгу за раз, чтобы проверить или изменить информацию в ней.
Теперь представьте, что у нас есть одноранговая (Single-Rank, SR), двухранговая (Dual-Rank, DR) и четырёхранговая (Quad-Rank, QR) память.
Одноранговая память — одна полка с книгами. Библиотекарь может взять только одну книгу за раз из этого ряда.
Двухранговая память — две полки с книгами, одна над другой. Библиотекарь всё ещё может взять только одну книгу за раз, но теперь может выбирать из двух рядов, что увеличивает его возможности. С четырёхранговой — четыре полки.
Чем больше рядов (рангов), тем больше книг (битов информации) библиотекарь может выбрать за одно обращение, хотя и забирать он может только по одной книге за раз. Это повышает эффективность использования памяти, особенно когда нам нужно работать с большим количеством информации.
Но не всё так однозначно :) Чем больше рядов, тем больше времени требуется на переключение между ними, что может немного замедлить систему.
Больше рангов — дороже память, лучше работа с большим количеством виртуалок. Если виртуалок немного, а нагрузки простые, то вам хватит и одноранговой.
Но в идеале изучить рекомендации производителя сервера или документацию VMware для оптимальных конфигураций памяти.
В 2026 году широко используют модули 3DS RDIMM (высокой плотности), которые комбинируют преимущества DR и QR, поддерживаются в Xeon 5/6 и EPYC 9004+/9005.
Такие дела. Теперь к дисковой подсистеме.
GPU (графические ускорители) для VMware vSphere: оптимизация под AI/ML-нагрузки
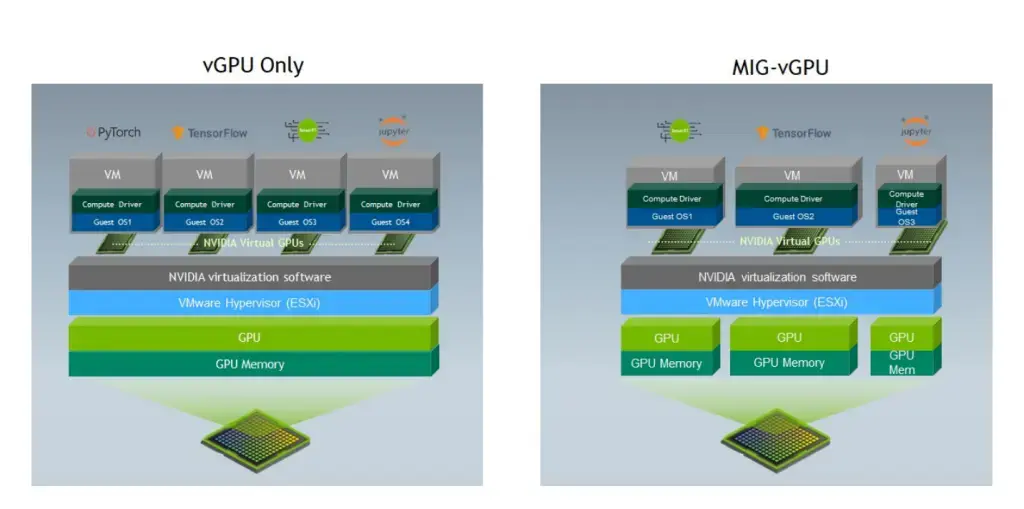
AI/ML‑нагрузки в виртуальной среде — это совсем другой уровень требований к серверу. Тут важны не только CPU и память, но и GPU. VMware vSphere уже давно добавила поддержку виртуальных GPU, а с 8-ой версией всё стало ещё лучше (добавлена поддержка до 8 vGPU на ВМ, Device Groups для ML-ворклоудов и интеграция с NVIDIA для разделения одно физического GPU на несколько изолированных экземпляров).
Отдельно упомяну MIG-vGPU. В поколении GPU Ampere и новее MIG-vGPU позволяет аппаратно разделить ресурсы на инстансы с полной изоляцией (каждый с гарантированной долей VRAM, CUDA-ядер и т.д.), минимизируя перерасход для обучения моделей — до 7 виртуалок на одном GPU с гарантированной производительностью.
Идём дальше.
Ремарка! Т 8 vGPU и 7 виртуалок — это про разные сценарии: первый про масштабирование GPU на одну VM, второй про деление GPU между разными VM.
Для начала надо решить, какие задачи вы будете решать. Если виртуальные машины будут выполнять интенсивное обучение нейросетей или инференс больших моделей, нужно правильно подобрать vGPU‑профиль под задачу: compute‑профили для обучения (для задач без графического вывода), графические — для визуализации и инференса; следом нужно оценить, сколько GPU и какая память реально потребуется; и, конечно, нужно учесть распределение нагрузок между хостами, чтобы минимизировать простои и добиться максимальной производительности.
Версия VMware vSphere 8 позволяет разделять один физический GPU между несколькими ВМ с разными vGPU‑профилями. Например, одна ВМ с compute‑профилем, другая с графическим — и обе эффективно используют один GPU.
Ремарка! Смешанные профили (compute + graphics на одном GPU) поддерживаются с vSphere 8 Update 3 (июль 2024). Ранее было ограничение на однотипные профили.
Кроме того, vMotion для таких виртуальных машин стал гораздо быстрее: миграция больших моделей больше не превращается в минутное ожидание — просто и удобно. В целом производительность AI/ML-нагрузок в vSphere 8 приближается к bare-metal (работа на голом железе, без виртуальных абстракций), что для виртуальной среды очень круто.
Несколько практических советов:
Старайтесь заранее планировать, какие виртуалки будут работать с какими профилями GPU, чтобы DRS мог правильно балансировать нагрузку.
Используйте мониторинг GPU, чтобы вовремя реагировать на перегрев или падение производительности.
Если нагрузка растёт, продумывайте масштабирование: vSphere 9 позволяет добавлять новые ВМ и GPU без простоев
В версии VMware vSphere 9 акцент смещается с базовой виртуализации на интеллектуальные фичи и управляемость. Здесь появились улучшенные возможности управления GPU: Fast‑Suspend‑Resume (FSR) — быстрая приостановка и восстановление виртуальных машин в платформе, ускоренный vMotion для больших vGPU, GPU‑aware DRS (Distributed Resource Scheduler, функция планирования распределённых ресурсов в платформе), расширенный мониторинг температуры и троттлинга.
V. Хранение данных в сервере vSphere

NAS и SAN на VMWare vSphere
В 2026 году почти все современные виртуальные инфраструктуры строят на базе NVMe-накопителей и протоколов NVMe-over-Fabrics (NVMe-oF), которые предлагают минимальные задержки и высокую пропускную способность при работе с хранилищем. Они стали стандартом для систем виртуализации и гиперконвергентных сред.
Вместе с ними всё шире используют vSAN Express Storage Architecture (ESA) — обновлённая архитектура хранилища, появившаяся в vSphere 8.0, и к 2026 году ставшая базовым решением для высокопроизводительных кластеров. Она раскрывает потенциал NVMe на полную, снижает накладные расходы на обработку данных и позволяет гибко масштабировать хранилище без потери эффективности.
Если будете использовать эти технологии, то получите серьёзный скачок в производительности: ВМ будут запускаться быстрее, а операции ввода-вывода будут идти с микросекундными (не мс) задержками даже в кластерах из десятков нод.
Локальные жесткие диски, SAN, vSAN или NAS для vSphere
Серверы — системы гибкие, так что у вас есть выбор, как всё реализовать: локальные жесткие диски или DAS, SAN (Storage Area Network), NAS (Network Attached Storage) или вовсе vSAN.
Локальные накопители (Local Storage) или DAS (Direct Attached Storage): это либо встроенные в сервер, либо подключенные к нему напрямую накопители (хранилища). Обычно это вариант по умолчанию, с которым просто работать, да и стоит относительно недорого, но есть нюансы — мобильность и масштабируемость ВМ ограничены, а некоторые функции vSphere на локальных дисках не работают вообще. Например, vMotion (перемещение ВМ между серверами без прерывания работы) или High Availability.
SAN (Storage Area Network): это сеть для передачи данных между серверами и удалёнными хранилищами (СХД, ленточные хранилища, другие серверы и т.д.). Плюс в том, что сервер воспринимает SAN как часть сервера, но у SAN нет информации о серверной ОС и файловой системе. Получаем высокую скорость работы, надёжность и низкую задержку — самый сок для виртуализации. C SAN работают функции vSphere vMotion, High Availability и Fault Tolerance. Минусы тоже есть — SAN дороже и сложнее в установке и обслуживании, чем DAS или NAS. В vSphere 8.x официально рекомендуются сети 25 Гбит/с и выше для кластеров vSAN и vMotion.
vSAN (Virtual Storage Area Network): vSAN — это программно-определяемое хранилище (Software-Defined Storage, SDS), интегрированное с VMware vSphere (но необязательная его часть). В vSAN локальные накопители с разных физических серверов (минимум с 2-ух, но лучше с 3-4) объединяются в общий пул. Получаем хранилище, которое отлично подходит для хранения данных виртуальных машин. У vSAN много преимуществ: гибко и просто масштабируется, легко управляется из vSphere, повышает доступность и отказоустойчивость IT-инфраструктуры. Но и минусы есть: отдельно нужно покупать лицензии (дорого, когда у вас много узлов), высокие требования (кластер серверов, обязательные быстрые SSD под кэш, сеть как минимум с 10 Гбит/c картами), нужно искать совместимое оборудование, vSAN работает на уровне гипервизора, а значит кушает ресурсы хоста.Также есть vSAN ESA — новая архитектура в vSphere 8, работает только с NVMe SSD и использует эффективное кодирование данных Erasure Coding 2.0 (повышенная производительность и надёжность).
NAS (Network Attached Storage): это устройство хранения файлов (именно файлов), по сути это специализированный сервер, к которому можно даже СХД подключить. Обычно NAS используют как datastore (хранилище файлов) для виртуальных машин. NAS можно подключать к одному или нескольким серверам по привычному Ethernet. Этот вариант проще и дешевле в установке и обслуживании, чем SAN, но поддерживает не все функции vSphere (прощай, Distributed Resource Scheduler и FT). Также производительность NAS обычно ниже, чем у SAN или локальных дисков, особенно если сеть перегружена трафиком.
Какой тип хранилища выбрать? Всё индивидуально:
Бюджет: Локальные диски и DAS обычно дешевле, чем SAN или NAS. NAS актуален в малом бизнесе, но в новых кластерных инфраструктурах его заменяют vSAN или гибридные NVMe-решения.
Производительность: У SAN выше производительность, особенно при работе с большим количеством ВМ с высокой нагрузкой.
Высокая доступность и отказоустойчивость: SAN и некоторые NAS обеспечивают функции высокой доступности и резервного копирования.
Масштабируемость: SAN и vSAN позволяют легко масштабировать хранилище по мере роста потребностей.
Так что при достаточном бюджете лучше выбирать SAN, но в малых IT-системах вполне можно использовать NAS, DAS, локальные накопители или их комбинации.
Резервное копирование и восстановление данных в vSphere

Как и всегда, нужно исходить из задач и требований. Поэтому есть минимум 3 вопроса, на которые нужно ответить:
1. Как часто делать резервные копии?
Нужно понять, какие данные важны — насколько, и как часто они изменяются.
Например, клиентская база очень важна и меняется часто. Может потребоваться резервирование каждый час. Бывают и некритичные данные, которые можно потерять без влияния на бизнес: устаревшие рекламные компании, данные о продуктах, которые больше не производятся и т.п. Их вообще можно не резервировать.
2. Как долго хранить резервные копии?
Если есть внутренний регламент или закон, то руководствуйтесь ими. Например, записи с видеокамер логично хранить не меньше недели или месяца, так как проблему можно найти позже, чем она произошла. Некоторые данные: отчетности, бухгалтерские, налоговые и кадровые документы нужно хранить в течение многих лет. Поэтому их резервирование обязательно, если не хотите штрафов.
3. Как быстро нужно восстановить данные после сбоя?
Те же налоговые документы можно восстановить хоть через неделю, но сервер, который хостил сайт, должен восстановиться как можно быстрее — час простоя бизнеса может стоить дороже самого сервера. А стратегия резервирования с быстрым восстановлением сложнее и стоит больше, так как требует дополнительного физического оборудования и настроек.
Когда ответим на эти вопросы, то можно переходить к практике. У VMWare vSphere есть встроенные и дополнительные решения для резервного копирования и восстановления:
Снимки VMware (Snapshots): Это быстрый способ создать резервную копию виртуальной машины, но это не замена полноценного резервного копирования. Снимки удобны для краткосрочного резервного копирования, например, перед внесением изменений в систему или рискованных (тестовых) операций. Снимки не стоит хранить долго, а в vSphere 8.0 улучшен механизм Snapshot Consolidation.
VMware Data Recovery (встроено в vCenter): Это полноценное решение, которое позволяет создавать полные резервные копии виртуальных машин и хранить их в течение заданного периода времени. Немного сложнее в управлении, но оно обеспечивает более надежное и долгосрочное решение.
Сторонние решения: Veeam, Commvault Complete Backup & Recovery, Кибер Бэкап. Это сторонний софт, который предлагает продвинутые функции: дедупликация, репликация, автоматизация и многие другие.
В vSphere 8.x расширена интеграция с VMware vSphere Replication 9.x и средствами Disaster Recovery Orchestrator (DRO). Veeam, Commvault, Acronis по-прежнему актуальны. Также в 2026 году для резервного копирования популярна интеграция через API Data Protection (ADP) и автоматизация с Ansible / Terraform.
Выбор индивидуален, но кое-что нужно сделать всем: настроить и протестировать систему резервного копирования, чтобы убедиться, что всё работает корректно и соответствует всем бизнес-требованиям.
VI. Сетевые возможности vSphere
Убедитесь в наличии достаточного количества сетевых интерфейсов vSphere

Нужно понять, сколько сетевых интерфейсов потребуется серверу VMware vSphere. Сейчас стандартная схема такая — два NIC по 25 Гбит/с или четыре по 10 Гбит/с: под управление, vMotion, vSAN и виртуальные сети. При проектировании стоит сразу учесть SR-IOV и vSwitch ENS (Enhanced Networking Stack) — в восьмой версии они заметно снижают задержку и уменьшают overhead при высоких нагрузках, особенно в инфраструктурах с десятками виртуальных машин.
Итак, посчитать порты для вашего случая можно в несколько шагов, я бы сделал это так:
Определить типы сетевого трафика: Обычно трафик можно разделить на четыре типа: трафик управления, трафик vMotion (перемещение виртуальных машин между хостами), трафик виртуальных машин и трафик vSAN (если есть). В идеале под каждый тип трафика выделить свой сетевой интерфейс — так выше производительность, надёжность и появится изоляция. Но можно и совместить, если у вас маленькая IT-инфраструктура.
Рассчитать общую пропускную способность: Считаем, какова пропускная способность каждого сетевого интерфейса и сколько интерфейсов нужно, чтобы закрыть все требования к пропускной способности. Если мне нужна общая пропускная способность 20 Гбит/с, а один интерфейс даёт 10 Гбит/с, то у сервера должно быть минимум два таких интерфейса. При этом не забудьте, что vMotion и vSAN могут кратковременно создавать всплески нагрузки — лучше иметь запас 25–30 %.
Учесть избыточность: Я всегда стараюсь иметь по крайней мере один запасной сетевой интерфейс на случай отказа основного. Убиваем двух кроликов: бесперебойная работа и обслуживание без прерывания основных процессов.
Понять, как устроена физическая сеть: Под некоторые задачи нужна изоляция и сегментация сети (повышенная безопасность, управление трафиком, изоляция ошибок, нормативные требования), а это дополнительные интерфейсы.
Иногда хватает портов “из коробки”, а иногда приходится устанавливать дополнительные сетевые платы. Для vSphere сетевые возможности сервера важны не меньше процессора или ОЗУ.
Сетевые протоколы для vSphere

Системные администраторы используют разные сетевые протоколы для разных задач, софта и оборудования — от этого напрямую зависит производительность и безопасность инфраструктуры. VMware vSphere поддерживает большинство отраслевых стандартов, поэтому разберём их в связке с типовыми задачами.
Основные сетевые протоколы для vSphere:
Ethernet/IP. Базовый транспорт для связи между виртуальными машинами и внешними сетями. Поддерживается практически всем сетевым оборудованием и гипервизорами.
TCP и UDP. Транспортные протоколы, обеспечивающие обмен данными между приложениями. TCP гарантирует доставку пакетов, UDP — минимальную задержку, что важно, например, для телеметрии и мультимедиа.
HTTP, HTTPS, FTP. Протоколы прикладного уровня, используемые для взаимодействия сервисов, передачи файлов и доступа к веб-интерфейсам управления.
iSCSI, NFS и FCoE. Классические протоколы доступа к удалённым хранилищам. В последние годы к ним добавился NVMe-over-Fabric (NVMe-oF) — современный вариант хранения, использующий TCP или RDMA и обеспечивающий минимальные задержки при работе с внешними SSD-массивами.
VLAN, VXLAN, Geneve. VLAN применяются для базовой сегментации сети, но начиная с vSphere 8 и NSX 4.x (ранее NSX-T) основной протокол оверлеев — Geneve, пришедший на смену VXLAN. Он поддерживает расширяемые метаданные, лучше интегрируется с политиками безопасности и стал стандартом для всех новых инсталляций NSX/vSphere в 2026 году.
Перед развёртыванием сверяемся, что оборудование поддерживает нужные протоколы и скорости, а также сразу закладываем в архитектуру переход на NVMe-oF и Geneve — эти технологии становятся базовыми в современных виртуальных инфраструктурах.
VII. Надежность и отказоустойчивость vSphere

Для полноценной отказоустойчивости и высокой надёжности нужны резервное питание и горячая замена комплектующих. Это распространённая практика для всех видов серверов (а не только для vSphere), если бизнесу критично, чтобы сервер всегда работал.
Резервирование питания — это ИБП (источники бесперебойного питания), дизельные и газовые генераторы (для больших инфраструктур) и даже разные магистральные сети питания. Можно использовать один или несколько вариантов.
Горячая замена комплектующих — это замена некоторых аппаратных комплектующих сервера без его отключения. Обычно это жесткие диски, блоки питания, сетевые карты и другие компоненты, которые могут выйти из строя. Но, например, процессор заменить без остановки не получится. Если у сервера 2 отсека под БП, то лучше занять оба и иметь минимум 1 БП про запас недалеко от сервера, чтобы быстро заменить при отказе.
Резервирование питания и горячую замену комплектующих нужно тестировать — искусственно отключайте питание или компонент под замену (до того, как на сервере заработают критически важные приложения).
В 2026 году часто делают мониторинг через Redfish API и интеграцию с Prometheus/Grafana для контроля аппаратной части.
Но помимо общих практик есть вещи посложнее, которые касаются именно vSphere.
Кластеризация и отказоустойчивые функции vSphere
Кластеризация — объединение нескольких серверов вместе, чтобы они работали как один. Получаем повышенную производительность и отказоустойчивость. Это нужно не всем — дорого и сложно; но под некоторые задачи нужен очень высокий уровень доступности, а тут без кластеризации никак.
Выше я упомянул vSphere Distributed Resource Scheduler (DRS) — это автоматический балансировщик нагрузки между серверами в кластере, что улучшает общую производительность и эффективность. Про vSphere High Availability (HA) тоже было, но напомню — это функция автоматического перезапуска ВМ на другом сервере в кластере, если один из серверов выходит из строя.
Чтобы эти функции работали корректно, нужно закладывать в серверы дополнительные ресурсы (процессорное время, память, пропускная способность сети). Ведь все оставшиеся ноды (другие серверы в кластере) должны полностью перенять на себя нагрузку вышедшего из строя. Поэтому, чем больше серверов в кластере, тем он устойчивее и дешевле в пересчёте на единицу.
Важно для vSphere 8.0 и выше:
DRS и HA усовершенствованы и теперь работают на базе нового алгоритма vSphere Distributed Services Engine, который поддерживает аппаратное ускорение через DPU (Data Processing Unit) offload. Это значит, что отказоустойчивость реализуется не только через программную кластеризацию, но и на уровне современных аппаратных ускорителей, что снижает задержки и перерасход ресурсов.
vCenter High Availability (vCenter HA) теперь разворачивается через Cluster Configuration Wizard, упрощая настройку и снижая риск ошибок.
Вышеупомянутая ESA в составе vSAN, переработанная с нуля под NVMe и SSD, даёт более высокую отказоустойчивость, ускоряет операции ввода-вывода и снижает нагрузку на CPU за счёт прямого обращения к накопителям.
vCenter High Availability (vCenter HA) теперь можно разворачивать прямо через встроенный Cluster Configuration Wizard — это упрощает настройку и уменьшает риск ошибок при ручной конфигурации.
После настройки всех отказоустойчивых функций обязательно проведите нагрузочные и имитационные тесты: отключите один из хостов, проверьте, как DRS перераспределяет ВМ, а HA перезапускает их. Такие тесты стоит повторять после каждого обновления vSphere или установки нового Update, потому что VMware регулярно меняет алгоритмы балансировки и поведения кластерных сервисов.
И опять же тесты — после настройки кластеризации и отказоустойчивых функций нужно провести стресс-тесты, чтобы убедиться, что всё работает правильно, а серверы справляются с нагрузками.
VIII. VMware после Broadcom — подписка, отличия и новая партнёрка
В ноябре 2023 года Broadcom окончательно проглотила VMware. Сделка — на 69 миллиардов долларов — стала одной из крупнейших в IT-индустрии. VMware ушла с биржи, но не из дата-центров. И если раньше она была классическим вендором софта для виртуализации, то теперь это часть гигантской экосистемы Broadcom.
Главное изменение — настал конец вечным лицензиям (perpetual license). Новые владельцы инициировали переход на подписочную модель. Бессрочная лицензия позволяла заплатить 1 раз и пользоваться сколько угодно, а теперь компаниям придётся покупать подписку — годовую или многолетнюю.
Формально идея здравая. Такая модель позволяет выпускать стабильные обновления в течение многих лет, поддержка лучше, фрагментация меньше. Но на практике же — выросли затраты и стало сложнее ориентироваться в тарифах.
Чтобы не запутаться, вот короткая шпаргалка:
Было (до Broadcom) | Стало (после Broadcom, 2024–2026) |
vSphere Standard, Enterprise Plus, Essentials — лицензии на сокет | VMware Sphere Foundation (VVF) — подписка на узел (host) |
Отдельные лицензии vCenter, vSAN, NSX | Всё объединено в VMware Cloud Foundation (VCF) |
Разрешалось покупать perpetual и продлевать поддержку | Только подписка (Subscription / SaaS) |
Много SKU-вариаций под любой бизнес | Несколько крупных пакетов, без тонкой настройки |
Поддержка — через партнёров VMware | Поддержка — через Broadcom Advantage Partner Program, компания реорганизовала партнёрские программы VMware — и с 5 февраля 2024 года ввела новые |
Теперь покупка vSphere — это уже не коробочный софт с гипервизором, а часть экосистемы VCF. Broadcom продвигает идею, что всё должно быть интегрировано, автоматизировано и управляться из одной консоли.
Лицензирование и стоимость VMware после Broadcom
Broadcom сократила линейку продуктов и перевела их в два больших пакета: VMware vSphere Foundation — базовый набор для серверной виртуализации, и VMware Cloud Foundation — флагман, включающий виртуализацию, хранение, сеть и управление жизненным циклом. Хочешь HA, vSAN, NSX и централизованное управление? Бери пакет VCF целиком. Частично больше нельзя.
Выглядит это так:
Решение | Что входит | На кого рассчитано |
vSphere Foundation (VVF) | ESXi, vCenter, базовые инструменты автоматизации и резервирования | Малые и средние компании, простая виртуализация |
VMware Cloud Foundation (VCF) | Всё из VVF + NSX, vSAN, Lifecycle Manager (vLCM), Aria, DR Orchestrator | Средние и крупные инфраструктуры, дата-центры, облака. Broadcom заявляла, что 70 % крупнейших клиентов уже перешли. |
Broadcom активно продвигает VCF как некий стандарт корпоративного уровня. По сути, это попытка создать полный стек управления частным и гибридным облаком под одной лицензией.
Новая партнёрская программа VMware после Broadcom
После поглощения Broadcom перезапустила партнёрскую программу. С февраля 2024 года VMware Partner Connect заменили на Broadcom Advantage Partner Program. Новая модель сократила количество уровней и ужесточила требования — работать теперь могут только крупные партнёры, прошедшие переквалификацию.
Для конечных клиентов это означает, что если раньше можно было купить VMware-лицензию у локального интегратора, то теперь надо проверять, входит ли он в новую партнёрскую сеть Broadcom. Некоторые старые дистрибьюторы, например Ingram Micro, вообще вышли из сотрудничества — из-за изменений условий. Для российского рынка изменений по дистрибуции как таковых нет (из-за ухода компании с рынка России). Все покупают софт VMware через юридические лица, зарегистрированные за пределами страны, или через альтернативные каналы.
ВАЖНО! Если VMware обнаружит подозрительную активность, необычно высокий трафик, компания легко сможет отследить причины. Затем, без предупреждения, она может деавторизовать всех пользователей, через которых прошел продукт, и заблокировать действие купленных лицензий. Эти риски нужно учитывать.
Подбор сервера для VMware после Broadcom
Если вы сейчас планируете покупать серверы под VMware, учитывать нужно не только технические параметры, но и бизнес-модель.
Во-первых, при расчёте бюджета стоит закладывать ежегодные подписки, а не единоразовые платежи. В зависимости от уровня VCF, лицензия на один узел может стоить больше, чем раньше на весь кластер.
Во-вторых, из-за укрупнения пакетов теперь важно правильно рассчитать нагрузку и не переплачивать за избыточный функционал. Например, если вам не нужны NSX и vSAN, то VCF, вероятно, будет излишним, а vSphere Foundation — оптимальным, хоть и компромиссным пакетом.
И наконец, всё, что касается совместимости, обновлений и поддержки — теперь централизованно на стороне Broadcom. Документация и HCL (Hardware Compatibility List) переехали с VMware Customer Connect и других сервисов на Broadcom Support Portal, а часть старых ссылок VMware уже не работает.
IX. Заключение

Поглощение VMware — не катастрофа, а классическая консолидация бизнесов под крылом техногиганта. Broadcom сделала то, что делает любая корпорация после поглощения: интегрировала в себя, упростила линейку, закрыла слабые направления, перевела всё на подписку и переориентировала бизнес на окупаемость инвестиций.
Для пользователей это новая реальность. Но VMware остаётся, пожалуй, самой мощной и зрелой платформой для виртуализации, но теперь её экосистема ближе к облачным сервисам и крупным корпорациям. И если раньше виртуализация была инструментом для админов, то теперь это сервис для бизнеса.
Фух. Пожалуй, опять вышла самая подробная статья в рунете — добавляйте в закладки (Ctrl + D) и через содержание возвращайтесь к нужному пункту :)
Чтобы не повторяться, вывод по статье будет коротким: подбор правильного серверного оборудования для VMware vSphere — это баланс между требованиями, бюджетом и будущими планами. Чем лучше вы понимаете свои потребности и цели, тем лучше вы сможете сделать этот выбор.
Поэтому процесс лучше делегировать опытным техническим спецам — штатным или нашим :) Опишите задачу менеджерам СЕРВЕР МОЛЛ и получите КП через час. Сэкономим ваше время и бесплатно подберём сервер(ы) под VMware vSphere.
Обновлено в 2026 году: добавлены актуальные поколения серверов и рекомендации по сокетам и комплектующим, переработан раздел про совместимость с гипермасштабируемыми средами и автоматизацию. Учтены изменения после поглощения VMware компанией Broadcom: обновлены сведения о лицензировании, добавлены разъяснения по новым пакетам лицензий и особенностям поддержки версий ESXi 8.x и 9.x. Также исправлены устаревшие данные и улучшена структурная читабельность текста.






Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение