
Компания AMD представила свои новые графические процессоры MI350X и MI355X для задач искусственного интеллекта на мероприятии Advancing AI 2025. AMD стремится улучшить свои позиции и потеснить главного конкурента и лидера на рынке решений для ИИ - компанию NVIDIA. AMD утверждает, что новинки опережают решения NVIDIA в бенчмарках вывода ИИ (inference) и лидируют в некоторых нагрузках обучения моделей ИИ (training). AMD также заявляет о четырехкратном увеличении производительности по сравнению с предыдущим поколением моделей AMD MI300X и о 35-кратном увеличении производительности в задачах вывода (inference). Этот скачок в значительной степени достигнут благодаря переходу на архитектуру CDNA 4 и использованию более передового и компактного технологического процесса для чиплетов. Новые ИИ-ускорители серии MI300 будут использоваться в серверных решениях AMD до конца этого года и в 2026 году, пока компания готовится к выходу MI400. Сейчас же давайте подробно разберемся с техническими характеристиками и возможностями MI350X и MI355X.

Источник изображений: AMD
Производительность, память и энергопотребление MI350X и MI355X
MI350X и MI355X имеют идентичную базовую конструкцию, оснащены до 288 ГБ памяти HBM3E, обеспечивают до 8 ТБ/с пропускной способности памяти и получили поддержку форматов данных FP4 и FP6. Однако MI350X ориентирован на решения с воздушным охлаждением и имеет более низкую общую мощность платы (Total Board Power, TBP), в то время как MI355X отличается повышенным энергопотреблением и предназначен для систем с жидкостным охлаждением, которые ориентированы на достижение максимальной возможной производительности.
Сообщается, что AMD не выпустит APU-версию этого чипа, как это было с MI300A предыдущего поколения, который сочетал ядра CPU и GPU на одном кристалле.
Ускоритель AMD MI355X обладает в 1,6 раза большей емкостью памяти HBM3E по сравнению с конкурирующими GPU NVIDIA GB200 и B200, но обеспечивает такую же пропускную способность памяти в 8 ТБ/с. AMD заявляет о двукратном преимуществе в пиковой производительности FP64 / FP32 по сравнению с чипами NVIDIA, что неудивительно, учитывая фокус NVIDIA на оптимизации для более подходящих для ИИ низкоточных форматов. Примечательно, что матричная производительность MI350 в формате FP64 была сокращена вдвое по сравнению с MI300X, хотя векторная производительность снизилась примерно на 4% по сравнению с предыдущим поколением.

Источник изображений: AMD
При переходе к низкоточным форматам, таким как FP16, FP8 и FP4, AMD держится на одном уровне или незначительно превосходит аналогичные продукты NVIDIA. Особо выделяется производительность в формате FP6, которая аналогична производительности на уровне FP4, что AMD рассматривает как отличительную особенность.
Так же, как и в случае с конкурирующими чипами NVIDIA, новая конструкция и возросшая производительность также сопровождаются повышенным энергопотреблением. Общая мощность платы (TBP) достигает 1400 Вт для высокопроизводительной модели MI355X с жидкостным охлаждением. Это значительный рост по сравнению с MI300X (750 Вт) и MI325X (1000 Вт). С другой стороны, AMD утверждает, что теперь клиенты могут вместить больше вычислительных мощностей в одну серверную стойку, тем самым улучшив крайне важное соотношение общей производительности к совокупной стоимости владения (TCO).
Архитектура чипов MI350X и MI355X
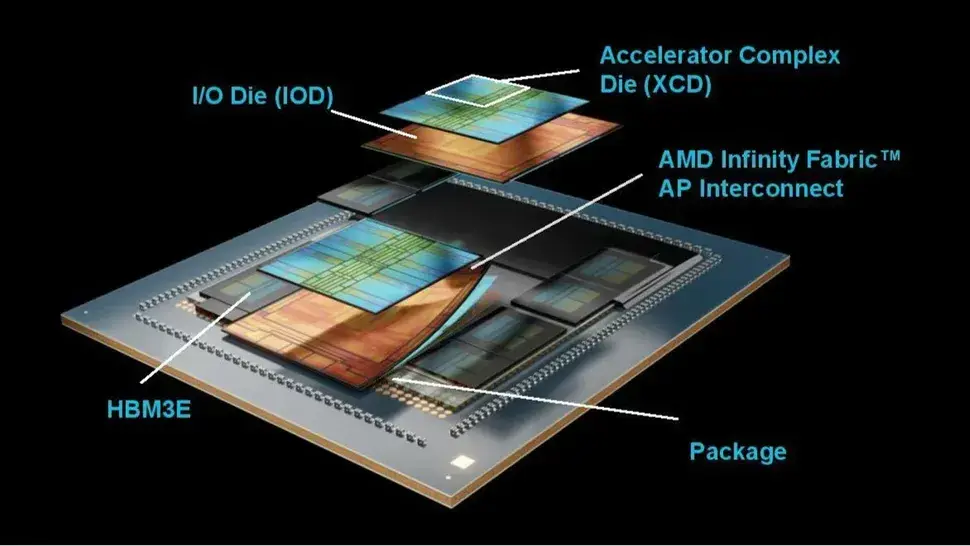
Новые чипы обладают многочисленными усовершенствованиями относительно производительности, но фундаментальные принципы проектирования, заключающиеся в объединении технологий 3D и 2.5D packaging, остаются неизменными. Первая (3D) используется для соединения вычислительных кристаллов ускорителя (Accelerator Compute Dies, XCD) с кристаллами ввода-вывода (I/O Dies, IOD), в то время как вторая (2.5D) используется для соединения IOD друг с другом и 12-слойными стеками памяти HBM3E.
Чип содержит в общей сложности восемь чиплетов XCD, каждый из которых имеет 32 активных вычислительных блока (compute unit, CU), что в сумме составляет 256 CU (AMD резервирует по четыре CU на каждый XCD для повышения выхода годных кристаллов). XCD перешли с 5-нм техпроцесса у предыдущего поколения на кристаллы, произведенные по техпроцессу N3P компании TSMC для серии MI350. Общее количество транзисторов в чипе достигает колоссальных 185 миллиардов, что на 21% больше в сравнении с 153 миллиардами у предыдущего поколения.
Кроме того, хотя кристалл ввода-вывода (IOD) остается на техпроцессе N6, AMD сократила количество тайлов IOD с четырех до двух, чтобы упростить конструкцию. Эта реорганизация позволила AMD удвоить ширину шины Infinity Fabric, увеличив двунаправленную пропускную способность (bi-sectional bandwidth) до 5,5 ТБ/с, а также снизить энергопотребление за счет уменьшения частоты и напряжения. Также, как и в серии MI300, Infinity Cache расположен перед памятью HBM3E (32 МБ кэша на каждый стек HBM).
Готовый процессор подключается к хосту через интерфейс PCIe 5.0 x16 как единое логическое устройство. GPU взаимодействует с другими чипами через семь каналов связи Infinity Fabric, обеспечивая общую пропускную способность 1075 ГБ/с.

Источник изображений: AMD
Как MI350X, так и MI355X выпускаются в форм-факторе OAM (OCP Accelerator Module) и устанавливаются в стандартизированные серверы форм-фактора UBB (Universal Baseboard), так же как и MI300X предыдущего поколения. Согласно заявлению AMD, это позволяет сократить время, необходимое для развертывания.
Стоит также отметить, что чипы взаимодействуют друг с другом по топологии "каждый с каждым" (all-to-all), где восемь ускорителей на узел обмениваются данными через двунаправленные каналы связи Infinity Fabric с пропускной способностью 153,6 ГБ/с. Каждый узел питается от двух процессоров AMD EPYC пятого поколения (Turin).
AMD поддерживает все формы сетевого взаимодействия, но позиционирует свои новые сетевые карты (NIC), совместимые со стандартом Ultra Ethernet (UEC) как оптимальное решение для горизонтального масштабирования (scale-out), в то время как для вертикального масштабирования (scale-up) предлагается использовать интерконнект Ultra Accelerator Link (UAL).
AMD предлагает системы как с прямым жидкостным охлаждением (Direct Liquid Cooling, DLC), так и с воздушным охлаждением (Air Cooled, AC). Стойки DLC оснащаются 128 GPU MI355X и 36 ТБ памяти HBM3E, в то время как решения с воздушным охлаждением ограничены 64 GPU и 18 ТБ HBM3E.
Результаты тестов производительности MI350X и MI355X
AMD представила некоторые из своих прогнозов производительности, а также результаты тестов, сравнивая их не только с собственными системами предыдущего поколения, но и с аналогами от NVIDIA. Всегда стоит относится к бенчмаркам, предоставленным самими вендорами оборудования, с долей скепсиса - тем не менее, мы не могли не включить эти данные в статью.
Источник изображений: AMD
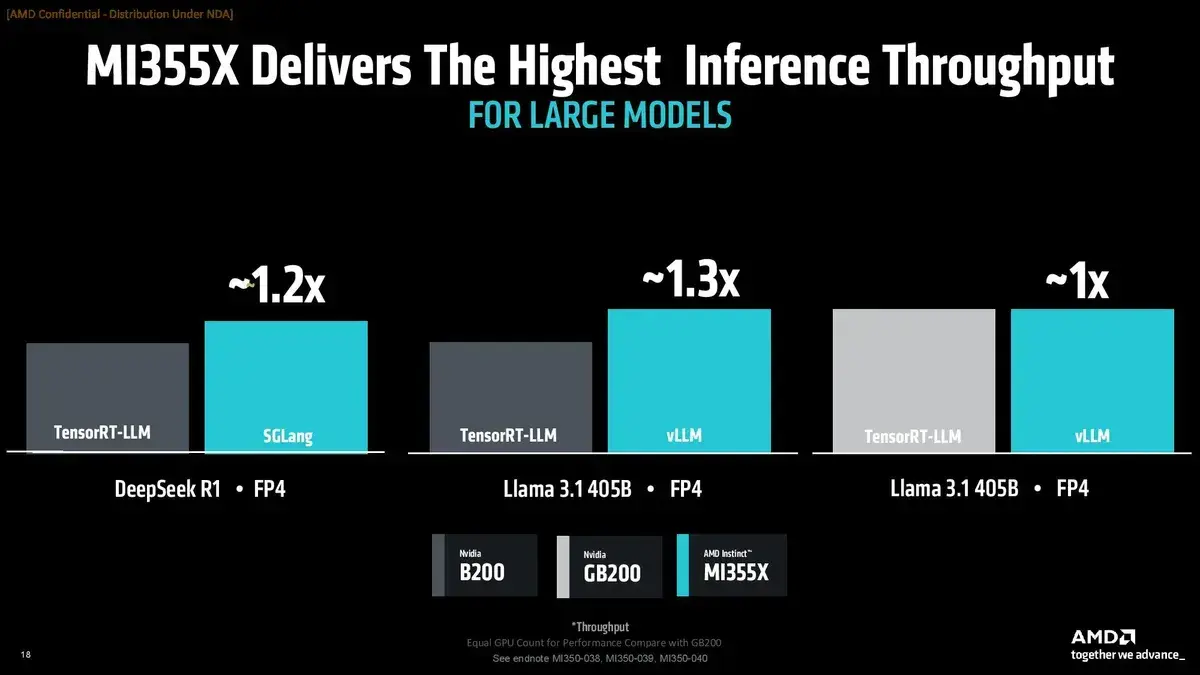
AMD утверждает, что конфигурация с восемью MI355X демонстрирует прирост производительности:
-
на 30% (четыре MI355X против четырех DGX GB200) в модели Llama 3.1 405B
-
на 20% (восемь MI355X против восьми GPU B200) в конфигурации HGX при выводе (inference) в модели DeepSeek R1
-
эквивалентную производительность в модели Llama 3.1 405B (все тестировалось в формате FP4).
AMD также заявляет, что MI355X конкурентоспособен с B200 и GB200 от NVIDIA в нагрузках, связанных с обучением моделей, хотя здесь компания подчеркивает скорее паритет, чем заметное преимущество в производительности.
Источник изображений: AMD
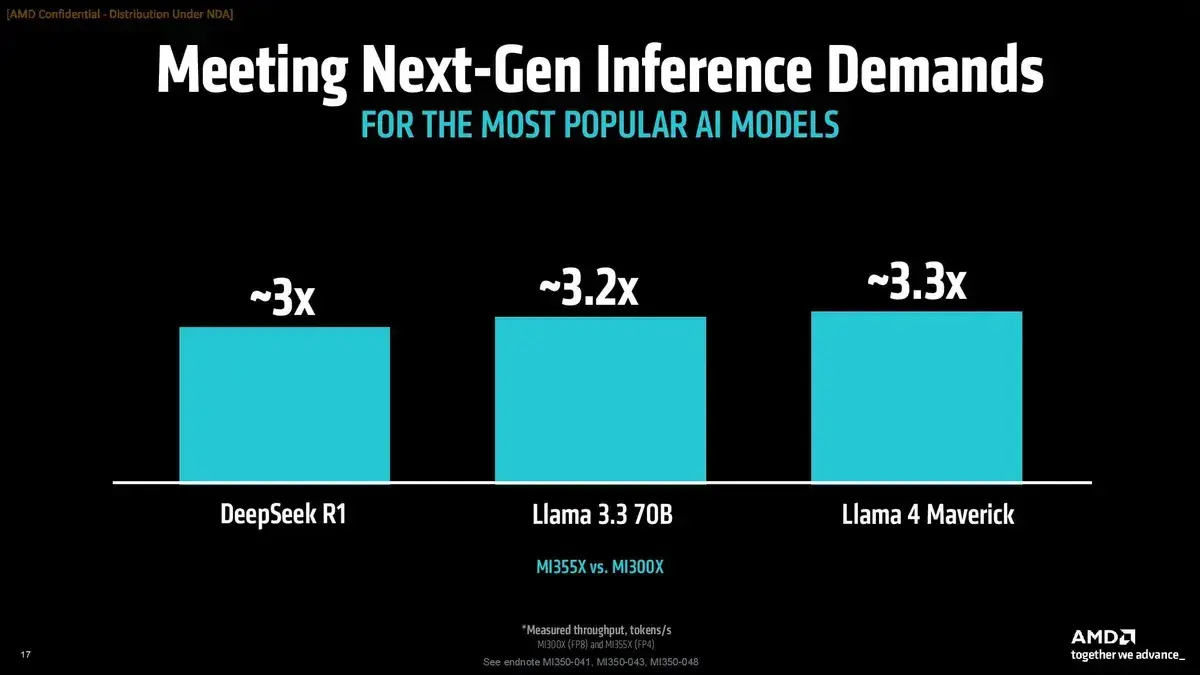
Наконец, по словам AMD, MI355X обеспечивает до 4,2 раза больший уровень производительности (по сравнению с MI300X) при обеспечении работы ИИ-агентов и чат-ботов, а также значительный прирост (от 2,6 до 3,8 раза) в задачах генерации контента, суммаризации и работы с диалоговым ИИ. Другие ключевые улучшения включают трехкратный прирост производительности в модели DeepSeek R1 и более чем трехкратный прирост в модели Llama 4 Maverick (см. изображение выше).




