

Графические процессоры Nvidia для центров обработки данных уже стали золотым стандартом для обучения и инференса моделей ИИ. Этому способствуют их высочайшая производительность, использование памяти HBM с колоссальной пропускной способностью, скоростные соединения в пределах стойки и отлаженный программный стек CUDA. Но по мере того как ИИ проникает повсюду, а модели — особенно у крупных гиперскейлеров — становятся всё больше, Nvidia видит смысл в том, чтобы «разделить» свой стек для инференса. Для этого компания планирует использовать специализированные GPU, чтобы ускорить так называемую контекстную фазу. На этом этапе модель должна обработать миллионы входных токенов одновременно, чтобы выдать первый результат, и делать это на дорогих и прожорливых GPU с памятью HBM не очень рационально. На этой неделе компания представила своё решение проблемы — ускоритель Rubin CPX (Content Phase aXcelerator). Он будет работать в связке с GPU Rubin и CPU Vera, беря на себя специфические рабочие нагрузки.
Переход на память GDDR7 даёт несколько ключевых преимуществ, даже несмотря на то, что её пропускная способность существенно ниже, чем у HBM3E или HBM4. Она потребляет меньше энергии, значительно дешевле в расчёте на гигабайт и не требует таких дорогостоящих технологий сборки, как CoWoS. Всё это в конечном счёте должно снизить итоговую стоимость продукта и помочь избежать производственных трудностей.
Что такое инференс с длинным контекстом?
Современные большие языковые модели вроде GPT-5, Gemini 2 или Grok 3 стали не только больше по размеру и лучше справляются с логическими рассуждениями, но и получили возможность обрабатывать такие объёмы входных данных, которые раньше были им недоступны — и пользователи этим активно пользуются. Архитектурно эти модели теперь гораздо эффективнее используют расширенные контекстные окна. Сам процесс инференса в таких крупных моделях всё чаще делят на две части: начальная, крайне требовательная к вычислениям контекстная фаза, которая обрабатывает весь входной запрос для генерации самого первого токена ответа, и следующая фаза, которая генерирует последующие токены, основываясь на уже обработанном контексте.
Поскольку модели эволюционируют в сторону агентных систем, инференс с длинным контекстом становится критически важным. Он позволяет им вести пошаговые рассуждения, сохранять память между задачами, поддерживать связный диалог в несколько циклов, а также планировать и вносить правки на основе больших входных данных. Без этого все эти возможности упирались бы в ограничения контекстного окна. Возможно, главная причина растущей важности длинного контекста даже не в том, что модели на это способны, а в том, что пользователям нужен ИИ, который может анализировать объёмные документы и базы с исходным кодом, или генерировать длинные видео.
Источник изображения: NVIDIA
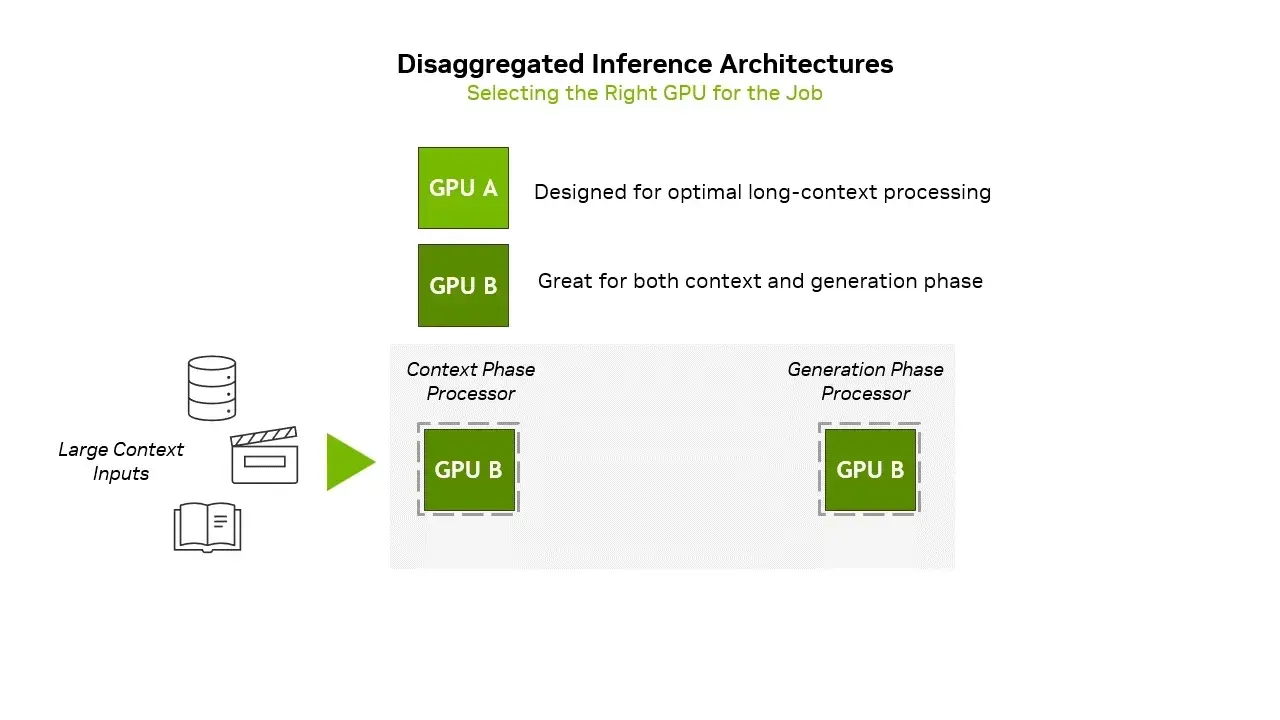
Подобный тип инференса бросает уникальный вызов аппаратному обеспечению. Контекстная фаза, когда модель считывает и кодирует весь входной запрос, прежде чем выдать что-либо на выходе, упирается в вычислительную мощность. Для обработки контекста в миллион и более токенов требуется огромная пропускная способность вычислений, большой объём памяти (но не обязательно её высокая пропускная способность) и оптимизированные механизмы внимания — это уже задача разработчиков моделей. Да, традиционные GPU для ЦОДов оснащены большим количеством памяти HBM и справляются с такими задачами, но использовать их для этого — не самый эффективный путь. Поэтому для контекстной фазы Nvidia намерена задействовать Rubin CPX с 128 ГБ памяти GDDR7 на борту.
На второй фазе модель, используя уже закодированный контекст, генерирует выходные токены один за другим. Этот шаг уже упирается в пропускную способность памяти и скорость соединений, так как требуется быстрый доступ к ранее сгенерированным токенам и кешам внимания. С этим эффективно справляются как раз традиционные GPU для ЦОД — такие как Blackwell Ultra (B300, 288 ГБ HBM3E) или Rubin (288 ГБ HBM4), которые потоково обрабатывают и обновляют последовательности токенов в реальном времени.
Знакомимся с Rubin CPX
Чтобы удовлетворить новые запросы, Nvidia разработала специализированное аппаратное решение — графический процессор Rubin CPX, созданный специально для инференса с длинным контекстом.
Карта-ускоритель Rubin CPX построена на архитектуре Rubin и обеспечивает до 30 NVFP4 петафлопс вычислительной мощности (это весьма много, учитывая, что «большой» Rubin R100 с двумя чиплетами выдаёт 50 NVFP4 петафлопс). Она оснащена 128 ГБ памяти GDDR7. В процессор также встроен аппаратный блок ускорения механизма внимания (который включает в себя дополнительное оборудование для матричного умножения) — это крайне важно для работы с длинным контекстом без потерь в скорости. Кроме того, есть аппаратная поддержка кодирования и декодирования видео для его обработки и генерации.
Одной из ключевых особенностей Rubin CPX является как раз использование памяти GDDR7. Да, её пропускная способность значительно ниже, чем у HBM3E или HBM4, но зато она энергоэффективнее, намного дешевле за гигабайт и не требует дорогих и сложных методов сборки, таких как CoWoS. В итоге, Rubin CPX не только дешевле обычных процессоров Rubin, но и потребляет существенно меньше энергии, что упрощает систему охлаждения.

Источник изображения: NVIDIA
Если бегло взглянуть на снимок кристалла Rubin CPX, предоставленный Nvidia, можно заметить, что его компоновка напоминает высокопроизводительные графические процессоры — настолько, что даже теплораспределительная крышка похожа на ту, что используется в GB202. Этот ASIC действительно содержит 16 графических кластеров (GPC), которые, предположительно, включают в себя блоки для работы с графикой (например, растеризацию, текстурные блоки), огромный кэш второго уровня (L2), восемь 64-битных контроллеров памяти, а также контроллеры PCIe и вывода изображения. А вот интерфейсов типа NVLink на чипе, кажется, нет, так что остаётся лишь гадать, общается ли он с другими компонентами исключительно через PCIe.
Также остаётся загадкой, использует ли Rubin CPX графическое ядро GR102/GR202 (которое будет лежать в основе видеокарт следующего поколения для потребителей и профессионалов) или же это уникальный ASIC. С одной стороны, использовать игровой GPU для ускорения AI-инференса — не ново: GB202 предлагает 4 NVFP4 петафлопс, а GB200 — целых 10. Размещать большое количество FPU с поддержкой NVFP4 и аппаратных ускорителей внимания в GPU, предназначенном для графики, может быть не самым оптимальным решением с точки зрения площади кристалла. Но, с другой стороны, выпускать два почти максимальных по размеру чипа с похожей функциональностью вместо одного — неэффективно с точки зрения затрат, инженерных усилий и сроков выхода на рынок.
Rubin CPX будет работать в тандеме с GPU Rubin и CPU Vera в системе Vera Rubin NVL144 CPX. В рамках одной стойки такая система выдаёт 8 экзафлопс производительности в формате NVFP4 (из которых 3,6 экзафлопс дают «большие» GPU Rubin, а 4,4 экзафлопс — Rubin CPX) и располагает 100 ТБ памяти. Как и другие продукты Nvidia масштаба всей стойки, Vera Rubin NVL144 CPX будет использовать высокоскоростную сеть Nvidia Quantum-X800 InfiniBand или Spectrum-XGS Ethernet в сочетании с адаптерами ConnectX-9 SuperNICs для масштабируемости.
В Nvidia подчёркивают, что архитектура Rubin CPX не ограничивается стойками Vera Rubin NVL144 CPX. Компания планирует предлагать вычислительные модули (trays) Rubin CPX для интеграции в системы Vera Rubin NVL144. Правда, похоже, что существующие платформы на архитектуре Blackwell не смогут работать с модулями Rubin CPX для оптимизированного инференса, хотя точные причины этого не называются.
По заверениям Nvidia, независимо от масштаба развёртывания, Rubin CPX должен принести заметную экономическую выгоду. Компания заявляет, что инвестиции в 100 миллионов долларов в эту платформу потенциально могут принести до 5 миллиардов долларов дохода от приложений, которые взимают плату за использование токенов. Это означает от 30- до 50-кратную отдачу на вложенный капитал. Такой расчёт основан на способности Rubin CPX снижать стоимость инференса (поскольку он дешевле и экономичнее полноценного R100) и расширять круг задач, которые можно выполнить при помощи AI.
Переписывать ПО не придётся
Со стороны программного обеспечения Rubin CPX полностью поддерживается всей экосистемой ИИ от Nvidia, включая CUDA, различные фреймворки, инструменты и NIM-микросервисы, необходимые для развёртывания готовых AI-решений. Он также совместим с семейством моделей Nemotron, созданных для корпоративного многомодального анализа.

Источник изображения: NVIDIA
Разработчикам моделей и приложений на ИИ не нужно будет вручную распределять первую и вторую фазы инференса между разными GPU при работе со стоечными решениями Rubin NVL144 CPX. Вместо этого Nvidia предлагает использовать свой программный слой оркестрации под названием Dynamo, который интеллектуально управляет рабочими нагрузками инференса и распределяет их между разными типами GPU в системе. Когда поступает запрос, Dynamo автоматически определяет, что начинается требовательная к вычислениям контекстная фаза, и направляет её на специализированные Rubin CPX, которые как раз оптимизированы для быстрой работы с вниманием и обработки больших входных данных. Как только контекст закодирован, Dynamo плавно переключается на фазу генерации, перенаправляя её на GPU с большим объёмом памяти, такие как стандартный Rubin, которые лучше подходят для последовательного создания токенов. По словам Nvidia, Dynamo также умеет управлять передачей KV-кэша и сводить задержки к минимуму.
Первые заказчики уже есть
Несколько компаний уже заявили о планах по интеграции Rubin CPX в свои рабочие процессы:
-
Cursor, разработчик ИИ-инструментов для программистов, будет использовать Rubin CPX для поддержки генерации кода в реальном времени и инструментов совместной разработки.
-
Runway намерена использовать Rubin CPX для реализации длинного контекста и агент-управляемой генерации видео. Это позволит создателям — от независимых художников до крупных студий — производить киноконтент и визуальные эффекты с большей скоростью, реализмом и творческой свободой.
-
Magic, исследовательская компания, разрабатывающая автономных агентов для написания кода, планирует с помощью Rubin CPX поддерживать модели с контекстным окном в 100 миллионов токенов. Это позволит их агентам работать, имея полный доступ к документации, истории кода и взаимодействиям с пользователем в реальном времени.
Новая парадигма
С момента появления архитектур Pascal и Volta около десяти лет назад GPU Nvidia сами были ускорителями для CPU. Теперь же с приходом Rubin CPX эти GPU получают свои собственные ускорители. Разделив две стадии инференса — обработку контекста и генерацию токенов — Nvidia позволяет гораздо более целенаправленно использовать аппаратные ресурсы, повышая общую эффективность системы. Это знаменует собой важный сдвиг в подходе к оптимизации AI-инфраструктуры для достижения максимальной эффективности.
Оптимизация инференса с длинным контекстом не только снижает затраты на оборудование и общую стоимость владения (TCO), но и открывает дорогу для высокопроизводительных платформ, способных стабильно обрабатывать нагрузки в миллионы токенов. Такие платформы могут сделать возможными ещё более сложные инструменты для AI-ассистирования в инженерии, генерацию полнометражного видео и другие приложения ИИ, которые сегодня кажутся фантастикой.
Первая платформа от Nvidia на базе Rubin CPX, Vera Rubin NVL144 CPX, должна появиться в конце 2026 года.





Нажимая кнопку «Отправить», я даю согласие на обработку и хранение персональных данных и принимаю соглашение