
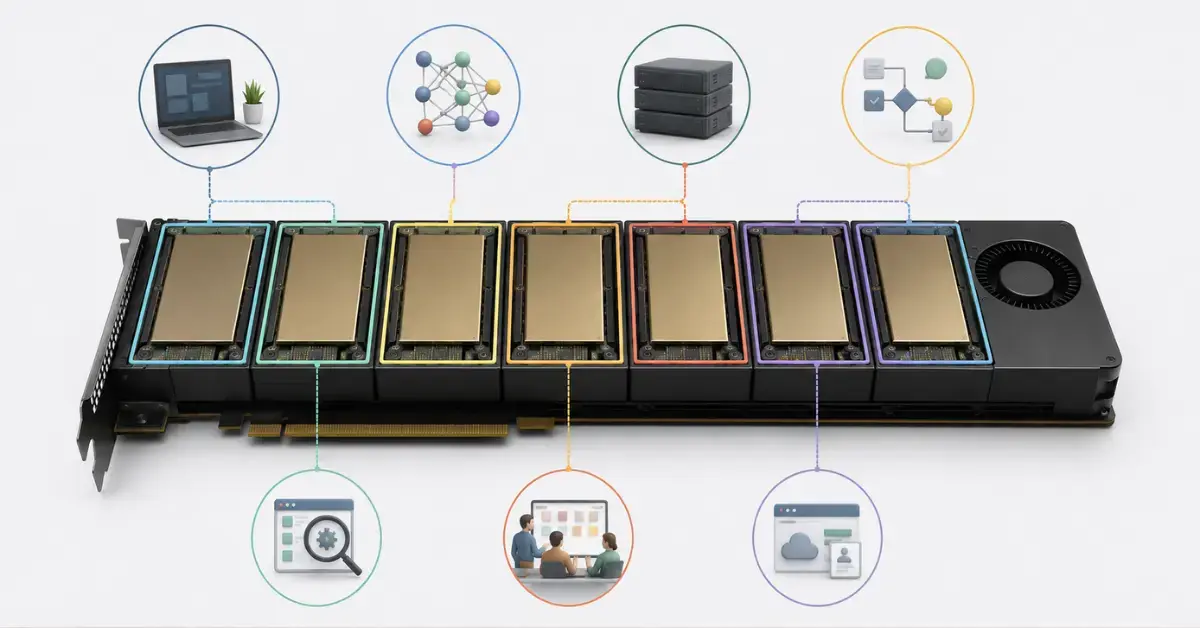
MIG нужен, когда одна NVIDIA A100, H100 или H200 слишком мощная для одной задачи, но ее нужно безопасно и предсказуемо разделить между несколькими пользователями, сервисами или командами. С помощью MIG физическая видеокарта разбивается на несколько изолированных инстансов: каждый получает свою часть вычислительных ресурсов и видеопамяти. Это хорошо подходит для inference, тестовых сред, notebook’ов, нескольких небольших моделей и ML-платформ, но не всегда подходит для крупного распределенного обучения, где лучше использовать целые физические GPU.
Современные ускорители для ИИ редко покупают «с запасом на один эксперимент». Их ставят в серверы, где одна и та же видеокарта может понадобиться разработчикам, аналитикам, MLOps-команде, внутренней платформе машинного обучения или нескольким клиентам. В такой ситуации быстро возникает проблема: один пользователь запускает небольшую модель и занимает всю карту, хотя реально использует только часть видеопамяти и вычислительных блоков.
MIG решает именно эту задачу. Технология позволяет разделить одну поддерживаемую GPU на несколько независимых частей. В системе они выглядят как отдельные устройства меньшего размера. Например, одну A100 80 ГБ можно разделить на несколько инстансов по 10, 20 или 40 ГБ, а H200 141 ГБ — на профили с большим объемом памяти для более тяжелых моделей.
Для компаний, которые подбирают видеокарты NVIDIA для ИИ и нейросетей, MIG важен не меньше, чем общий объем видеопамяти или поколение GPU. Он помогает понять, как именно будет использоваться карта: одной задачей целиком или несколькими рабочими нагрузками параллельно.
Серверы NVIDIA DGX

 5 лет гарантии
5 лет гарантии Бесплатная доставка
Бесплатная доставкаот 116 666 760 ₽
4 054 170 ₽/мес в лизинг
от 97 222 300 ₽
+ 19 444 460 НДС
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 64 235 160 ₽
2 232 172 ₽/мес в лизинг
от 53 529 300 ₽
+ 10 705 860 НДС
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 84 645 600 ₽
2 941 435 ₽/мес в лизинг
от 70 538 000 ₽
+ 14 107 600 НДС
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 15 897 960 ₽
552 454 ₽/мес в лизинг
от 13 248 300 ₽
+ 2 649 660 НДС
Что такое MIG простыми словами
MIG — это технология аппаратного разделения поддерживаемых видеокарт NVIDIA. Одна физическая GPU делится на несколько GPU-инстансов. Каждый такой инстанс получает фиксированную часть ресурсов:
- вычислительные блоки;
- видеопамять;
- часть кэша второго уровня;
- часть пропускной способности памяти;
- отдельные пути доступа к памяти;
- набор аппаратных движков, зависящий от профиля.
Для приложения MIG-инстанс выглядит как отдельная видеокарта меньшего размера. Пользователь не получает всю A100, H100 или H200, а работает только с выделенной частью. Официальное описание архитектуры MIG можно посмотреть в NVIDIA MIG User Guide.
Простой пример:
- без MIG один пользователь запускает notebook и занимает всю H100;
- с MIG администратор делит H100 на несколько профилей;
- один профиль получает notebook, второй — inference-сервис, третий — тестовую модель;
- задачи не конкурируют за всю карту сразу, потому что у каждой есть свой выделенный участок GPU.
Это не то же самое, что «дать всем доступ к одной видеокарте и надеяться, что они не помешают друг другу». MIG разделяет ресурсы на уровне самой GPU, поэтому поведение задач становится более предсказуемым.
Где MIG дает больше всего пользы

MIG особенно полезен там, где дорогая видеокарта должна работать не под одну большую задачу, а под несколько сред или сервисов с разными требованиями.
Несколько команд на одной GPU
Внутри компании одна и та же H100 может понадобиться сразу нескольким группам:
- разработчики проверяют новую модель;
- аналитики работают в notebook-среде;
- MLOps-команда тестирует inference;
- инженерная команда отлаживает пайплайн подготовки данных.
Без MIG такая карта часто превращается в спорный ресурс: кто первый занял GPU, тот и работает. Остальные ждут или запускают задачи ночью. С MIG можно заранее выделить каждой команде свой профиль, а не отдавать всю карту целиком.
Это удобно для:
- внутренних ML-платформ;
- исследовательских команд;
- лабораторий;
- сервис-провайдеров;
- компаний, где GPU закупаются централизованно и распределяются между проектами.
Dev/test-окружения
Для разработки почти никогда не нужна вся H100 или H200. На этапе отладки важнее доступность среды, чем максимальная производительность. MIG позволяет выделять небольшие профили под:
- проверку окружения;
- тестовый запуск модели;
- отладку зависимостей;
- проверку совместимости CUDA, драйверов и библиотек;
- подготовку пайплайна перед запуском на полной GPU.
Например, разработчику не обязательно занимать всю A100 80 ГБ, если он проверяет только загрузку модели и корректность обработки входных данных. Ему может хватить небольшого профиля, а остальная часть карты останется доступна другим задачам.
Inference нескольких моделей
Inference — один из самых естественных сценариев для MIG. На одной физической GPU можно держать несколько сервисов:
- разные версии одной модели;
- несколько моделей для разных продуктов;
- отдельные модели для разных клиентов;
- тестовую и production-версию сервиса;
- batch inference с умеренной нагрузкой.
Если каждая модель использует только часть видеопамяти, запускать их на отдельных физических GPU не всегда рационально. MIG позволяет повысить плотность размещения и снизить простой оборудования.
Но важно не выбирать профиль только по объему памяти. У модели может хватать видеопамяти, но не хватать вычислительной части профиля или пропускной способности памяти. Поэтому для inference всегда нужно проверять задержку ответа, размер batch и стабильность под параллельной нагрузкой.
Изоляция клиентов и проектов
MIG помогает разделять GPU между клиентами или проектами так, чтобы одна задача не могла занять всю видеопамять физической карты. Это особенно важно для платформ, где пользователи запускают свои контейнеры, notebook’и или модели.
MIG дает изоляцию на уровне GPU-ресурсов, но не отменяет остальные уровни защиты. Для реальной многопользовательской среды все равно нужны:
- разделение пользователей в операционной системе;
- права доступа к данным;
- контейнерная изоляция;
- сетевые политики;
- ограничения в Kubernetes;
- мониторинг процессов;
- правила очистки зависших задач.
Иначе MIG решит только часть проблемы: разделит видеокарту, но не защитит платформу от ошибок в доступах, секретах, образах контейнеров или сетевой конфигурации.
Что именно делится в MIG
При создании MIG-инстанса администратор выбирает профиль. Профиль определяет, какую часть видеокарты получит задача. Внутри профиля фиксируются вычислительные ресурсы и видеопамять.
Условно это можно представить так: большая GPU разрезается на несколько заранее заданных секций. Маленькая секция подходит для легких задач, крупная — для моделей, которым нужно больше памяти и вычислений.
MIG делит:
- часть вычислительных блоков GPU;
- часть видеопамяти;
- часть кэша L2;
- часть пропускной способности памяти;
- некоторые аппаратные движки;
- видимость устройства для приложений.
Что это означает для пользователя:
- задача не может выйти за пределы выделенного объема видеопамяти;
- соседний инстанс не должен забирать ресурсы у другого инстанса;
- администратор может заранее планировать, кому какой объем GPU доступен;
- поведение нагрузки проще прогнозировать, чем при обычном совместном использовании одной карты.
Но у такого подхода есть оборотная сторона: свободные ресурсы соседнего инстанса не передаются автоматически. Если одной задаче выделили 10 ГБ, а рядом простаивает инстанс на 40 ГБ, первая задача все равно не сможет использовать эти 40 ГБ. Чтобы изменить раскладку, нужно менять MIG-конфигурацию.
Серверы на процессорах AMD EPYC
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 17 049 120 ₽
592 457 ₽/мес в лизинг
от 14 207 600 ₽
+ 2 841 520 НДС
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 8 450 280 ₽
293 647 ₽/мес в лизинг
от 7 041 900 ₽
+ 1 408 380 НДС
 5 лет гарантииБесплатная доставка
5 лет гарантииБесплатная доставкаот 21 103 440 ₽
733 345 ₽/мес в лизинг
от 17 586 200 ₽
+ 3 517 240 НДС
5 лет гарантииБесплатная доставкаот 15 897 960 ₽
552 454 ₽/мес в лизинг
от 13 248 300 ₽
+ 2 649 660 НДС
Что MIG не делает
MIG не превращает одну физическую GPU в несколько полностью независимых видеокарт без ограничений. Это важный момент, потому что неправильные ожидания часто приводят к ошибкам в проектировании.
MIG не означает, что:
- любая задача будет работать быстрее;
- маленький профиль даст ровно 1/7 производительности полной GPU;
- можно бесконечно гибко перераспределять память между задачами;
- несколько MIG-инстансов заменят несколько физических GPU для крупного обучения;
- live migration начнет работать сама по себе;
- мониторинг можно оставить таким же, как для обычной GPU.
NVIDIA отдельно описывает ограничения MIG в разделе Deployment Considerations. Для практического внедрения особенно важны ограничения, связанные с обменом данными между инстансами, профилированием и распределенными библиотеками.
Ограничения для распределенных задач
MIG хорошо подходит для независимых задач на одной физической GPU. Но если нагрузка требует активного обмена данными между несколькими GPU или между инстансами, нужно быть осторожнее.
Проблемными могут быть сценарии, где используются:
- крупное распределенное обучение;
- модели, которые требуют несколько GPU одновременно;
- интенсивный обмен между ускорителями;
- библиотеки коллективных коммуникаций;
- задачи, чувствительные к задержкам между устройствами.
Для таких случаев часто лучше использовать целые физические GPU без MIG. Например, если модель стабильно занимает всю H100 и активно обменивается данными с соседними GPU, разделение карты на MIG-профили может только усложнить архитектуру.
Ограничения по мониторингу
Обычный взгляд на физическую GPU уже недостаточен. Администратору нужно видеть не только общую загрузку карты, но и состояние каждого MIG-инстанса.
Иначе возникает типичная ситуация:
- физическая GPU кажется загруженной неравномерно;
- один MIG-инстанс перегружен;
- другой простаивает;
- третья задача упала по памяти;
- по общей метрике это выглядит как «GPU используется нормально».
Для продакшена желательно собирать метрики по каждому инстансу. NVIDIA DCGM умеет отдавать показатели как на уровне физической GPU, так и на уровне MIG-устройств; это описано в DCGM documentation.
Отслеживать стоит:
- загрузку вычислительных ресурсов;
- занятую видеопамять;
- ошибки памяти;
- температуру;
- энергопотребление;
- throttling;
- падения процессов;
- распределение задач по профилям;
- длительные простои отдельных инстансов.
Профили MIG на A100, H100 и H200

Профиль MIG определяет размер инстанса. В названии профиля обычно есть две части: доля вычислительной части и объем видеопамяти. Например, профиль 1g.10gb означает небольшой инстанс с 10 ГБ видеопамяти, а 7g.80gb — почти вся H100 80 ГБ в одном профиле.
Полный список профилей лучше проверять в официальной таблице Supported MIG Profiles, потому что доступные варианты зависят от конкретной модели GPU, объема памяти, форм-фактора и версии драйвера.
| GPU | Примеры профилей MIG | Максимум инстансов | Для каких задач подходит |
|---|---|---|---|
| A100 40 ГБ | 1g.5gb, 2g.10gb, 3g.20gb, 4g.20gb, 7g.40gb | до 7 | небольшие модели, тесты, notebook’и, легкий inference |
| A100 80 ГБ | 1g.10gb, 1g.20gb, 2g.20gb, 3g.40gb, 4g.40gb, 7g.80gb | до 7 | несколько команд, inference, batch-задачи, средние эксперименты |
| H100 80 ГБ | 1g.10gb, 1g.20gb, 2g.20gb, 3g.40gb, 4g.40gb, 7g.80gb | до 7 | production inference, тесты LLM, несколько сервисов на одной GPU |
| H100 94/96 ГБ | 1g.12gb, 1g.24gb, 2g.24gb, 3g.47/48gb, 4g.47/48gb, полный профиль | до 7 | задачи, которым мало 80 ГБ, но не всегда нужна вся карта |
| H200 141 ГБ | 1g.18gb, 1g.35gb, 2g.35gb, 3g.71gb, 4g.71gb, 7g.141gb | до 7 | крупный inference, memory-heavy задачи, несколько тяжелых моделей |
Цифры в названии профиля не нужно воспринимать как точный прогноз производительности. Профиль показывает размер выделенной части GPU, но реальная скорость зависит от модели, batch size, типа вычислений, памяти, библиотек и того, насколько хорошо задача масштабируется.
Как выбрать профиль под задачу
Выбор профиля начинается не с вопроса «сколько инстансов можно создать», а с вопроса «что именно будет работать на каждом инстансе». Для одной и той же GPU можно собрать разные схемы: много маленьких профилей, несколько средних или один крупный.
Небольшая модель или тестовый сервис
Для небольшой модели обычно стоит начать с 1g-профиля. Такой вариант подходит, если задача:
- использует мало видеопамяти;
- не требует высокой пропускной способности;
- обслуживает умеренное число запросов;
- нужна для тестов или разработки;
- запускается как отдельный сервис.
На A100 80 ГБ это может быть профиль 1g.10gb. На H200 141 ГБ — 1g.18gb. Разница важна: на H200 даже минимальный профиль дает заметно больше памяти, поэтому ее удобнее делить между более тяжелыми задачами.
Notebook для разработчика или аналитика
Notebook-среды часто занимают GPU неэффективно. Пользователь может открыть сессию, загрузить модель, запустить несколько ячеек и оставить процесс висеть на несколько часов. Если ему выдать целую H100, карта будет формально занята, хотя реально используется частично.
Для notebook’ов обычно подходят:
- 1g-профили для легких экспериментов;
- 2g-профили для задач с большим batch;
- ограничение времени сессии;
- автоматическая очистка простаивающих процессов;
- отдельные лимиты для разных групп пользователей.
MIG здесь помогает не столько ускорить вычисления, сколько сделать доступ к GPU более справедливым.
Batch inference
Для batch inference нужно смотреть не только на память, но и на задержку обработки. Маленький профиль может поместить модель, но не выдержать нужную скорость.
Перед выбором профиля стоит проверить:
- максимальный размер batch;
- среднюю и пиковую задержку;
- загрузку вычислительной части;
- загрузку памяти;
- поведение под параллельными запросами;
- запас на рост нагрузки.
Если сервис обслуживает небольшую модель, можно начать с 1g или 2g. Если batch крупный или модель тяжелее, лучше тестировать 3g или 4g. Для задач, где важен большой объем видеопамяти, интереснее смотреть в сторону H200.
Fine-tuning
Для fine-tuning маленькие профили подходят не всегда. Даже если модель стартует, она может упасть на следующем этапе из-за пикового потребления памяти. Особенно это заметно при увеличении batch size, длины контекста или использовании менее экономных настроек обучения.
Для fine-tuning чаще нужны:
- 3g или 4g-профили;
- полный профиль, если модель крупная;
- отдельная физическая GPU, если задача стабильно использует всю карту;
- предварительный тест на пиковое потребление памяти.
Если задача связана с серьезной донастройкой LLM, не стоит начинать с минимального профиля. Лучше сначала измерить потребление на тестовом запуске, а уже потом решать, можно ли делить карту.
Примеры распределения одной GPU между задачами

MIG удобнее всего понимать через конкретные схемы. Ниже — не универсальные рецепты, а типовые варианты, от которых можно отталкиваться при проектировании.
A100 80 ГБ для команды разработки
NVIDIА A100 80Gb PCIE HBM2 OEM можно использовать как общую карту для нескольких внутренних задач.
Пример раскладки:
- 2 × 1g.10gb — notebook’и для разработчиков;
- 1 × 2g.20gb — тестовый inference;
- 1 × 3g.40gb — эксперимент с более крупной моделью.
Такая схема подходит, когда команде нужно не максимальное ускорение одной задачи, а постоянный доступ к нескольким изолированным средам. Если в какой-то период нужен более крупный эксперимент, конфигурацию можно пересобрать и временно отдать больше ресурсов одной задаче.
H100 80 ГБ для нескольких inference-сервисов
NVIDIA H100 80Gb HBM3 OEM чаще выбирают для более производительных AI-нагрузок. В MIG-сценарии она хорошо подходит для нескольких inference-сервисов.
Возможная схема:
- несколько 1g или 2g-профилей для небольших моделей;
- один 3g или 4g-профиль для более тяжелого сервиса;
- отдельный маленький профиль для тестирования новой версии модели.
Здесь важно не перегружать карту случайными профилями. Лучше заранее определить классы сервисов: маленький, средний, тяжелый. Тогда командам проще запрашивать ресурсы, а администраторам — отслеживать загрузку.
H200 141 ГБ для задач, которым важна видеопамять
NVIDIA H200 ORIGINAL интересна там, где ограничением становится не только вычислительная мощность, но и объем видеопамяти. У H200 MIG-профили крупнее: даже небольшой профиль дает 18 ГБ, а средние профили могут давать 35 или 71 ГБ.
Такую карту можно делить между:
- несколькими inference-сервисами с заметным потреблением памяти;
- batch-задачами;
- тестами моделей, которым мало 10–20 ГБ;
- несколькими командами, работающими с более тяжелыми пайплайнами.
Если модель требует почти весь объем H200, MIG уже не нужен: лучше использовать полный профиль или всю физическую GPU.
Что проверить перед внедрением MIG
Перед внедрением MIG важно проверить не только саму видеокарту, но и весь стек: драйвер, контейнеры, Kubernetes, мониторинг, правила доступа и сценарии пересоздания профилей.
| Что проверить | Почему это важно |
|---|---|
| Совместимость GPU | MIG поддерживают не все видеокарты NVIDIA. A100, H100 и H200 подходят, но конкретную модель и форм-фактор нужно проверять отдельно |
| Версию драйвера | Старые версии могут не поддерживать нужные профили или корректную работу с современным стеком |
| CUDA и библиотеки | Приложение должно видеть MIG-инстанс как доступную GPU и корректно запускаться на ограниченном профиле |
| nvidia-smi | Нужно убедиться, что MIG включается, профили создаются и отображаются в системе |
| Kubernetes device plugin | Нужен, если MIG-инстансы будут выдаваться контейнерам в Kubernetes |
| GPU Operator и MIG Manager | Упрощают управление GPU-стеком и MIG-конфигурациями на узлах |
| Мониторинг | Нужны метрики по каждому инстансу, а не только по физической GPU |
| Правила аллокации | Пользователи должны понимать, какой профиль им нужен и почему |
| Политику изменения профилей | Пересборка схемы MIG может потребовать остановки задач |
| План отказоустойчивости | MIG делит GPU, но не заменяет резервирование сервиса |
Особое внимание стоит уделить правилам аллокации. Если их нет, MIG быстро превращается в набор случайно созданных профилей: один пользователь просит слишком большой инстанс, другой занимает маленький профиль под тяжелую модель, третий оставляет сессию висеть на выходные.
Хорошая практика — заранее описать несколько стандартных классов:
- малый профиль для notebook’ов и тестов;
- средний профиль для inference;
- крупный профиль для тяжелых экспериментов;
- полный профиль для задач, которым действительно нужна вся карта.
MIG в Kubernetes
Пример архитектуры масштабирования Triton Inference Server с MIG и Kubernetes. Источник: NVIDIA Developer Blog
В Kubernetes MIG особенно полезен, потому что позволяет выдавать не всю физическую GPU, а конкретный профиль под конкретный pod. Для этого нужен дополнительный NVIDIA-стек: драйверы, container toolkit, device plugin, а в более управляемых установках — GPU Operator.
NVIDIA описывает MIG-сценарии для Kubernetes в отдельной документации: MIG Support in Kubernetes. На практике это выглядит так:
- администратор включает MIG на GPU-узле;
- создает нужные профили;
- Kubernetes получает список доступных MIG-ресурсов;
- pod запрашивает конкретный тип ресурса;
- scheduler размещает нагрузку на узле, где такой профиль есть.
В Kubernetes особенно важно не создавать хаос из слишком большого числа профилей. Чем больше вариантов, тем сложнее планировщику размещать задачи, а командам — выбирать правильный ресурс.
Для ML-платформ обычно полезны такие правила:
- подписывать GPU-узлы по типу доступных профилей;
- заводить отдельные очереди для малых, средних и крупных задач;
- ограничивать доступ к полным GPU;
- автоматически завершать простаивающие notebook-сессии;
- собирать статистику использования по профилям;
- регулярно пересматривать, какие профили реально нужны.
MIG хорошо сочетается с Kubernetes, когда задачи заранее классифицированы. Если каждая команда вручную просит «что-нибудь побольше», преимущества быстро теряются.
Когда лучше не использовать MIG
MIG не нужен в каждом GPU-сервере. Иногда разделение карты только усложняет эксплуатацию.
Лучше использовать целую физическую GPU или несколько GPU без MIG, если:
- одна задача стабильно использует всю видеокарту;
- модель требует почти весь объем видеопамяти;
- нужна максимальная производительность одной задачи;
- обучение распределяется на несколько GPU;
- нагрузка активно обменивается данными между ускорителями;
- приложение плохо работает на ограниченном профиле;
- требуется гибкое перераспределение памяти между задачами;
- инфраструктура не готова к мониторингу MIG-инстансов;
- нет администратора, который будет управлять профилями и правилами доступа.
MIG особенно хорошо работает там, где нагрузки похожи и предсказуемы. Например, если у вас есть несколько типовых inference-сервисов, несколько notebook-сред и понятные лимиты для команд. Если же каждый запуск уникален, а потребление памяти сложно предсказать, придется чаще менять профили и останавливать задачи.
A100, H100 или H200: что выбрать под MIG

Источник: ServerMall
Выбор зависит от того, какие задачи нужно запускать и насколько важна видеопамять.
A100
A100 — зрелая и распространенная платформа. Она хорошо подходит для:
- внутренних ML-сред;
- dev/test;
- нескольких notebook’ов;
- inference небольших и средних моделей;
- команд, которым нужен доступ к GPU без бюджета на топовые H100/H200.
Если планируется активное разделение между пользователями, A100 80 ГБ удобнее версии на 40 ГБ: больше вариантов по памяти и меньше риск, что каждая задача быстро упрется в лимит.
H100
H100 стоит рассматривать, если нужна более высокая производительность для современных AI-нагрузок. В MIG-сценариях она подходит для:
- production inference;
- нескольких сервисов на одной GPU;
- тестирования LLM;
- ML-платформ с разными классами задач;
- команд, которым важен запас по скорости.
H100 может быть избыточной для мелких задач. Именно поэтому MIG здесь особенно полезен: он помогает не отдавать всю мощную карту одному небольшому процессу.
H200
H200 интересна, когда главная проблема — видеопамять и пропускная способность памяти. Профили H200 крупнее, поэтому карта хорошо подходит для более тяжелых inference-сценариев и задач, которым мало типовых 10–20 ГБ.
H200 стоит рассматривать, если:
- модели часто упираются в память;
- нужно держать несколько тяжелых сервисов;
- batch inference требует большого запаса;
- одна задача не всегда использует весь объем 141 ГБ;
- хочется делить карту, но не уходить в слишком маленькие профили.
Если задача одна и ей постоянно нужна вся H200, разделение не даст преимущества. Но если таких задач несколько и каждая требует только часть карты, MIG помогает использовать ресурс плотнее.
Частые ошибки при работе с MIG

Ошибки обычно связаны не с самой технологией, а с ожиданиями и эксплуатацией.
Чаще всего встречаются такие проблемы:
- профиль выбирают только по объему видеопамяти;
- не проверяют пиковое потребление модели;
- не измеряют задержку inference под нагрузкой;
- выдают слишком крупные профили «на всякий случай»;
- запускают fine-tuning на слишком маленьком инстансе;
- не собирают метрики по каждому MIG-инстансу;
- забывают, что свободная память соседнего профиля не передается автоматически;
- не документируют, кому и зачем выделен профиль;
- смешивают слишком много конфигураций на одном узле;
- считают MIG заменой нескольким физическим GPU;
- не планируют остановку задач перед изменением схемы.
Чтобы избежать этих ошибок, MIG лучше внедрять не как разовую настройку, а как управляемую политику использования GPU.
Минимальный набор правил:
- Описать типовые профили и сценарии.
- Проверить реальные нагрузки на тестовом стенде.
- Настроить мониторинг по инстансам.
- Ограничить доступ к полным GPU.
- Ввести правила очистки простаивающих процессов.
- Пересматривать конфигурации по статистике использования.
Как понять, окупится ли MIG
MIG имеет смысл, если одна дорогая GPU часто простаивает или занята задачами, которым не нужна вся карта. Особенно это заметно в командах, где много тестов, notebook’ов, небольших моделей и inference-сервисов.
MIG будет полезен, если:
- несколько пользователей регулярно конкурируют за одну GPU;
- задачи предсказуемы по памяти;
- есть много небольших inference-сервисов;
- нужно изолировать клиентов или команды;
- GPU часто занята, но фактически загружена не полностью;
- инфраструктура уже использует Kubernetes или планирует к нему перейти;
- есть администратор, который будет управлять профилями.
MIG может быть лишним, если:
- вся GPU почти всегда занята одной большой задачей;
- модели постоянно требуют полный объем памяти;
- нет мониторинга;
- нет понятных правил распределения;
- команда не готова менять процессы работы с GPU.
В итоге MIG стоит рассматривать не как способ ускорить A100, H100 или H200, а как способ сделать их использование более управляемым. Он помогает делить дорогую видеокарту между несколькими задачами, снижает конфликты за ресурсы и повышает утилизацию оборудования. Но для хорошего результата нужны правильные профили, мониторинг и понимание ограничений. Без этого MIG легко превратить в еще один сложный слой инфраструктуры, который никто не контролирует.








